Download

1 / 20
200 likes | 403 Views
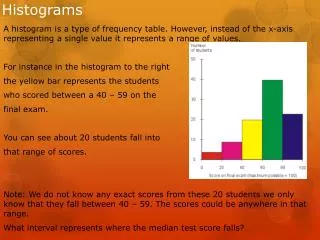
Self-tuning Histograms Building Histograms Without Looking at Data . By Ashraf Aboulnage & Surajit Chaudhuri Represents By Miller Ofer. Traditional histograms. Histograms impose little cost at queries , especially in a large data base.

E N D
Self-tuning HistogramsBuilding Histograms Without Looking at Data By Ashraf Aboulnage & Surajit Chaudhuri Represents By Miller Ofer
Traditional histograms • Histograms impose little cost at queries , especially in a large data base. • The cost of building histograms from database is significant high and prevent us from building useful histograms . • Data modification causes to lost of histogram accuracy .
Self-Tuning histogram : • Similar in structure to traditional histogram. • Builds without looking or sampling the data. • Uses “free” information from the queries results. • Can be refined in an on-line mode ( The overall cost of building self tuning histogram is very low). • Their accuracy depends on how often they are used, the more it is use , the more it is refined , the more accurate it becomes
The main steps in building the ST-histogram : • Initial the histogram. • Refining the bucket values (frequencies). • Restructuring – moving the buckets boundaries.
Initial The Histogram : • Data requirement : • B Number of histogram buckets • T Number of tuples • Min/max min and max values of attribute . • Assuming uniformity of the data distribution and initial each of the buckets as T/b tuples.
ST-histogram after initialization tuples frequency buckets
The Algorithm for refining the buckets frequencies. (second step ) begin • Finds set of k buckets that overlapping the selection range . • Let estbe the estimated results size of the selection range using histogram h . • Let act be the actual result size. • Compute the estimation error by act-est , denote by esterr . •
last overlapbucket 5. for i = 1 to k do 8. endfor end UpdateFreq proportion average assumption
Refinement example : act = 60 rangehigh = 25 Rangelow = 12.5 high(b1) = 15 low(b1) = 5 35 0.5 5/25
Restructuring Algorithm : • Motivation : • Frequencies are approximated by their average. Thus , high frequent value will be contain in high frequent buckets , but they may be grouped with low frequency values . • When the range of query adapts to the range of histogram bucket , no average assumption is needed.
Restructuring Algorithm : Merging step • For every consecutive runs of buckets , find the maximum differences in frequency between a bucket in the first run and the buckets in the second run. • Find the minimum of all these maximum difference , denote by mindiff. • if mindiff < m*T then Merge the two runs of buckets corresponding to mindiff into one run. Look for other runs to merge .goto line 1. endif
Restructuring Algorithm : Splitting step • k=s*b ; b – the rest of the buckets that haven’t been chosen . • Find the set with k highest frequency . • Compute the splitting extra bucket of each one by : • split(bi) = where totalfreq is the sum of all the bucket to be split and B is the number of extra bucks 8. Each buckets freq gets the old freq divided to split(bi)+1.
Restructuring example : m*T 3 S*B 2 merge1 merge2 split split 10 13 17 14 13 11 25 70 10 30 10 1 2 3 4 5 6 7 8 9 23 17 38 25 23 23 24 10 15 15 10 1 2 3 4 5 7 8 9 6
Multi-dimensional ST-histogram • Initialization : • Assuming a complete uniformity and independence. • Using existing one-dimensional ST-histograms assuming independence of the attribute .
Multi-dimensional Refining the buckets frequencies : • The refining algorithm for multi-dimensional is identical to the algorithm for one-dimensional except the two following changes : • Finding the overlap selected range, now require examining a multi-dimensional structure. • The fraction of a bucket overlapping the selection range is now equal to the volume of the region divided by the volume of the region represented by the whole bucket.
Multi-dimensional Restructuring • Merge – find the max difference in freq between any two corresponding buckets of the same line, merge if the difference within m*t . ( m<1% ). • Split – the frequency of partition ji in dimension i is compute by : Max S = 50 Max diff = 4 Max S = 60
Accuracy of ST-histogram Due to the same memory limit and the complex of MHIST-2, st-histogram have more buckets.
Adapting to Database Updates R1 – relation before update with skew =1 . R2 - Update the relation by deleting 25% of it’s tuple and inserting an equal number of tuples.
Conclusions : • Better than assuming uniformity and independence for all values of data skew (z). • Forlowdata skew the st-histograms found to be sufficient accurate comparing to the traditional histograms. • Attractive for multi-dimensional histogram since the high cost of building them . • For high data skew, st-hist much less accurate than “Mhist-2” . • Combination between traditional hist and st-hist for all the range of data skew can yield the best of each concept .