Download
1 / 10
100 likes | 398 Views
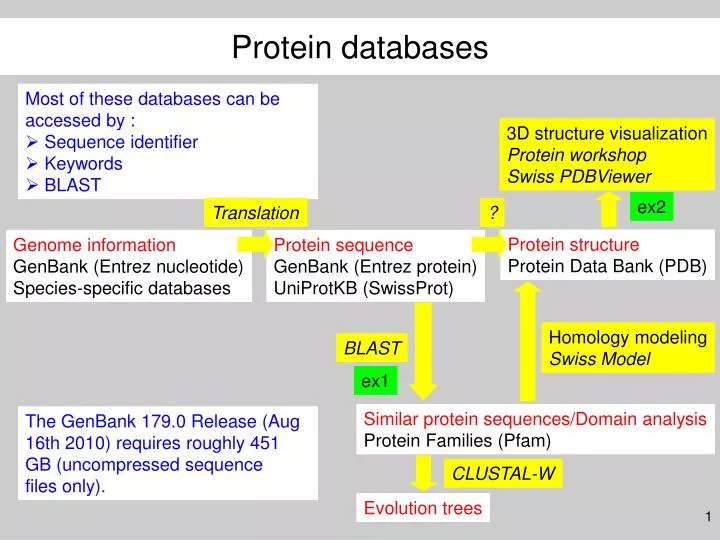
Protein databases. Most of these databases can be accessed by : Sequence identifier Keywords BLAST. 3D structure visualization Protein workshop Swiss PDBViewer. ex2. Translation. ?. Protein structure Protein Data Bank (PDB). Genome information GenBank (Entrez nucleotide)

E N D
Protein databases • Most of these databases can be accessed by : • Sequence identifier • Keywords • BLAST 3D structure visualization Protein workshop Swiss PDBViewer ex2 Translation ? Protein structure Protein Data Bank (PDB) Genome information GenBank (Entrez nucleotide) Species-specific databases Protein sequence GenBank (Entrez protein) UniProtKB (SwissProt) Homology modeling Swiss Model BLAST ex1 Similar protein sequences/Domain analysis Protein Families (Pfam) The GenBank 179.0 Release (Aug 16th 2010) requires roughly 451 GB (uncompressed sequence files only). CLUSTAL-W Evolution trees
Smith-Waterman algorithm Substitution matrix BLOSUM = Block Substitution Matrix PAM : Point/Percent accepted mutation Gap insertion penalty Gap extension penalty find all segment pairs whose scores can not be improved by extension or trimming BLAST : basic local alignment search tool query : CGNLSTCMLGTYTQDFNKF-----HTFPQTAIGVGAP | .||. :.: : : :..| :| : match : KCNTATCATQRLANFLVHSSNNFGAILSSTNVGSNTY protein sequence database or Sbjct or hit cutoff High-Scoring Element Pairs (HSP) scores E-value P-value Multiple alignment : ClustalW Altschul SF et al. Basic Local Alignment Search Tool. J Mol Biol. 1990; 215: 403–410.
Alignment score matrices Example of BLOSUM 62 : set of ‘trusted’ aligned protein sequences select pairs of sequences with less than 62% identity calculate probability frequency pa,b where fx is the occurrence probability of amino acid x BLOSUM80 : more conserved sequences BLOSUM40 : more divergent sequences Sean R Eddy 2004, Nature Biotechnology 22 :1035-6
Evaluation of the similarity : E- and P-value m : query size n : database size S : score E-value : the expected number of HSPs with score at least S is E = K m n e-S where K and depends on the database statistics (amino acid frequencies) and on the scoring system. K and are estimated from the score distribution. Example of score distribution fitted with the E-distribution P-value : the probability that the score S from the comparison of two unrelated sequences is at least x is P(S ≥ x) = 1 - e-E(x) For small E-values, P ≈ E P- score distribution of the same data Bit-scores : normalized E-values. E = m n 2-S’
Practical BLAST The different BLAST programs : Program Database Query BLASTN nucleotide nucleotide BLASTP protein protein BLASTX protein translated nucleotide TBLASTN translated nucleotide protein TBLASTX translated nucleotide translated nucleotide Databases : Species-specific genomes (not curated) : choose one or more species or group at http://www.ncbi.nlm.nih.gov/mapview/ Protein database (curated) : http://www.uniprot.org/ Parameters : Cutoff E ≤ 0.01 : conservative search Cutoff E ≤ 1 : weak homologies Gap penalties : gap-open, gap-extend ... Let them as they are, to start with ! Filter repetitive sequences : Yes ! PSI-BLAST : an iterative BLAST program, to find distantly related proteins
More information GenBank, Pubmed, Entrez The NCBI handbook http://www.ncbi.nlm.nih.gov/ More on bioinformatics Bioinformatics for Human Biologists - course programme, winter 2009 http://www.cbs.dtu.dk/courses/humanbio/2009/programme.php Expasy UniProtKB protein database Protein analysis tools, Swiss-PDB Viewer, Swiss-Model http://expasy.org/ Protein DataBank Protein 3D structure, Protein workshop http://www.pdb.org/pdb/home/home.do Protein families (Pfam) http://pfam.sanger.ac.uk/
Example : calcitonin sequence Expasy UniProtKB ‘human calcitonin’ P01258 (CALC_HUMAN) Retrieve calcitonin peptide sequence in FASTA format : >P01258|85-116 CGNLSTCMLGTYTQDFNKFHTFPQTAIGVGAP
Graphical overview of BLAST results The query sequence is represented by the numbered red bar at the top of the figure. Database hits are shown aligned to the query, below the red bar. Of the aligned sequences, the most similar are shown closest to the query. In this case, there are three high-scoring database matches that align to most of the query sequence. The next twelve bars represent lower-scoring matches that align to two regions of the query, from about residues 3–60 and residues 220–500. The cross-hatched parts of the these bars indicate that the two regions of similarity are on the same protein, but that this intervening region does not match. The remaining bars show lower-scoring alignments. Mousing over the bars displays the definition line for that sequence to be shown in the window above the graphic. The NCBI handbook, The BLAST Sequence Analysis Tool, Tom Madden
The UniProtKB database A curated database : SwissProt A Bairoch et al. An automated database : TrEMBL Organism distribution Sequence length distribution H sapiens : 0.6% Release 2010_09 of 10-Aug-2010