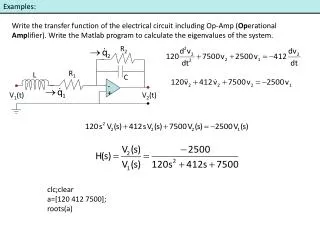
Download
1 / 18
180 likes | 303 Views
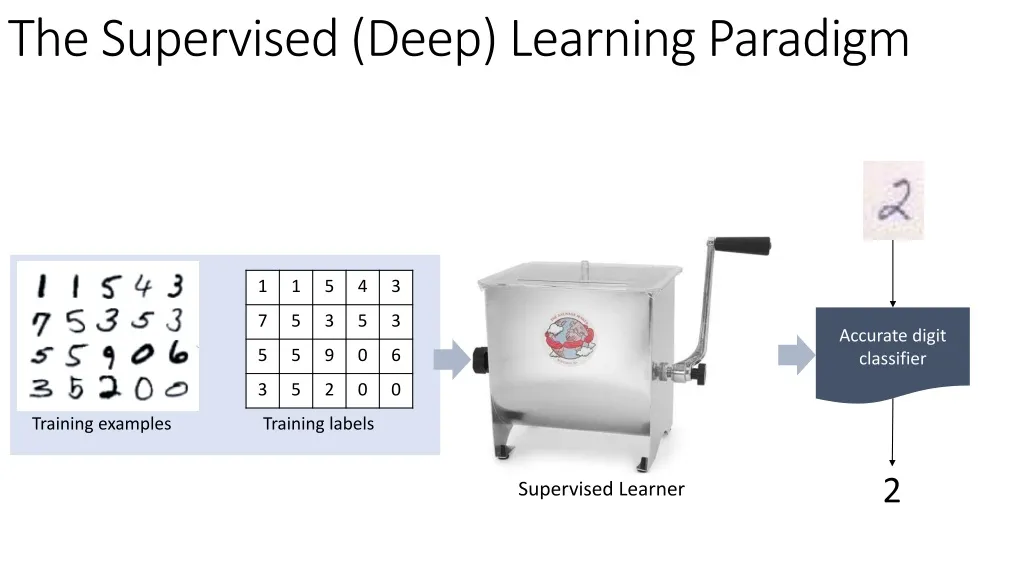
The Supervised (Deep) Learning Paradigm. Training examples. Accurate digit classifier. Training labels. 2. Supervised Learner. Supervised Learning is cool. A supervised problem is solved if:. A human can tell you the right answer many times. (1000 penguins…).

E N D
The Supervised (Deep) Learning Paradigm Training examples Accurate digit classifier Training labels 2 Supervised Learner
A supervised problem is solved if: A human can tell you the right answer many times. (1000 penguins…) a tool to teach machines known things
How about news? Repeatedly: • Observe features of user+articles • Choose a news article. • Observe click-or-not Goal: Maximize fraction of clicks
A standard pipeline • Learn • Act: • Deploy in A/B test for 2 weeks • A/B test fails Why?
Q: What goes wrong? Is Ukraine interesting to John ? A: Need Right Signal for Right Answer
Q: What goes wrong? Model value over time A: The world changes!
BAD How do you learn from Reward signal?
Reinforcement Learning (selected news story) Action Policy ? (user history, news stories) Observation (click-or-not) Reward My papers: KL02, KKL03, SLWLL06, DaLM09, CKADaL15, CHRDaL16, KAL16, JKALS17, MLA17, DaLMS18…
A simple problem breaking all common multistep RL algorithms So Cold! A boy’s fire starts to die down The boy is warm for awhile So he goes searching for wood But he gets cold far from the fire But then the fire goes out So he returns to the fire steps to solution samples needed
Consider: One-step Reinforcement Learning Limit the scope of the problems solved
One step reinforcement learning is used! LZ07, BL09, LWLS10, SLLK10, DuLL11, DuHKKLRZ11, LWLW11, BLLRS, ADuKLS12, DELL12, BLS14, AHKLLS14, ABCLLLMORSS16, AKADuL17… News Rec: [LCLS ‘10] Ad Choice: [BPQCCPRSS ‘12] Ad Format: [TRSA ‘13] Education: [MLLBP ‘14] Music Rec: [WWHW ‘14] Robotics: [PG ‘16] Wellness/Health: [ZKZ ’09, SLLSPM ’11, NSTWCSM ’14, PGCRRH ’14, NHS ’15, KHSBATM ‘15, HFKMTY ’16] Tutorial @http://hunch.net/~rwil
Algorithms in Vowpal Wabbit: Email us (jcl@microsoft.com) if you want to play with a service…
Reinforcement problem solved if: An action outcome value can be measuredmany times. can learn new things about the world
Much still to do---Join us Nan Jiang Sham Kakade Satyen Kale Nikos Karampatziakis Akshay Krishnamurthy Lihong Li Stephane Ross Robert Schapire Wen Sun Tong Zhang Alekh Agarwal Alina Beygelzimer Drew Bagnell Avrim Blum Kai-Wei Chang Christoph Dann Hal Daume Simon Du Miroslav Dudik Geoff Gordon Daniel Hsu Yes, we are hiring http://hunch.net/?p=9828091