Download
1 / 213
2.13k likes | 2.29k Views
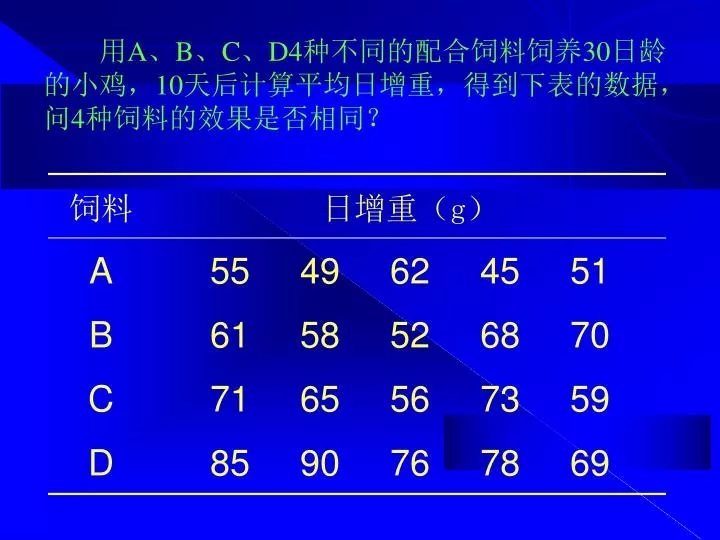
用 A 、 B 、 C 、 D4 种不同的配合饲料饲养 30 日龄的小鸡, 10 天后计算平均日增重,得到下表的数据,问 4 种饲料的效果是否相同?. 第六章 方差分析. 方差分析的定义. 方差分析 (Analysis of variance , ANOVA). 又叫变量分析,是英国著名统计学家 R . A . Fisher 于 20 世纪提出的。它是用以检验 两个或多个均数间 差异的假设检验方法。它是一类特定情况下的统计假设检验,或者说是平均数差异显著性检验的一种引伸。. 对多组样本平均数差异的显著性进行检验. 方差分析的 基本功能.

E N D
用A、B、C、D4种不同的配合饲料饲养30日龄的小鸡,10天后计算平均日增重,得到下表的数据,问4种饲料的效果是否相同?用A、B、C、D4种不同的配合饲料饲养30日龄的小鸡,10天后计算平均日增重,得到下表的数据,问4种饲料的效果是否相同?
方差分析的定义 方差分析(Analysis of variance,ANOVA) 又叫变量分析,是英国著名统计学家R . A . Fisher于20世纪提出的。它是用以检验两个或多个均数间差异的假设检验方法。它是一类特定情况下的统计假设检验,或者说是平均数差异显著性检验的一种引伸。
对多组样本平均数差异的显著性进行检验 方差分析的 基本功能
t 检验可以判断两组数据平均数间的差异显著性,而方差分析既可以判断两组又可以判断多组数据平均数之间的差异显著性。 有人说,我们可以把多组数据化成n个两组数据(化整为零),用n次t检验来完成这个多组数据差异显著性的判断。 ? 到底这种方法行不行
对多个处理进行平均数差异显著性检验时,采用t检验法的缺点:对多个处理进行平均数差异显著性检验时,采用t检验法的缺点: 缺 点 1.检验过程烦琐。 试验包含4个处理 t 检验: C42= 6次
缺 点 2.无统一的试验误差,误差估计的精确性和检验的灵敏性低。 t检验:C42=6次 需计算 6个标准误 误差估计不统一 误差估计精确性降低
缺 点 3.推断的可靠性低,检验时犯α错误概率大。 例如我们用t检验的方法检验4个样本平均数之间的差异显著性 t检验: C42=6次 6次检验 相互独立 H0的概率: 1-α=0.95 6次都接受的概率(0.95)6=0.735 犯α错误的概率=1-0.735=0.265 犯α错误的概率明显增加
试验指标(experimental index): 为衡量试验结果的好坏和处理效应的高低,在实验中具体测定的性状或观测的项目称为试验指标。常用的试验指标有:身高、体重、日增重、酶活性、DNA含量等等。 试验因素( experimental factor): 试验中所研究的影响试验指标的因素叫试验因素。当试验中考察的因素只有一个时,称为单因素试验;若同时研究两个或两个以上因素对试验指标的影响时,则称为两因素或多因素试验。
因素水平(level of factor):试验因素所处的某种特定状态或数量等级称为因素水平,简称水平。如研究3个品种奶牛产奶量的高低,这3个品种就是奶牛品种这个试验因素的3个水平。 试验处理(treatment):事先设计好的实施在实验单位上的具体项目就叫试验处理。如进行饲料的比较试验时,实施在试验单位上的具体项目就是具体饲喂哪一种饲料。
试验单位( experimental unit ):在实验中能接受不同试验处理的独立的试验载体叫试验单位。一只小白鼠,一条鱼,一定面积的小麦等都可以作为实验单位。 重复(repetition):在实验中,将一个处理实施在两个或两个以上的试验单位上,称为处理有重复;一处理实施的试验单位数称为处理的重复数。例如,用某种饲料喂4头猪,就说这个处理(饲料)有4个重复。
第一节 方差分析的基本原理 一、方差分析的基本思想、目的和用途 二、数学模型 三、平方和与df的分解 四、统计假设的显著性检验 五、多重比较
方差:又叫均方,是标准差的平方,是表示变异的量。方差:又叫均方,是标准差的平方,是表示变异的量。 在一个多处理试验中,可以得出一系列不同的观测值。 处理效应(treatment effect): 处理不同引起 观 测 值 不 同 的 原 因 试验误差:试验过程中偶然性 因素的干扰和测量误差所致。
方差分析的基本思想 试 验 误 差 处 理 效 应 总 变 异
方差分析的目的 确定各种原因在总变异中所占的重要程度。 处理效应 相差不大,说明试验处理对指标影响不大。 相差较大,即处理效应比试验误差大得多,说明试验处理影响是很大的,不可忽视。 试验误差
方差分析的用途 1. 用于多个样本平均数的比较 1. 用于多个样本平均数的比较 2. 分析多个因素间的交互作用 2. 分析多个因素间的交互作用 3. 回归方程的假设检验 4. 方差的同质性检验
处理 重复 1 2 … i … k 1 2 … j … n x11 x12 … x1j … x1n x21 x22 … x2j … x2n … … … … … … xi1 xi2 … xij … xin … … … … … … xk1 xk2 … xkj … xkn 总和 T1 T2 … Ti … Tk T=∑xij x1 x2 xi xk x 平均 二、数学模型 假定有k组观测数据,每组有n个观测值,则共有nk个观测值 …
二、数学模型 用线性模型(linear model)来描述每一观测值: xij =μ + τi +εij (i=1,2,3…,k j=1,2,3…,n) μ-总体平均数 τi-处理效应 εij-试验误差 xij-是在第i 次处理下的第j次观测值 要求εij 是相互独立的,且服从标准正态分布 N(0,σ2 )
xij =μ + τi +εij 二、数学模型 对于由样本估计的线性模型为: xij =x + ti +eij x-样本平均数 ti-样本处理效应 eij-试验误差
二、数学模型 根据的τi不同假定,可将数学模型分为以下三种: 固定模型 随机模型 混合模型
二、数学模型 (一)固定模型(fixed model) 指各个处理的效应值τi是固定值,各个的平均效应τi= μi- μ是一个常量,且∑τi=0。就是说除去随机误差以后每个处理所产生的效应是固定的。 实验因素的各水平是根据试验目的事先主观选定的而不是随机选定的。
二、数学模型 固定模型 不同离子对木聚糖酶活性的影响(mg/ml) Na+ K+ Mn2+ Cu2+ 0.00 0.25 0.50 0.75 1.00 1.25 0.00 0.40 0.60 0.80 1.00 1.20 0.00 0.06 0.12 0.18 0.24 0.30 0.00 0.40 0.80 1.20 1.60 2.00
二、数学模型 固定模型 在固定模型中,除去随机误差之后的每个处理所产生的效应是固定的,试验重复时会得到相同的结果 方差分析所得到的结论只适合于选定的那几个水平,并不能将其结论扩展到未加考虑的其它水平上。
二、数学模型 (二)随机模型(random model) 指各处理的效应值τi 不是固定的数值,而是由随机因素所引起的效应。 这里τi是一个随机变量,是从期望均值为 0,方差为σ2 的标准正态总体中得到的随机变量。得出的结论可以推广到多个随机因素的所有水平上。
二、数学模型 随机模型 美国的黑核桃品种对不同地理条件的适应情况 河南 北京 广州 江苏 新疆 气候、水肥、土壤 无法人为控制 如果实验条件不能人为控制,那么这个样本对所属总体作出推断就属于随机模型。
二、数学模型 随机模型 在随机模型中,水平确定之后其处理所产生的效应并不是固定的,试验重复时也很难得到相同的结果 方差分析所得到的结论,可以推广到这个因素的所有水平上
二、数学模型 固定模型与随机模型的比较 1. 两者在设计思想和统计推断上有明显不同,因此进行方差分析时的公式推导也有所不同。其平方和与df的分解公式没有区别,但在进行统计推断时假设检验构成的统计数是不同的。 2. 模型分析的侧重点也不完全相同,方差期望值也不一样,固定模型主要侧重于效应值的估计和比较,而随机模型则侧重效应方差的估计和检验 3. 对于单因素方差分析来说,两者并无多大区别
二、数学模型 (三)混合模型(mixed model) 指多因素试验中既有固定因素又有随机因素时所用的模型. 在实际应用中,固定模型应用最多,随机模型和混合模型相对较少
∑(x-μ)2 ∑(x- x )2 σ2= s2 = n-1 N 三、平方和与df的分解 方差是离均差平方和除以自由度的商 方差分析的基本思想 引起观测值出现变异分解为处理效应的变异和试验误差的变异。 要把一个试验的总变异依据变异来源分为相应的变异,首先要将总平方和和总df分解为各个变异来源的的相应部分。
处理 重复 1 2 … i … k 1 2 … j … n x11 x12 … x1j … x1n x21 x22 … x2j … x2n … … … … … … xi1 xi2 … xij … xin … … … … … … xk1 xk2 … xkj … xkn (x- xi ) ( xi –x ) Tk 总和 T1 T2 … Ti … T=∑xij x1 x2 平均 … … xi xk x 平 方 和 三、平方和与df的分解 处理间平均数的差异是由处理效应引起的: 处理内的变异是由随机误差引起:
( xi – x )2 (x - x )= (x- xi )+ (x- xi )+ (x- xi )2 + (x- xi )2 + (x - x )2=[ ]2 +(xi – x )2 = n n n ∑(x - x )2= ∑ 2∑ (x- xi ) 2(x- xi ) 1 1 1 n ( xi –x ) ( xi –x ) ( xi –x ) ( xi –x ) +∑ 1 平 方 和 三、平方和与df的分解 根据线性可加模型,则有: 每一个处理n 个观测值离均差平方和累加: 0
? (x- xi ) ( xi –x )=0 处理 重复 1 2 … i … k 1 2 … j … n x11 x12 … x1j … x1n x21 x22 … x2j … x2n … … … … … … xi1 xi2 … xij … xin … … … … … … xk1 xk2 … xkj … xkn n 2∑ 1 Tk 总和 T1 T2 … Ti … T=∑xij x1 x2 平均 … … xi xk x
平 方 和 (x- xi ) ( xi –x ) 由于 =0,则: n n n (x- xi )2 ∑(x - x )2= ∑ +∑ ( xi – x )2 1 1 1 ( xi – x )2 (x - x )2= (x- xi )2 k k n n ∑∑ ∑∑ 1 1 1 1 k n +n∑ 2∑ 1 1 三、平方和与df的分解 把k 个处理的离均差平方在累加,得 处理内或组内平方和 SSe 处理间或组间平方和 SSt 总平方和 SST
平 方 和 = ∑x2 - = ∑x2- T2 (∑x)2 T2 kn kn kn 三、平方和与df的分解 SST = SSt + SSe 总平方和=处理间平方和 + 处理内平方和 k n ∑∑ (x - x )2 SST = 1 1 令矫正数C= ,则: SST = ∑x2 -C
平 方 和 k ( xi – x )2 SSt = ∑ 1 k k n∑( - 2 + ) = n∑ - +nk k k k k nkT2 Ti = 1 Ti2 n∑ n∑ n∑ n∑ 1 (nk)2 n 1 1 1 1 n2 1 = -2nk + n xi xi xi =k = = - x2 x x x T k = xi2 xi2 xi2 nk xi2 2n ∑ nkx2 nkx2 x2 x2 xi x 1 = ∑ Ti2 - C = - 三、平方和与df的分解
1 处理间平方和: SSt = ∑ Ti2 - C n 三、平方和与df的分解 平 方 和 总平方和:SST = ∑x2 -C 处理内平方和:SSe = SST - SSt
三、平方和与df的分解 自 由 度 总自由度也可分解为处理间自由度和处理内自由度: dfT = dft + dfe 总 df 处理间df 处理内df
处理 重复 1 2 … i … k 1 2 … j … n x11 x12 … x1j … x1n x21 x22 … x2j … x2n … … … … … … xi1 xi2 … xij … xin … … … … … … xk1 xk2 … xkj … xkn Tk 总和 T1 T2 … Ti … T=∑xij x1 x2 平均 … … xi xk x 三、平方和与df的分解 自由度 dfT = nk-1 dft = k-1 dfe = dfT - dft = nk-1-(k-1) =nk-k = k(n-1)
st2= SSt SSe dft dfe se2 = 三、平方和与df的分解 根据各变异部分的平方和和自由度,可求得处理间方差( st2)和处理内方差( se2):
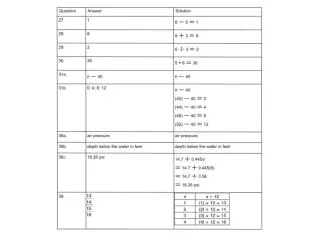
重 复 品 种 大白 沈白 沈黑 沈花 1 2 3 4 31.9 24.0 31.8 35.9 24.8 25.7 26.8 25.9 22.2 23.0 26.7 24.3 27.0 30.8 29.0 24.6 Ti 123.6 103.2 96.2 111.4 T=434.4 xi x 30.9 25.8 24.1 27.9 =27.2 某猪场对4个不同品种幼猪进行4个月增重量的测定,每个品种选择体重接近的幼猪4头,测定结果列于下表,试进行方差分析。 k=4,n=4,nk=16
例 重 复 品 种 大白 沈白 沈黑 沈花 1 2 3 4 31.9 24.0 31.8 35.9 24.8 25.7 26.8 25.9 22.2 23.0 26.7 24.3 27.0 30.8 29.0 24.6 1 n C= = Ti 123.6 103.2 96.2 111.4 T=434.4 xi T2 x 30.9 25.8 24.1 27.9 =27.2 kn 434.42 16 SSt = ∑ Ti2 - C 4个不同品种猪4个月的增重量(kg) (1)平方和的计算: =11793.96 SST = ∑x2 -C = 31.92 + 24.02 +…+ 24.62 - C =103.94 =213.3 SSe= SST - SSt =213.3 - 103.94 =109.36 =1/4×(123.62 + 103.22 + …+ 111.42 ) - C
例 st2= SSe SSt dfe dft 103.942 = =34.647 3 se2 = 109.362 = =9.113 12 (2)自由度的计算: dfT =nk-1 =16-1=15 dft =k-1 = 4-1=3 dfe =k(n-1) =4×3=12 (3)方差计算:
四、统计假设的显著性检验 ——F 检验
处理效应 试验误差 方差分析的目的: 确定各种原因(处理效应、试验误差)在总变异中所占的重要程度。 处理间的方差(st2)可以作为处理效应方差的估计量 处理内的方差(se2)可以作为试验误差差异的估计量
处理效应 试验误差 二者相比,如果相差不大,说明不同处理的变异在总变异中所占的位置不重要,也就是不同试验处理对结果影响不大。 如果相差较大,也就是处理效应比试验误差大得多,说明试验处理的变异在总变异中占有重要的位置,不同处理对结果的影响很大,不可忽视。
F= s12 s22 F检验 从第三章我们已经知道,从一正态总体(μ ,σ2)中随机抽取两个样本,其样本方差s12 与s22 的比值为F: 其F分布曲线随着df1和df2的变化而变化。由于F值表是一尾的( F值的区间〔0,+∞)),一般将大方差作分子,小方差作分母,使F值大于1,因此,表上df1 的代表大方差自由度, df2代表小方差自由度。
处理效应 试验误差 方差分析 用处理效应的方差(st2)和实验误差的方差(se2)比较时,我们所做的无效假设是假设处理效应的变量和实验误差的变量是来自同一正态总体的两个样本,因此处理效应的方差(st2)和实验误差的方差(se2)的比值就是F值,即 =
F检验 在进行不同处理差异显著性的F检验时,一般是把处理间方差作为分子,称为大方差,误差方差作为分母,称为小方差。 无效假设是把各个处理的变量假设来自同一总体,即处理间方差不存在处理效应,只有误差的影响,因而处理间的样本方差σt2 与误差的样本方差σe2 相等: Ho:σt2=σe2 HA:σt2≠σe2
se2 无论无效假设是否为真,se2 均为总体方差σ2的估计。 只有无效假设为真时,st2 (=se2 )才是总体方差σ2 的估计;当无效假设不真时,将st2 (>se2)是一个比σ2 更大的估计值。 st2