Download
1 / 26
260 likes | 457 Views
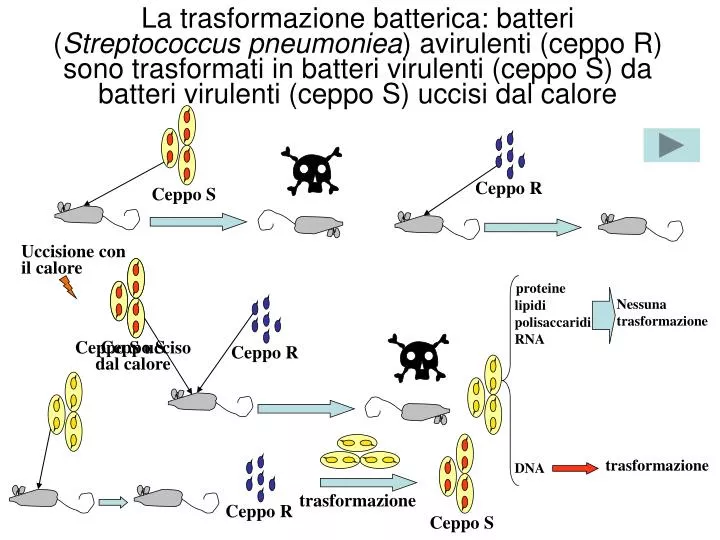
Uccisione con il calore. Ceppo S. Ceppo S. Ceppo S. Ceppo R. Ceppo R. Ceppo R. proteine. lipidi. polisaccaridi. RNA. Ceppo S ucciso dal calore. trasformazione.

E N D
Uccisione con il calore Ceppo S Ceppo S Ceppo S Ceppo R Ceppo R Ceppo R proteine lipidi polisaccaridi RNA Ceppo S ucciso dal calore trasformazione La trasformazione batterica: batteri (Streptococcus pneumoniea) avirulenti (ceppo R) sono trasformati in batteri virulenti (ceppo S) da batteri virulenti (ceppo S) uccisi dal calore Nessuna trasformazione trasformazione DNA
L’infezione di cellule del batterio Escheirichia coli da parte delfago T2 avviene mediante il DNA del virus, non mediante le sue proteine 32P La radioattività (e il DNA) entra Solo nel DNA 35S Solo nelle proteine La radioattività (con le proteine) non entra
H H H H + - ..... C N H O N H C C C C C Pirimidine - + ..... C H N N N H C N C C C N C Timina O H H Adenina H - + ......... N H O C C N H C H C C C N + - ........ H N N N C C C + - .......... C C N O H N Purine Citosina Guanina H Le basi azotate
O- O- C G P O O T A H2C5’ O BASE ….. P 5’ P 1’ C1’ C4’ 3’ 3’ P 1’ H H H H 5’ 5’ P 1’ C3’ C2’ 3’ 3’ 1’ 5’ HO H La struttura del DNA Legami idrogeno Legami idrofobici Nucleotide Il DNA è costituito da due catene polinucleotidiche antiparallele avvolte tra loro a doppia elica
T G A C T G A C Il modello della doppia elica del DNA Conoscenze preesistenti: il DNA è un polimero costituito da un numero molto elevato di subunità: i nucleotidi (fosfato + desossiribosio + 1 base azotata) Dati chimici: 1) Le molecole puriniche sono nello stesso numero delle molecole pirimidiniche (A+G=T+C); 2) Ciascuna delle molecole puriniche ha una e una sola molecola pirimidinica in uguale numero e precisamente: A=T, G=C Dati cristallografici: la figura ottenuta dalla diffrazione dei raggi x suggeriva che il DNA è una lunga molecola lineare, costituita a due filamenti paralleli avvolti a doppia elica Ammettendo che le basi azotate si trovino all’interno della doppia elica, solo l’affacciamento di una purina con una pirimidina garantiscono il diametro realmente riscontrato della doppia elca Originalità del modello di Crick e Watson: la complementarità di coppie di basi (una purina e una pirimidina) che con i loro legami idrogeno stabilizzano la struttura a doppia elica e che, mediante la separazione dei due filamenti polinucleotidici e l’incoprorazione di nucleotidi complementari sullo stampo dei filamenti preesistenti, garantiscono la precisione della replicazione del DNA e la correttezza della trasmissione ereditaria
Seconda generazione Prima generazione controlli 14N 15N Bande di DNA “pesante e “leggera” Incubazione di cellule pesanti in 14N conservativa Due bande 15N15N e 14N14N Due bande 15N15N e 14N14N dispersiva Due bande 15N14N e 14N14N Una banda 15N14N Una banda 15N14N Una banda intermedia tra 15N14N e 14N14N Replicazione semiconservativa: l’esperimento di Meselson e Sthal Centrifugazione di DNA in gradiente di cloruro di cesio. Le colture cresciute per molte generazioni in un terreno contenente 15N e 14N forniscono le posizioni di controllo per le bande di DNA “pesante “ e “leggera”. Quando le cellule fatte crescere in 15N vengono trasferite in un terreno 14N, la prima generazione produce una banda di DNA intermedia e la seconda produce due bande, una intermedia e una leggera. 15N14N Solo il modello semiconservativo di replicazione di DNA spiega questi risultati Replicazione semiconservativa
BrUdR BrUdR Replicazione semiconservativa del DNA nei cromosomi degli eucarioti Blocco della M1 con colchicina G1 S G2 Mitosi (M1) 2n G1 S G2 Mitosi (M2) 4n
DNA ligasi DNA polimerasi I SSB primasi girasi elicasi RNA primer DNA polimerasi III 5’ 3’ 3’ 5’ La forca replicativa leading strand lagging strand frammento di Okazaki Correzione di bozze L’incorporazione di nucleotidi “sbagliati” causa una distorsione della doppia elica; la DNA polimerasi rimuove il nucleotide sbagliato e inserisce quello corretto
I cromosomi degli eucarioti e il DNA 1) Misure viscosimetriche e microspettrofotometriche in neuroblasti di Drosophila: conoscendo la quantità totale di DNA per nucleo diploide (microspettrofotometria) e la lunghezza media delle molecole di DNA estratte (viscosimetria) si è verificato che ogni cromosoma è costituito da un’unica molecola di DNA Quantità di DNA corrispondente a circa 108 coppie di nucletidi Lunghezza media delle molecole: circa 1,25x107 coppie di nucleotidi 2) Misure metriche e microspettrofotometriche in cromosomi a spazzola di oociti di Urodeli: conoscendo la quantità totale di DNA per nucleo diploide (microspettrofotometria) e la lunghezza media delle fibre di cromatina estese con microaghi a partire dai cromomeri, verificando che tali fibre sono frammentate solo con l’uso di endonucleasi, e che, quindi, la loro continuità è dovuta al DNA, si è verificato che ogni cromosoma è costituito da un’unica molecola di DNA cromomero endonucleasi Quantità di DNA corrispondente a circa 109 coppie di nucletidi Lunghezza corrispondente a circa 109 coppie di nucletidi Il genoma aploide umano consta di circa 3 miliardi di nucleotidi, organizzati in 23 molecole a doppia lica di DNA, corrispondenti ai 23 cromosomi dell’assetto aploide umano
La struttura dei cromosomi degli eucarioti Impalcatura nucleare Solenoide Condensazione cromosomica (mitosi, meiosi) DNA Cromatina Nucleosoma Impalcatura cromosomica Ottamero di istoni
G-G G-G La replicazione negli eucarioti e il telomero Origini di replicazione: singola nei procarioti, multiple negli eucarioti Negli eucarioti, quando si avvicina la forca replicativa, gli istoni vengono rimossi per consentire l’azione del complesso di replicazione; a replicazione avvenuta avviene di nuovo l’aggregazione degli istoni a formare i nucleosomi All’estremità 3’ del lagging strand, dopo la rimozione del primer, la DNA polimerasi non può operare …TTAGGG TTAGGG 3’ TTAGGG… Interviene un enzima ad RNA, la telomerasi che allunga il lagging strand all’estremità 3’ aggiungendo copie della sequenza telomerica ripetuta …CCCAAT GGG… L’allungamento del filamento all’estremità 3’ offre spazio ulteriore all’RNA primer che consente alla DNA polimerasi di operare, evitando l’accorciamento del DNA Il filamento allungato si ripiega più volte a formare un’elica quadrupla, stabilizzata da un legame particolare tra 4 guanine affacciate
DNA ripetitivo negli eucarioti DNA altamente ripetitivo (“satellite”): 105 – 106 copie di sequenze fra loro adiacenti di 10-100 nucleotidi Sequenza base 105 – 106 copie Localizzazione: p. es. eterocromatina centromerica DNA mediamente ripetitivo: 103 – 105 copie di sequenze intersperse di 200-500 nucleotidi Sequenza base 103– 105 copie Localizzazione: lungo tutti i cromosomi 102 – 103 copie Geni a copia multipla adiacenti mediamente ripetitivi: 102 – 103 copie degli stessi geni Uno o pochi geni Localizzazione: p. es. geni per RNA ribosomale, braccio corto dei cromosomi umani 13, 14, 15, 21, 22 Sequenza base 103 – 104 copie Minisatelliti: 103 – 104 copie di sequenze fra loro adiacenti di 10-100 nucleotidi Localizzazione: siti specifici di cromosomi specifici CAG…………….CAG Microsatellite (CAG)n Microsatelliti: 10 – 102 copie di di-, trinucleotidi fra loro adiacenti Localizzazione: siti specifici di cromosomi specifici, anche entro geni Gene della corea di Huntigton
Cromosomi di cloroplasti e mitocondri sono circolari, come quelli dei procarioti I cromosomi di cloroplasti e mitocondri hanno un’unica origine di replicazione non effettuano alcun crossing over sono presenti in più copie entro lo stesso organello mitocondrio non sono autosufficienti: sono necessarie anche istruzioni dei geni nucleari per il funzionamento dell’ organello cloroplasto geni singoli geni duplicati hanno alcune duplicazioni e intervalli non codificanti hanno 100.000 – 300.000 basi I cromosomi dei cloroplasti hanno geni in un’unica copia, senza intervalli non codificanti hanno 16.000 – 300.000 basi I cromosomi dei mitocondri È stata formulata l’ipotesi che questi organelli siano il risultato dell’evoluzione di procarioti simbionti all’interno delle primitive cellule eucariotiche
b b A a B B b b A A a a B B A b a B Meccanismi molecolari del crossing over Se prima delle rotture del punto 3 avviene uno scorrimento dei filamenti del DNA, si possono formare dopie eliche “ibride” (eteroduplex) Le 2 doppie eliche di DNA appartengono a 2 cromatidi non fratelli di 2 cromosomi omologhi DNA eteroduplex A B 1) Si producono 2 rotture a singolo filamento 2) Le 2 rotture a singolo filamento vengono saldate mediante uno scambio a singolo filamento a b Ruotando la figura precedente, si osserva che si è compiuto il crossing over Ruotando la figura precedente in modo da evitare accavallamenti, si ottiene questa configurazione di DNA cruciforme, effettivamente osservato in meiosi di lievito 3) Si possono produrre 2 rotture a singolo filamento sui due filamenti di DNA non coinvolti negli scambi precedenti 4) Si saldano le 2 rotture con uno scambio a singolo filamento
a elica NH foglietto b N C Aminoacidi e proteine struttura primaria: sequenza lineare degli aminoacidi legame peptidico R R’ HO HO struttura secondaria: avvolgimenti o ripregamenti elementari della catena polipeptidica, dovuti a legami idrogeno tra aminoacidi vicini nella sequenza lineare C C NH2 H2O C C NH2 O O H H aminoacido 1 aminoacido 2 dipeptide struttura quaternaria: composizione di più catene polipeptidiche, uguali o diverse, a formare una proteina multimerica struttura terziaria: struttura tridimensionale della catena polipeptidica dovuta alle interazioni fra aminoacidi anche lontani nella sequenza lineare In ultima analisi le strutture secondaria, terziaria e quaternaria sono dovute alla struttura primaria omodimero
Un gene una catena polipeptidica Frammentando progressivamente un polipeptide, è possibile averne un’impronta digitale (fingerprinting) attraverso lo spostamento dei frammenti in 2 diversi solventi: così è possibile identificare il frammento che differisce fra l’allele normale e quello mutato, fino a individuare l’aminoacido cambiato Alleli diversi possono differire per la sostituzione di un solo aminoacido in una catena polipeptidica Nella catena b dell’emoglobina umana, l’aminoacido in posizione 6 è l’acido glutammico nell’allele normale dell’emoglobina A (HbA) ed è la valina nell’allele mutato dell’emoglobina S (HbS) Colinearità tra gene e catena polipeptidica Mediante l’analisi di cotrasduzione con il fago P1, si sono mappate diverse mutazioni in diversi sitidel gene TrpA (per la sintesi del triptofano) in Escheirichia coli Mediante l’analisi di fingerprinting si sono localizzati, nella catena polipeptidica, le posizioni degli aminoacidi caratteristici di ciascuna mutazione mappata N 15 22 49 175 15: Lys->STOP; 22: Phe->Leu; 49: Glu->Val,Gln,Met; 175: Tyr->Cys. La sequenza dei siti mutati nel gene è identica alla sequenza delle posizioni degli aminoacidi sostituiti, anche se le distanze non corrispondono esattamente
O- O- P O O C C G G BASE ….. O H2C5’ C1’ C4’ H H H U T A A H C2’ C3’ P P 5’ 5’ HO 1’ 1’ 3’ 3’ P P H 5’ 5’ H H 1’ 1’ C 3’ 3’ O C C C H N H N C C O Struttura dell’RNA RNA compl. DNA desossiribosio ribosio OH H 1 2 1 3 2 1 4 3 2 1 RNA trascritti DNA H Ibrido RNA-DNA Ibrido RNA-DNA Filamenti di RNA non ibridato Timina Uracile
C-G G-C C-G G-C C-G G-C RNA 11-15 nucl 5-8 nucl -10 -35 TGTTGACA TATAAT Sito di inizio La Trascrizione terminazione promotore Sito di attacco dell’aminoacido Tipo abbondanza coeff. sed. anticodone
La trascrizione e il processamento dell’RNA negli eucarioti promotore 25-30 nucl RNA polimerasi II GGCCAATCT TATAAAA Sito di inizio Fattori di trascrizione Regione centrale del promotore Intensificari r.c.p “snurp” AAAA Nucleo Negli eucarioti l’RNA prima di entrare nel citoplasma subisce una maturazione: al 5’ viene aggiunta una 7-metilguanosina, al 3’ una catena di poli-A Non tutto l’mRNA viene tradotto: una parte, corrispondente agli introni dei geni, viene staccato e rimosso; l’altra parte, corrispondente agli esoni dei geni, viene saldata e tradotta
Le mutazioni Le mutazioni sono cambiamenti accidentali, casuali ed ereditabili del materiale genetico A B D C c Le mutazioni geniche consistono nel cambiamento di un gene da una forma allelica all’altra. Le mutazioni cromosomiche strutturali consistono in riordinamenti dei cromosomi che portano alla perdita, all’acquisto o allo spostamento di geni. A B D A B D C Le mutazioni cromosomiche numeriche consistono in cambiamenti del numero dei cromosomi che portano alla perdita oall’acquisto di geni. A B D C A B D C
AG AG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG TAG Natura molecolare delle mutazioni geniche Delezione di base Sostituzione di base TAG T transizione TAG T G A Inserzione di base T C CODICE GENETICO trasversione Per codificare 20 aminoacidi, non bastano 4 nucleotidi e nemmeno 16 coppie di nucleotidi; sono necessarie combinazioni di almeno 3 nucleotidi (triplette) che sono 64 purina pirimidina 1 2 3 tripletta Lettura per giustapposizione Lettura per sovrapposizione tripletta 1 2 3
TAG TAG TAG TAG TAG rII+ Natura del codice genetico Se la lettura del codice fosse stata per sovrapposizione, una singola sostituzione di base avrebbe comportato la modificazione di tanti aminoacidi quante sono le basi che fanno parte dell’unità codificante (nell’esempio presente, supponendo un codice a triplette, gli aminoacidi modificati da una singola sostituzione di base avrebbero dovuto essere 3); invece si osserva la modificazione di un solo aminoacido; pertanto la lettura del codice è per giustapposizione. 1 2 3 tripletta G C TAG TA TAG TAG TAG tripletta 1 2 3 proflavina proflavina rII+ rII + - rII rII+ rII rII+ soppressore FCO 2 mutazioni successive di segno opposto (inserzione + delezione), separabili per crossing over, ripristinano la corretta cornice di lettura; quindi il codice è letto senza interruzioni e le sfasature dovute alla prima mutazione si mantengono a valle di essa fino a che non sono neutralizzate dalla seconda proflavina proflavina proflavina rII+ rII+ rII rII 3 mutazioni successive dello stesso segno, separabili per crossing over (3 inserzioni o 3 delezioni) ripristinano la corretta cornice di lettura;le sfasature dovute alla prima mutazione si mantengono a valle di essa fino a che non sono neutralizzate dalla seconda e dalla terza; quindi il codice è a triplette TAG TAG TTAG AG TAG TA TAG TG AG TAG
Decifrazione del codice genetico Costruendo un mRNA in vitro costituito di un unico nucleotide (X), ci sarà una sola tripletta (XXX); effettuando la sintesi proteica in vitro,si formerà un polipeptide costituito da un unico aminoacido (Z-Z-Z-…), codificato dalla tripletta XXX UUU UUU UUU Phe Phe Phe Costruendo un mRNA in vitro costituito di una miscela di nucleotidi (X e Y) in proporzioni note (p e q), ci sarà una miscela di triplette in proporzioni prevedibili (p3 XXX; p2q XXY, XYX, YXX; pq2 XYY, YXY, YYX; q3 YYY); effettuando la sintesi proteica in vitro,si formerà un polipeptide costituito da una miscela di aminoacidi nelle stesse proporzioni delle triplette che li codificano U:G = 3:1 Usando mini mRNA (1 sola tripletta), capaci di determinare il legame tra il tRNA complementare e il suo aminoacido consentendone l’identificazione, e mRNA costituiti da copolimeri ripetitivi della stessa tripletta (XYW)n, si è completamente decifrato il codice genetico
I codoni I codoni sono le triplette di basi di mRNA che codificano per specifici aminoacidi; sono complementari e antiparallele sia alle corrispondenti triplette sul DNA del gene trascritto, sia a quelle degli anticodoni, presenti sul tRNA corrispondente; la prima base è all’estremità 5’, l’ultima all’estremità 3’ Il codice genetico non è ambiguo: ogni codone codifica per un solo aminoacido Il codice genetico è degenerato: molti aminoacidisono codificati da più di un codone Il codice genetico è universale: quasi tutti i viventi condividono lo stesso codice genetico
al 5’ dell’anticodone al 3’ del codone Anticodoni e tRNA Ogni specie di tRNAha unanticodone specifico e lega un solo aminoacido DEGENERAZIONE DEL CODICE CODONI NON SENSO 1) Alcuni aminoacidi si legano a più di un tRNA UAA, UAG, UGA 2) Alcune basi all’estremità 5’ dell’anticodone (corrispondenti all’ultima base, in 3’, del codone) presentano un appaiamento non stringente (vacillamento) che riconosce più di una base in 3’ del codone; quindi alcuni tRNA riconoscono più di un codone 1) Usati come mini mRNA non legano alcun aminoacil-tRNA 2) Prodotti in seguito a una singola sostituzione di base a partire da triplette molto simili, producono, in corrispondenza della loro posizione, un’interruzione della catena polipeptidica (mutazioni non senso) 3) Le mutazioni non senso possono essere neutralizzate da mutazioni soppressori esterne al gene: si tratta di mutazioni nell’anticodone di un tRNA (p.es. GUA -> UUA, anticodone di UAA) I codoni non senso sono detti di terminazione perché interrompono la sintesi di una catena polipeptidica
aa3 aa1 aa1 aa1 aa2 aa2 Sintesi proteica e traduzione 5 S Il sito di inizio della traduzione nell’mRNA è una tripletta AUG, GUG preceduta di poco da sequenze complementari all’rRNA 16 S; tale tripletta codifica per N-formil-metionina (in E. coli) 23 S (28S) 50 S Sito P Sito A 30 S 16 S (18S) il tRNA con l’anticodone complementare al codone esposto nel sito A vi si lega, essendo già associato al proprio aminoacido (aminoacil-tRNA) Sul sito P è presente un tRNA entrato in precedente, cui è legato il nascente polipeptide (peptidil-tRNA);il polipeptide si stacca dal tRNA sul sito P e si lega all’aminoacido legato al tRNA sul sito A Il tRNA libero sul sito P si allontana, il codone e il peptidil-tRNA sul sito A si spostano sul sito P Quando sul sito A giunge un codone di terminazione, al posto di un tRNA vi si lega un Fattore di Rilascio che impedisce l’allungamento del poipeptide e conclude il processo






















