Download

1 / 33
330 likes | 349 Views
Delve into the world of gene finding and translation, exploring topics such as the genetic code, ORF identification, codon preferences, gene structure, RNA transcription, splicing, and gene prediction programs in prokaryotes and eukaryotes. Discover the intricacies of the central dogma and how it guides the process of protein synthesis.

E N D
Transcription Translation Protein RNA “The Central Dogma”
Reminder: The Genetic Code 1 start, 3 stop Codons
Finding Genes in Prokaryotes • Gene structure • High gene density • ~85% coding in E.coli • => is every ORF a gene?
Finding ORFs • Many more ORFs than genes • In E.Coli one finds 6500 ORFs while there are 4290 genes. • In random DNA, one stop codon every 64/3=21 codons on average. • Average protein is ~300 codons long. • => search long ORFs. • Problems: • Short genes • Overlapping long ORFs on opposite strands
Codon Frequencies • Coding DNA is not random: • In random DNA, expect Leu : Ala : Trp ratio of 6 : 4 : 1 • In real proteins, 6.9 : 6.5 : 1 • Different frequencies for different species.
Using Codon Frequencies/Usage • Assume each codon is independent. • For codon abc calculate frequency f(abc) in coding region. • Given coding sequence a1b1c1,…, an+1bn+1cn+1 • Calculate • The probability that the ith reading frame is the coding region:
CodonPreference ORF The real genes
C+G Content • C+G content (“isochore”) has strong effect on gene density, gene length etc. • < 43% C+G : 62% of genome, 34% of genes • >57% C+G : 3-5% of genome, 28% of genes • Gene density in C+G rich regions is 5 times higher than moderate C+G regions and 10 times higher than rich A+T regions • Amount of intronic DNA is 3 times higher for A+T rich regions. (Both intron length and number). • Etc…
RNA Transcription • Not all ORFs are expressed. • Transcription depends on regulatory regions. • Common regulatory region – the promoter • RNA polymerase binds tightly to a specific DNA sequence in the promoter called the binding site.
Prokaryotic Promoter • One type of RNA polymerase.
Positional Weight Matrix • For TATA box:
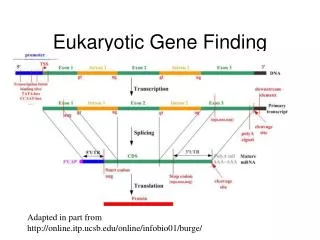
Eukaryote gene structure • Gene length: 30kb, coding region: 1-2kb • Binding site: ~6bp; ~30bp upstream of TSS • Average of 6 exons, 150bp long • Huge variance: - dystrophin: 2.4Mb long • Blood coagulation factor: 26 exons, 69bp to 3106bp; intron 22 contains another unrelated gene
Splicing • Splicing: the removal of the introns. • Performed by complexes called spliceosomes, containing both proteins and snRNA. • The snRNA recognizes the splice sites through RNA-RNA base-pairing • Recognition must be precise: a 1nt error can shift the reading frame making nonsense of its message. • Many genes have alternative splicing which changes the protein created.
Frame +1 Frame+2 Frame +3 Gene prediction programs Scan the sequence in all 6 reading frames: • Start and stop codons • Long ORF • Codon usage • GC content • Gene features: promotor, terminator, poly A sites, exons and introns, …
Gene prediction programs Genscan: • Vertebrates/Maize/Arbidopsis. • Predict location and gene features. • Can handle few genes in one sequence
Gene prediction programs • Results:
GenScan Performance • Predicts correctly 80% of exons • With multiple exons probability declines… • Prediction per bp > 90%
Many prediction Tools • Dynamic programming to make the high scoring model from available features. • e.g. Genefinder • Markov model based on a typical gene model. • e.g. GENSCAN or GLIMMER • Neural net trained with confirmed gene models. • e.g. GRAIL
An end to ab initio prediction • ab initio gene prediction is inaccurate. • High false positive rates for most predictors. • Rarely used as a final product • Human annotation runs multiple algorithms and scores exon predicted by multiple predictors. • Used as a starting point for refinement/verification
Comparative Genomics Use homologue sequences: • Annotated genes. • mRNA sequences. • Proteins sequences • ESTs
ESTs EST – Expressed Sequence Tags. Short sequences which are obtained from cDNA (mRNA).
Gene Model: EST cDNA Transcript-based prediction Align transcript data to genomic sequence using a pair-wise sequence comparison.
Transcript-based prediction Example: BlastN against a ESTs/human database.
Annotation of eukaryotic genomes Genomic DNA ab initio gene prediction(w/o prior knowledge) transcription Unprocessed RNA RNA processing Comparative gene prediction (use other biological data) AAAAAAA Gm3 Mature mRNA translation Nascent polypeptide folding Active enzyme Functional identification Function Reactant A Product B