Download
1 / 7
70 likes | 159 Views
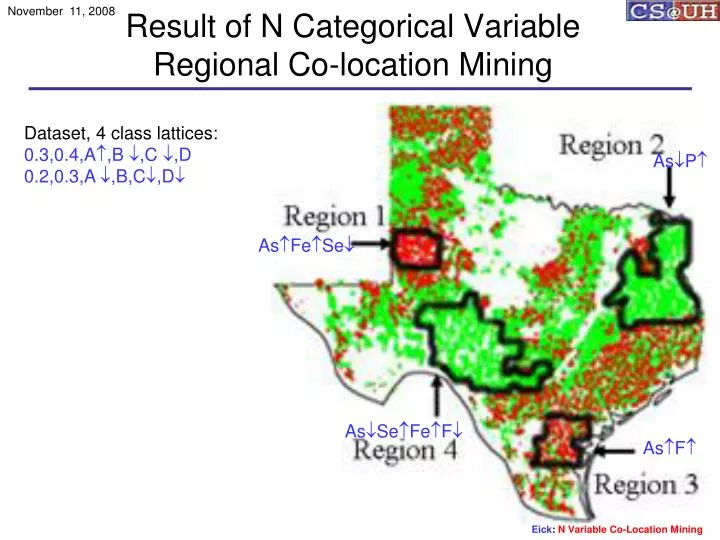
November 11, 2008. Result of N Categorical Variable Regional Co-location Mining. Dataset, 4 class lattices: 0.3,0.4,A ï‚,B ,C ,D 0.2,0.3,A ,B,C,D. As Pï‚. As ï‚Feï‚ Se . As Seï‚Feï‚F. As ï‚Fï‚. Regional Co-Location Mining Framework for q Binary Variables.

E N D
November 11, 2008 Result of N Categorical VariableRegional Co-location Mining Dataset, 4 class lattices: 0.3,0.4,A,B ,C ,D 0.2,0.3,A ,B,C,D AsP AsFeSe AsSeFeF AsF
Regional Co-Location Mining Frameworkfor q Binary Variables Example: Co-location set CS={A,B,C}; CoLoc-interestingness({A,B,C},r)= ((r,A) 1)((r,B) 1)((r,C) 1) Dataset O Remark: Strength is computed by comparing r with the whole Dataset O. r • Remarks: • Have to iterate over all possible co-location sets • Interestingness of the region is the interestingness of the maximum valued co-location set
Region Interestingness • Region interestingness is assessed by computing the most prevalent pattern: • Region interestingness solely depends on the most interesting co-location set for the region.
Co-Location Mining Frameworkfor q Binary Class Variables Version1 O – dataset rO – a region oO – object in the dataset O CS= {C1,…,Cr} – set of binary class variables that form base patterns; oCo.C=true th– class multiplier interestingness threshold, default-value 1 [0, ∞) – form parameter, default value 1 CCS be a single class variable BCS – a co-location set P(B) is a predicate over B that restricts the set of co-location sets considered; e.g. P(B)=|B|<5 or P(B)=AsB (“only look for patterns involving high arsenic”) (r,C)=(|{or|oC}|)/|r|)/(|{oO|oC}|/|O|) – C’s probability multiplier in r; high interestingness is associated with high multipliers z(C,r)= If (r,C)>th then ((r,C)-th) else 0 – normalized interestingness for C in r k(B,r)= CBz(C,r) – normalized interestingness of co-location set B in r i(r)=maxBS & |B|>1 and P(B)k(B,r) – region interestingness; maximum normalized interestingness observed for subsets BCS constrained by P Reward(r)= i(r)*|r|b
Co-Location Mining Frameworkfor q Binary Class Variables Version2 O – dataset rO – a region oO – object in the dataset O CS= {C1,…,Cr} – set of binary class variables that form base patterns; oCo.C=true th1 – co-location set interestingness threshold [0, ∞) – form parameter, default value 1 CCS be a single class variable BCS – a co-location set P(B) is a predicate over B that restricts the set of co-location sets considered; e.g. P(B)=|B|<5 or P(B)=AsB (“only look for patterns involving high arsenic”) (r,C)=(|{or|oC}|)/|r|)/(|{oO|oC}|/|O|) – C’s probability multiplier in r; high interestingness is associated with high multipliers k(B,r)= CB (r,C) –interestingness of co-location set B in r i’(r)=maxBS & |B|>1 and P(B)k(B,r) – region interestingness; maximum interestingness observed for subsets BCS constrained by P i(r)=IF i’(r)> th THEN (i’(r)-th) ELSE 0 –normalized region interestingness (th>=1; form parameter) Reward(r)= i(r)*|r|b
Datasets and Program Interface • Discretize the z-score normalized variable as follows: • z(A)1: A • -1 z(A) 1: A • Otherwise: A • The transformed dataset therefore have the form: <longitude, latitude, <class-variable>+ ) • Limit Co-location sets we are looking for in experiments to “” and “” class variables, to make it comparable to the continuous approach • Limit Co-location Sets to sizes 2-4 in the experiments! • Possibly conduct experiments with large sets using a single seed pattern; e.g. D • Therefore the program inputs of the categorical regional collocation mining versions should include: • k’ ---the maximum set size considered • The seed pattern, e.g. B, if we have a seed pattern; if we do not have a seed pattern is given all sets of sizes 2,…,k’ will be considered • Pattern list considered