Download
1 / 11
120 likes | 439 Views
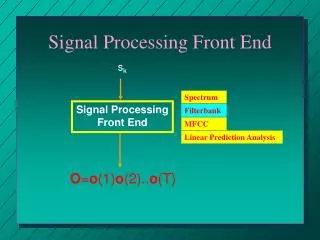
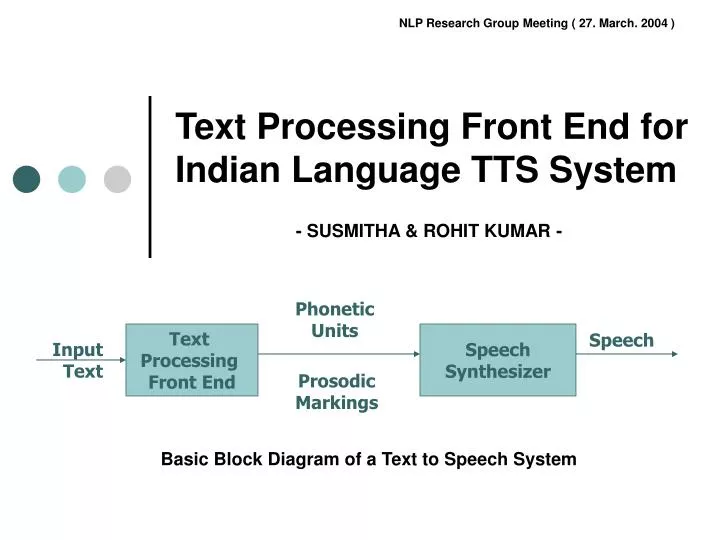
Phonetic Units. Text Processing Front End. Speech Synthesizer. Speech. Input Text. Prosodic Markings. Text Processing Front End for Indian Language TTS System. - SUSMITHA & ROHIT KUMAR -. Basic Block Diagram of a Text to Speech System. Font Text. Converter. Unicodes. Text

E N D
Phonetic Units Text Processing Front End Speech Synthesizer Speech Input Text Prosodic Markings Text Processing Front End for Indian Language TTS System - SUSMITHA & ROHIT KUMAR - Basic Block Diagram of a Text to Speech System
Font Text Converter Unicodes Text Normalization Normalized Unicodes Unicode to WX WX NLP Modules Expands Non Standard Words to Standard Words Phonetizer • Throughout all these conversions • Indexing is maintained Phonetic Unit Sequences & Prosodic Markings Text Processing Front End for Indian Language TTS System Basic Design
Font_ID Unicode2String String2Unicode GetIndexes Text Processing Front End for Indian Language TTS System Converters Base Class IIITH_Converter Virtual Public Public IIITH_AmarUjala IIITH_Bhaskar IIITH_Vartha …………… Derived Classes (one for each converter) List of Fonts Currently Handled AmarUjala Bhaskar Jagran Naidunia Shusha Shashi Yogesh Eenadu Vartha Hemalatha WLHemalatha ISCII UTF8 WX
Text Processing Front End for Indian Language TTS System Converters (continued..) Mapping Table Index Creation Specialized Blocks Index Adjustment Movement Blocks Deletion Blocks Substitution Blocks
Text Processing Front End for Indian Language TTS System Converters (continued..) IIITH_Converter string vector <int> vector <IIITH_Index> vector <IIITH_Index> Notation1_Index Notation2_index • No temporary files, no junk, no system calls, very portable, etc. • Simple, Easy to use, Pluggable modules (we used them frequently for InXight work & also for PICOPETA) • Also Unicode to UTF8 Converter has been developed is being used in Web Content Unifier
Text Processing Front End for Indian Language TTS System Indexing Example
Text Processing Front End for Indian Language TTS System Text Normalization • Filter • Text Normalization Types of Token Handled • Numbers (11.221) • Abbreviations (Mr. , Dr.) • Punctuations (+,-) • Normal Words Unicodes Indexes Tokenizer Token Identifier Unicodes Updated Indexes Token Expansion
Text Processing Front End for Indian Language TTS System Text Normalization (continued…) IIITH_TextNormalization Unicodes Indexes vector <int> Unicodes Updated Indexes vector <int> NormalizeText • Most of Normalization Operations are language independent. • The language dependent things (e.g. number tables, abbreviations, etc.) are kept in separate file in a standard path and the Text Normalization module loads the appropriate file depending upon the Language ID provided to it • Quite easy to extend to new Indian Languages • Allows continuous Improvements with evaluations
Text Processing Front End for Indian Language TTS System NLP Modules Base Class IIITH_NLPModule Virtual Process GetIndex Public Public Derived Classes IIITH_HindiIVS IIITH_Wx2Z WX Indexes string WX (or Z) Updated Indexes string Process
Text Processing Front End for Indian Language TTS System NLP Modules (continued..) Currently deployed NLP Modules Hindi IIITH_HindiIVS LangID ? Telugu WX Lang ID Z IIITH_Wx2Z NLP Modules to be developed / deployed • Borrowed / Foreign Words handling • Clause Boundary
Text Processing Front End for Indian Language TTS System Moving Further… • Currently the Phonetizer is a part of the synthesis engine • Bringing Phonetizer & Syllabifier modules outside the core engine because we can use these modules for several other purposes also • Modifying the Synthesis engine to support new phonetizer and Indexing • Thorough Testing and Evaluation of TN Modules & continous improvements • Developing a proper API (LIBs and DLLs) for using these • Integration of new modules with LMDS (for PICOPETA) & with RAVI • Experimenting with Prosodic Marking (better pauses for a start)