Download

1 / 31
310 likes | 433 Views
V6: Proteinstrukturvorhersage. Bedeutung von Folds . Grundsätzliches zu Struktur – Funktion Beziehung. Definition von Folds: siehe V5 Structural genomics soll die Strukturen von 1000-10.000 Proteinen vor allem mit neuen Faltungsmustern („folds“) aufklären.

E N D
V6: Proteinstrukturvorhersage Bedeutung von Folds. Grundsätzliches zu Struktur – Funktion Beziehung. Definition von Folds: siehe V5 Structural genomics soll die Strukturen von 1000-10.000 Proteinen vor allem mit neuen Faltungsmustern („folds“) aufklären. V7 Homologiemodellierung von Proteinen.
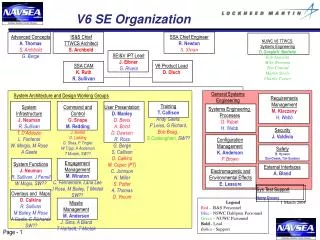
Analyse einer unbekannten Sequenz Input: neue Proteinsequenz Experimentelle Daten vorhanden? Multiples Sequenzalignment Suche in Sequenzdatenbanken nach identischer Sequenz bzw. ähnlichen Sequenzen Erkenne Domänen Gibt es ähnliche Sequenz mit bekannter 3D-Struktur? Vorhersage der Sekundärstruktur Zuordnung eines Protein-Folds Nein Analyse dieses Folds, Nachbarn? Ja Ja Fold erkannt? Alignment der Sekundärstrukturen. Nein Modellierung der Proteinstruktur durch Homologiemodellierung Alignment der Sequenz mit einerTarget-Struktur Ab inito Vorhersage der Tertiärstruktur 3D-Proteinstruktur Nach Rob Russell, http://speedy.embl-heidelberg.de/ gtsp/flowchart2.html Kann man Funktion zuordnen?
Integrative Datenbankanalyse Gibt es Faltungsmuster, die es nur in bestimmten phylogenetischen Gruppen gibt? Diese Proteine könnte gute Targets für selektive Inhibitoren sein. Das Ziel von structural genomics könnte sein, die Lücken zwischen den bekannten Regionen zu füllen.
Integrative Datenbankanalyse Integrative database analysis in structural genomicsM. Gerstein, Nat. Struct. Biol. 7, 960 (2000) 10 most common folds in yeast genome (= number of gene duplications); table shows ranking according to various measures. It shows how common popular folds in yeast occur in other genomes and in the PDB data base; variety of functions; level of expression. Bestimmte Faltungsmuster kommen in allen Organismen vor!
Beziehung zwischen Fold, Funktion, und WWs Integrative database analysis in structural genomicsM. Gerstein, Nat. Struct. Biol. 7, 960 (2000) - die meisten Proteine derselben Proteinfaltung haben dieselbe (oder eine von zwei) Funktionen Kenntnis des “folds” ermöglicht oft Funktionszuordnung! “fold prediction” alleine ist bereits sehr wertvoll.
Proteinstrukturmodellierung für Structural Genomics Protein structure modeling for structural genomics. R. Sánchez et al. Nat. Struct. Biol. 7, 986 - 990 (2000) Grad an Sequenzidentität zwischen den bekannten Proteinstrukturen und den Proteinen von M. Genitalium. Für 333 von 479 Sequenzen konnte mindestens für ein Stück von 30 Residuen ein Modell erstellt oder ein Fold zugeordnet werden.
Genomweite Strukturmodellierung R. Sánchez et al. Nat. Struct. Biol. 7, 986 - 990 (2000) Effekt des Wachstums der PDB-Datenbank auf die Zahl der Protein des Bakteriums M. Genitalium, deren Fold und Struktur im jeweiligen Jahr vorhergesagt werden konnte. Homologie-Modellierung ist nicht aufwendig, dauert pro Struktur nur wenige Minuten. Akkurate Modellierung von Loops und Seitenketten kann jedoch erheblich aufwendiger sein. Grün: Proteine mit Modell oder fold assignment aus PSI-BLAST für mindestens 30 ihrer Residuen. Blau: nur Modell Rot: Anteil der Residuen des Genoms, die in Modell oder fold assignment vorkommen.
Schliesse von Struktur auf Funktion? From structure to function: Approaches and limitations J. M. Thornton et al. Nat. Struct. Biol. 7, 991 (2000)
Faltung homologe Superfamilie Funktion From structure to function: Approaches and limitations J. M. Thornton et al. Nat. Struct. Biol. 7, 991 (2000) Verteilung homologer Superfamilien in CATH Klassifizierung von Proteinstrukturen. Obwohl manche Folds sehr unterschiedliche Funktionen ausüben können, enthalten 556 Folds jeweils nur eine homologe Superfamilie.
Faltung homologe Superfamilie Funktion From structure to function: Approaches and limitations J. M.Thornton et al. Nat. Struct. Biol. 7, 991 (2000) Konservierung von Enzymfunktion (durch EC-Nummer definiert) innerhalb einer homologen Superfamilie ist relativ gut erfüllt. Dennoch gibt es eine Reihe von absoluten Ausnahmen. Ähnlichkeit der Enzymfunktion
Faltung homologe Superfamilie Funktion From structure to function: Approaches and limitations J. M.Thornton et al. Nat. Struct. Biol. 7, 991 (2000) Diversität der Enzymfunktion in der Familie der Typ1- Aspartat-Aminotransferasen: gezeigt sind die verschiedenen EC-Klassifizierungen von Mitgliedern dieser Superfamilie. Dies ist ein Beispiel für eine der wenigen Superfamilien, bei denen die Zuordnung Fold Funktion nicht eindeutig ist.
Aktives Zentrum der Aspartat Proteasen From structure to function: Approaches and limitations J. M.Thornton et al. Nat. Struct. Biol. 7, 991 (2000) Kristallstruktur des menschlichen Pepsins. Beide Domänen steuern Residuen für aktives Zentrum bei.
Aktives Zentrum der Aspartat Proteasen From structure to function: Approaches and limitations J. M.Thornton et al. Nat. Struct. Biol. 7, 991 (2000) Superposition der Residuen des aktiven Zentrums in 18 unterschiedlichen Aspartat-Protease Proteinfamilien das aktive Zentrum der Aspartat-Protease kann durch die Position von 8 Atomen beschrieben werden.
Genomweite Sequenzanalyse bzw. Sequenzvergleich:Auswahl der Target-Proteine Completeness in structural genomicsD. Vitkup et al. Nat. Struct. Biol. 8, 559 (2001) Genauigkeit der CASP Proteinstrukturen als Funktion der Sequenzidentität von Ziel und Vorlage. Sobald die Identität unter 30% sinkt, nimmt die Abweichung der Modelle von der korrekten exp. Struktur schnell zu.
Korrektheit von Alignments Completeness in structural genomicsD. Vitkup et al. Nat. Struct. Biol. 8, 559 (2001) Die Hauptursache für diesen Effekt sind Fehler im Alignment von Zielprotein und Vorlage. Hier ist der Anteil der korrekt alignierten Residuen gezeigt (bewertet anhand der 3D-Struktur).
Strukturelle Abdeckung der Sequenzdatenbanken Completeness in structural genomicsD. Vitkup et al. Nat. Struct. Biol. 8, 559 (2001) Zahl an (Struktur-)Modellen, die korrekt erzeugt werden können als Funktion der Sequenzidentität (x-Achse) und des passenden Sequenzabschnitts (y-Achse). Der rechte-obere Quadrant umfasst 19% aller Proteine in Swissprot+TrEMBL, für die eine zuverlässige Vorlage in der PDB-Datenbank existiert.
Strukturelle Information für gesamte Genome Completeness in structural genomics. Vitkup et al. Nat. Struct. Biol. 8, 559 (2001)
Strukturelle Abdeckung der ras-Proteinfamilie Ras-Proteine in Hefe. Der Abstand zwischen den Proteinen entspricht 100% - Sequenzidentität. Mit 1 Struktur (YPT6) kann man alle Proteine aufgrund von 20% Identität modellieren (grüner Kreis), mit 5 Strukturen alle mit 30% Identität (rote Kreise). Completeness in structural Genomics. D. Vitkup et al. Nat. Struct. Biol. 8, 559 (2001)
Wie viele Proteinstrukturen werden benötigt? Geplante Modellierung aller Nichtmembran-proteine. Completeness in structural Genomics. D. Vitkup et al. Nat. Struct. Biol. 8, 559 (2001)
Wie viele Strukturen werden praktisch benötigt? Wie gut ist die strukturelle Abdeckung, wenn man Erfolgsraten von 100% (1:1) bis runter zu 10% (1:10) für die Kristallisationsprojekte ansetzt? Man kann auch für geringere Erfolgsraten eine ähnlich gute Abdeckung erwarten! Completeness in structural Genomics. D. Vitkup et al. Nat. Struct. Biol. 8, 559 (2001)
Auswahl der zu kristallisierenden Proteine Blau: optimale Auswahl der Targetproteine Grün: Targetproteine werden zufällig ausgewählt. Man benötigt 7 x mehr Strukturen um 90% Abdeckung zu erreichen. Rot: Auswahl ebenfalls zufällig unter der Bedingung, dass die Ähnlichkeit zu allen anderen Strukturen < 30% liegt. Completeness in structural Genomics. D. Vitkup et al. Nat. Struct. Biol. 8, 559 (2001)
Genomweite Sequenzanalyse bzw. Sequenzvergleich Etwa die Hälfte aller Sequenzen und damit etwa ein Viertel aller Residuen in bekannten Genomen kann einer der 2000 bekannten Pfam Proteinfamilien zugeordnet werden. Daher erwarten wir ca. 8000 Proteinfamilien. Für die strukturelle Abdeckung der 2000 bekannten Proteinfamilien zu 90% sind etwa 4000 Proteinstrukturen notwendig. Damit sind bei optimaler Auswahl der Targetproteine 16000 Strukturbestim-mungen notwendig. Completeness in structural Genomics. D. Vitkup et al. Nat. Struct. Biol. 8, 559 (2001)
„New view of protein folding“: Faltung entlang trichterähnlichen Energielandschaften Bryngelson, Wolynes, PNAS (1987) Gradient Rauhigkeit beschleunigt bremst Faltung Faltung “Frustration” Brooks, Gruebele, Onuchic, Wolynes, PNAS 95, 11037 (1998)
Simulation des Faltungsprozesses Wie lang dauert Proteinfaltung? Welche Zeitskala können MD-Simulationen abdecken? Kann man einen Protein-Faltungsprozess simulieren?
Faltungs-Simulationen Kann man einen Faltungsprozess mit MD-Simulationen simulieren? 1998 1 s Simulation der 36-Residuen des Villin-Fragments exp. Faltungszeit: zwischen 10 – 100 s, Tm = 70 C - enthält 3 kurze Helices (NMR), die durch Loop und Schleife verbunden sind - dicht gepackter hydrophober Kern 4 Monate CPU Zeit auf 256 Prozessor Cray T3D und T3E
Faltung des Villin-Fragments entfaltet teilweise gefaltet native Strukturen Vergleich der nativen Struktur (rot) und des stabilsten clusters (blau) Duan & Kollman, Science 282, 740 (1998)
Faltung des Villin-Fragments (A) relativer Helix-Anteil (C) Gyrationsradius und RMSD von nativer Struktur (B) relativer nativer Anteil (D) freie Solvatationsenergie (Eisenberg-Parameter) Duan & Kollman, Science 282, 740 (1998)
Zusammenfassung - Proteinstruktur ist Schlüssel zum Verständnis mechanistischer Details der Proteinfunktion - ab initio Vorhersage der Proteinstruktur durch Faltungssimulationen ist noch sehr problematisch; funktioniert nur für kurze Proteine
Fold Optimierung • Einfache Gittermodelle (HP-Modelle) • Zwei Sorten von Seitenketten: hydrophob und polar • 2-D oder 3-D Gitter • Treibende Kräfte: hydrophober Kollaps – es ist günstig, Kontakte zwischen hydropoben Seitenketten zu bilden • Bewertung = Anzahl an HH Kontakten
HP-Gittermodelle Ken Dill ~ 1997 Vorteil solch einfacher Modelle: man kann den Konformationsraum systematisch absuchen.