Download

1 / 18
180 likes | 344 Views
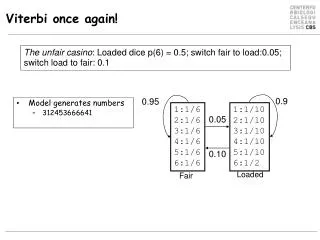
Viterbi Training. It is like Baum-Welsh. Instead of the As and Es , the most probable paths for the training sequences are derived using the Viterbi algorithm. Guaranteed to converge. Maximize. 1. Baum-Welsh Example:. Generating model. Estimated model from 300 rolls of dice.

E N D
Viterbi Training • It is like Baum-Welsh. • Instead of the As and Es, the most probable paths for the • training sequences are derived using the Viterbi algorithm. • Guaranteed to converge. • Maximize 1
Baum-Welsh Example: Generating model Estimated model from 300 rolls of dice 2
3.4 HMM model structure • Fully connected model? • Never works in practice due to local maxima • In practice, successful models are constructed based on knowledge about the problem • If we set akl=0, in the Baum-Weltch estimation, akl will remain 0 • How to choose a model with our knowledge?
Silent States for 200 states, it requires 200*199/2 transitions for 200 non-silent states, it requires around 600 transitions
For HMM without loops consisting entirely of silent states, all HMM algorithms in Section 3.2 and 3.3 could be extended. For forward algorithm: For HMM with loops consisting entirely of silent states, we could eliminate silent states by calculating the effective transition probabilities between real states in the model
3.5 Higher Order Markov Chains 2nd-order Markov Chain 11
Inhomogeneous Markov Chain • Use three different Markov Chains to model coding regions Pr(x) = • n-th order emission probabilities 15
3.6 Numerical stability of HMM algorithms • To avoid underflow error, two ways to deal with the problem • The log transformation • Scaling of probabilities • The log transformation