Download
1 / 20
200 likes | 348 Views
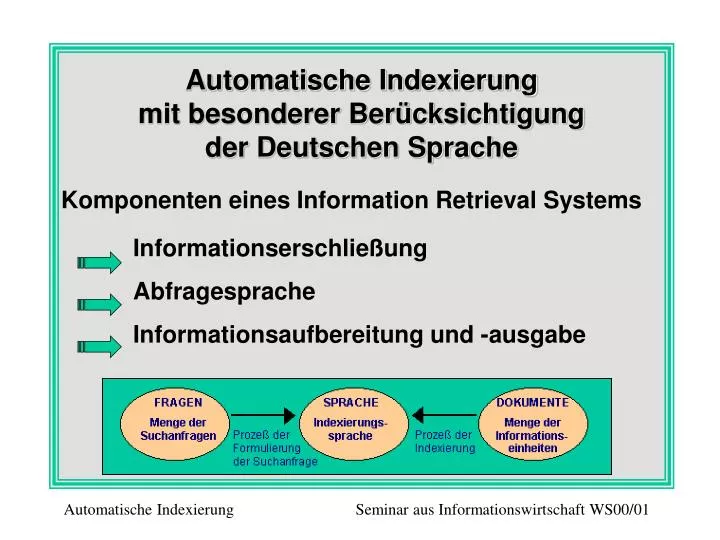
Automatische Indexierung mit besonderer Berücksichtigung der Deutschen Sprache Komponenten eines Information Retrieval Systems Informationserschließung Abfragesprache Informationsaufbereitung und -ausgabe. Automatische Indexierung Seminar aus Informationswirtschaft WS00/01.

E N D
Automatische Indexierung mit besonderer Berücksichtigung der Deutschen Sprache • Komponenten eines Information Retrieval Systems • InformationserschließungAbfragespracheInformationsaufbereitung und -ausgabe Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Indexierung und Information Retrieval Systeme Die Indexierung von Dokumenten ist eine zentrale Operation in einem Informationssystem Ermittlung von Deskriptoren, die den Inhalt eines Dokumentes repräsentieren Es ermöglicht die Suche nach Dokumenten die für den Benutzers relevant sind das Verknüpfung der Dokumente, die thematisch zusammengehören die Relevanzbestimmung der einzelnen Dokumente Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Qualität des Indexierungsprozesses • Die Güte des Indexierungsprozesses bestimmt die Effektivität des Informationssystems bei der Recherche • Recall • Verhältnis der Anzahl der vom System aufgrund der Suchanfrage gefundenen Dokumente zu allen hinsichtlich des Suchbegriffes relevanten DokumentenMaß für die Vollständigkeit des Suchergebnisses • Precision • Maß für die Genauigkeit der Suche dargestellt als Anteil der relevanten Dokumente, die aufgrund der Suchanfrage gefunden wurden Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Automatische Indexierung • Dokumentenorientierter Ansatz • Gewinnung der Deskriptoren aus dem Titel, aus einer Zusammenfassung oder aber aus dem Volltext des Dokumentes selbst • Automatische Schlagwortvergabe • Volltextinvertierung • Begriffsorientierter Ansatz • Gewinnung der Deskriptoren aufgrund eines verbindlichen, kontrollierten Indexierungsvokabulars (=eine Art Wörterbuch) • Automatische Deskriptorenvergabe • Automatische Notationsvergabe Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Verfahren der automatischen Indexierung • Statistisches Verfahren • Bedeutung der einzelnen Begriffe hängt eng mit der Häufigkeit des Auftretens im Dokument zusammen • Probabilistisches Verfahren • Bestimmung der Relevanzwahrscheinlichkeit steht im Mittelpunkt der Untersuchungen • Linguistisches Verfahren • Deskriptoren werden mit Hilfe einer morphologischen, syntaktischen und semantischen Analyse der Dokumente gewonnen. Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Statistische Verfahren Bei der Informationsstatistik geht es darum, Wörter in Texten zu zählen und entsprechend deren Relevanz zu gewichten. Die Gewichtung erfolgt anhand mehrerer Faktoren: Einfache Zählungen von Worthäufigkeiten Dokumentspezifische Wortgewichtung WDF (i) = [ld(Freq(i,j) + 1) + 1] / ld L Position im Text Inverse Dokumentenhäufigkeit IDF(i) = (log2 N/n) + 1 Wortabstand Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Statistische Modelle im Überblick • Modell von Luhn - Ermittlung von Worthäufigkeiten • Ermittlung der absoluten Häufigkeit jedes einzelnen Begriffes für jedes Dokument • Ermittlung der Häufigkeit eines Begriffes in der gesamten Dokumentensammlung • Eliminierung aller Begriffe, die öfters als der obere Schwellenwert und seltener als der untere Schwellenwert vorkommen Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Statistische Modelle im Überblick • Modell von Sparck Jones - Inverse Dokumentenhäufigkeit • Bedeutsamkeit eines Begriffes ist proportional zur Häufigkeit des Begriffes im Dokument, jedoch umgekehrt proportional zur Gesamtanzahl der Dokumente der gesamten Datenbasis, in denen der Begriff vorkommt • Der Schwerpunkt der Gewichtung wird auf die Begriffe gelegt, die im Dokument selbst relativ oft vorkommen, die aber gleichzeitig in relativ wenigen Dokumenten der gesamten Datenbasis zu finden sind • Gewährleistet die Abgrenzung und Unterscheidung der einzelnen Dokumente voneinander Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Statistische Modelle im Überblick • Modell von Dennis - Signalwert und Balast • Signalwert • Ist umso größer, je seltener der Begriff im Dokument vorkommt • Verringert die Unsicherheit über den Inhalt des Dokumentes • Ballast • Erreicht sein Maximum, wenn der Begriff in jedem Dokument gleich oft vorkommt und sein Minimum, wenn er nur in genau einem Dokument vorkommt • Je geringer der Wert des Ballast ist, desto eher ist der Term als Deskriptor dazu geeignet, die einzelnen Dokumente voneinander zu unterscheiden Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Statistische Modelle im Überblick • Modell von Salton - Diskriminanzwert • Der Diskriminanzwert bringt zum Ausdruck, inwieweit ein Begriff ein Dokument von einem anderen Dokument unterscheiden kann • Positive Diskriminanzwerte stehen für Begriffe von mittlerer Frequenz. Diese Begriffe sollten bei der Indexierung bevorzugt werden. • Negative Diskriminanzwerte ergeben sich für Begriffe mit sehr hoher Frequenz. Sie sollten nicht zur Indexierung benutzt werden. • Indifferente Diskriminanzwerte nahe 0 stehen für Niedrigfrequenzbegriffe. Sie beeinflussen die Ähnlichkeit zweier Dokumente nicht und können daher zur Indexierung verwendet werden oder auch nicht. Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Probabilistische Verfahren • Im Mittelpunkt steht Bestimmung der Relevanzwahrscheinlichkeit, die auch mit dem persönlichen Nutzen des Benutzers verglichen werden kann. • Das 2-Poisson-Modell • Geht davon aus, daß die Relevanz eines Suchbegriffes in einem Dokument von der relativen Ausführlichkeit der Themenbehandlung im Dokument abhängig ist. • Das Utility-Theorie-Modell • Hauptziel ist die Erreichung des maximalen Nutzens für den Benutzer des Retrieval Systems. Ein Deskriptor wird einem Dokument genau dann zugeteilt, wenn der davon insgesamt zu erwartende Nutzen größer ist als der einer Nicht-Zuteilung. Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Probabilistische Verfahren • Das "unified model" • Die Dokumente durch ungewichtete Deskriptoren indexiert. Es wird davon ausgegangen, daß sich die Wahrscheinlichkeit der Relevanz eines Dokumentes bei einem gegebenen Suchbegriff feststellen läßt. Sie basiert auf dem Vorhandensein bzw. dem Fehlen des Suchbegriffes im Dokument. Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Linguistische Verfahren • Linguistische Verfahren bestehen in der Regel aus drei aufeinander aufbauenden Schritten, die notwendig sind, um für die Indexierung ausreichende Ergebnisse zu erhalten • Morphologischen Analyse • Findet auf der Wortebene statt • Syntaktischen Analyse • Findet auf der Satzebene statt • Semantischen Analyse • Findet auf der Ebene des gesamten Dokumentes statt Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Morphologische Analyse • Findet auf der Wortebene statt und hat die Aufgabe, • nicht sinntragende Wörter zu eliminieren, • grammatikalische Flexionsformen auf eine Grundform zu bringen, • aus mehreren Termen bestehende Phrasen zu erkennen und • Pronomina den Nomen zuzuordnen, • um so Unabhängigkeit von der aktuellen Erscheinungsform eines Wortes im Text zu erzielen • Voraussetzung ist die Isolation einzelner Wörter bzw. Zeichenfolgen! Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Morphologische Analyse • Stoppwörter • Elimination von nicht bedeutungstragenden Wörtern durch • Wortfrequenzanalyse • Rauschmaß • Flexionsformengenerierung • Anlegen eines Wörterbuches, mit allen grammatisch möglichen Formen aller Wörter • Lemmatisierung bzw. Wortstammbildung • Ermittlung der grammatischen Grund- oder Stammform durch die Rückführung der konkreten Wortform auf einen Wörterbucheintrag Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Morphologische Analyse • Phrasenerkennung • Durch Abgleich mit Listen bzw. Analyse gemeinsamen Auftretens in den Dokumenten • Synonyme • Unterschiedliche Bezeichnungen für den selben Begriff • Kompositazerlegung • Zerlegen von Mehrwortbegriffen in einzelne Grundformen • Derivation • Zusammenfassen von verschiedenen Wortklassen oder Derivaten mit der selben Grundform • Bindestrichergänzung Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Syntaktische Analyse • Findet auf der Satzebene statt und baut auf den Satzkontext eines einzelnen Wortes und auf dessen syntaktischen Merkmalen auf. • Phrasenstrukturgrammatiken • Baut auf Ersetzungsregeln auf, wobei zwischen terminalen und nichtterminalen Elementen und kontextfreien und kontextsensitiven Grammatiken unterschieden wird. Nichtterminalen Elemente können unabhängig vom Kontext durch terminale Elemente ersetzt werden. Terminale Elemente können nicht ersetzt werden. • Transformationsgrammatiken • Baut ebenfalls auf Ersetzungsregeln auf. Die Regeln sind jedoch im Unterschied zu Phrasenstrukturgrammatiken vom Kontext abhängig. Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Syntaktische Analyse • Übergangsnetzwerkgrammatiken • Die Grammatik wird als ein Netzwerk von Knoten (=Zustände) und Kanten (=Übergang von einem Zustand in einem anderen) dargestellt. • Kommt es zu Mehrdeutigkeiten in den Knotenbeziehungen - von einem bestimmten Zustand aus sind mehrere Übergänge zu anderen Zuständen möglich - wird eine Rangfolge der möglichen Wege hinsichtlich ihrer Wahrscheinlichkeit aufgestellt und der Weg mit der höchsten Wahrscheinlichkeit verfolgt. Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Semantische Analyse • Findet auf der Ebene des gesamten Dokumentes statt • Es wird versucht, sinntragende Zusammenhänge im Dokument zu erkennen, um den gesamten Text in bedeutungsabhängige Einheiten zerlegen zu können • Möglichkeiten der Verwendung semantischer Informationen in der Sprachanalyse derzeit aufgrund großem Aufwand noch sehr begrenzt Automatische Indexierung Seminar aus Informationswirtschaft WS00/01
Schlußfolgerungen und Ausblick • Systeme automatischer Indexierung deutschsprachiger Texte sind in der kommerziellen Informationswirtschaft noch relativ selten im Einsatz, was auf die zahlreichen Ausnahmen der deutschen Sprache zurückzuführen ist • Weder der alleinige Einsatz der manuellen Indexierung noch der alleinige Einsatz eines automatischen Indexierungsverfahrens führt derzeit zu einem befriedigenden Ergebnis • Besonders im Hinblick auf die immer größer werdende Informationsflut wird es notwendig sein, Tools zur automatischen Indexierung laufend weiterzuentwickeln und zu verbessern Automatische Indexierung Seminar aus Informationswirtschaft WS00/01






















