Download
1 / 1
10 likes | 91 Views
REC. VM. Spanish. US-English. Catalan. Speech time. 31h:7m:32s. 23h:43m:55s. Abstract. #speakers. 77. 56.

E N D
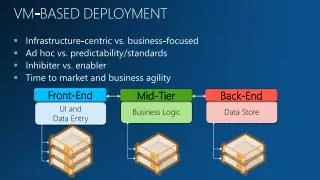
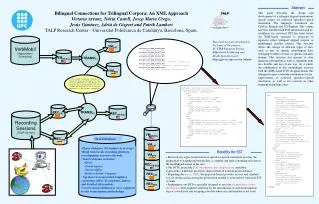
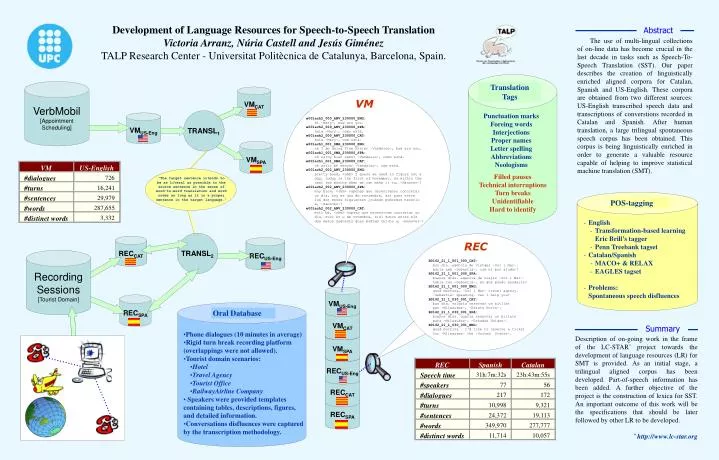
REC VM Spanish US-English Catalan Speech time 31h:7m:32s 23h:43m:55s Abstract #speakers 77 56 The use of multi-lingual collections of on-line data has become crucial in the last decade in tasks such as Speech-To-Speech Translation (SST). Our paper describes the creation of linguistically enriched aligned corpora for Catalan, Spanish and US-English. These corpora are obtained from two different sources: US-English transcribed speech data and transcriptions of converstions recorded in Catalan and Spanish. After human translation, a large trilingual spontaneous speech corpus has been obtained. This corpus is being linguistically enriched in order to generate a valuable resource capable of helping to improve statistical machine translation (SMT). #dialogues #dialogues 217 726 172 #turns #turns 16,241 10,998 9,321 #sentences #sentences 24,372 29,979 19,113 #words #words 287,655 349,970 277,777 Translation Tags VMCAT VMCAT #distinct words #distinct words 3,332 11,714 10,057 VM Punctuation marks Foreing words Interjections Proper names Letter spelling Abbreviations Neologisms VMUS-Eng VMUS-Eng e001ach2_000_ANV_230000_ENG: hi ~Mary~, how are you. e001ach2_000_ANV_230000_SPA: hola ~Mary~, cómo está. e001ach2_000_ANV_230000_CAT: hola ~Mary~, com està. e001ach1_001_SMA_230000_ENG: oh I am doing fine Mister ~Vandaloo~, how are you. e001ach1_001_SMA_230000_SPA: oh estoy bien señor ~Vandaloo~, cómo está. e001ach1_001_SMA_230000_CAT: oh estic bé senyor ~Vandaloo~, com està. e001ach2_002_ANV_230000_ENG: pretty good, <uhm> I guess we need to figure out a day, today is the first of November, so within the next two months when we can make it to, ~Hanover~? e001ach2_002_ANV_230000_SPA: muy bien, <uhm> supongo que necesitamos concretar un día, hoy es uno de noviembre, así pues entre los dos meses siguientes ¿cuándo podremos hacerlo a, ~Hanover~? e001ach2_002_ANV_230000_CAT: molt bé, <uhm> suposo que necessitem concretar un dia, avui és u de novembre, així doncs entre els dos mesos següents quan podrem fer-ho a, ~Hanover~? VMSPA VMSPA “The target sentence intends to be as literal as possible to the source sentence in the sense of word-to-word translation and word order as long as it is a proper sentence in the target language.” Filled pauses Technical interruptions Turn breaks Unidentifiable Hard to identify POS-tagging RECUS-Eng RECUS-Eng • English • Transformation-based learning Eric Brill’s tagger • Penn Treebank tagset • Catalan/Spanish • MACO+ & RELAX • EAGLES tagset • Problems: • Spontaneous speech disfluences REC B0162_21_1_001_000_CAT: bon dia. agència de viatges ~Sol i Mar~. parla amb ~Sebastià~. com el puc ajudar? B0162_21_1_001_000_SPA: buenos días. agencia de viajes ~Sol i Mar~. habla con ~Sebastià~. en qué puedo ayudarle? B0162_21_1_001_000_ENG: good morning. ~Sol i Mar~ travel agency. ~Sebastià~ speaking. can I help you? B0162_21_1_030_001_CAT: bon dia. voldria reservar un bitllet per ~Milwaukee~, ~Estats Units~. B0162_21_1_030_001_SPA: buenos días. quería reservar un billete para ~Milwaukee~, ~Estados Unidos~. B0162_21_1_030_001_ENG: good morning . I'd like to reserve a ticket for ~Milwaukee~ the ~United States~. RECCAT RECCAT Oral Database RECSPA RECSPA Summary Description of on-going work in the frame of the LC-STAR* project towards the development of language resources (LR) for SMT is provided. As an initial stage, a trilingual aligned corpus has been developed. Part-of-speech information has been added. A further objective of the project is the construction of lexica for SST. An important outcome of this work will be the specifications that should be later followed by other LR to be developed. * http://www.lc-star.org • Phone dialogues (10 minutes in average) • Rigid turn break recording platform (overlappings were not allowed). • Tourist domain scenarios: • Hotel • Travel Agency • Tourist Office • RailwayAirline Company • Speakers were provided templates containing tables, descriptions, figures, and detailed information. • Conversations disfluences were captured by the transcription methodology. Development of Language Resources for Speech-to-Speech Translation Victoria Arranz, Núria Castell and Jesús Giménez TALP Research Center - Universitat Politècnica de Catalunya, Barcelona, Spain. VerbMobil [Appointment Scheduling] TRANSL1 TRANSL2 Recording Sessions [Tourist Domain]