Download

1 / 53
530 likes | 628 Views
Universidade Federal de Ouro Preto (UFOP) Programa de Pós-Graduação em Ciência da Computação (PPGCC). Reconhecimento de Padrões Tipos de Aprendizagem. David Menotti, Ph.D. http ://www.decom.ufop.br/menotti. Objetivos. Introduzir diferentes tipos de aprendizagem Supervisionada

E N D
Universidade Federal de Ouro Preto (UFOP) Programa de Pós-Graduação em Ciência da Computação (PPGCC) Reconhecimento de PadrõesTipos de Aprendizagem David Menotti, Ph.D. http://www.decom.ufop.br/menotti
Objetivos • Introduzir diferentes tipos de aprendizagem • Supervisionada • Métodos paramétricos e não paramétricos. • Não Supervisionada • Incremental • Com Reforço
Aprendizagem Supervisionada • Alguém (um professor) fornece a identificação (rótulos) de cada objeto da base de dados. • Métodos Paramétricos: Assumem que a distribuição dos dados é conhecida(distribuição normal por exemplo) • Métodos Não-Paramétricos: Não consideram essa hipótese.
Aprendizagem Supervisionada • Em muitos casos não se tem conhecimento da distribuição dos dados. • Consequentemente, utilizar um método paramétrico pode não ser adequado. Distribuição Normal
Aprendizagem Supervisionada • Um algoritmo não-paramétrico para aprendizagem supervisionada é o k-NN (kNearest Neighbor). • Consiste em atribuir a um exemplo de teste x a classe do seu vizinho mais próximo.
k-NN • Significado de k: • Classificar x atribuindo a ele o rótulo representado mais frequentemente dentre as k amostras mais próximas. • Contagem de votos. • Uma medida de proximidade bastante utilizada é a distância Euclidiana:
Distância Euclidiana x = (2,5) 1.41 y = (3,4)
k-NN: Um Exemplo A qual classe pertence este ponto? Azul ou vermelho? Calcule para os seguintes valores de k: k=1 não se pode afirmar vermelho – 5,2 - 5,3 k=3 vermelho – 5,2 - 5,3 - 6,2 k=5 4 k=7 azul – 3,2 - 2,3 - 2,2 - 2,1 3 2 1 A classificação pode mudar de acordo com a escolha de k. 1 2 3 4 5 6 7 8
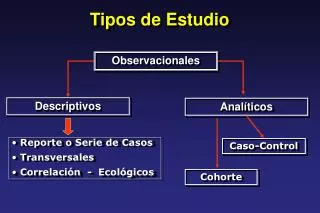
Matriz de Confusão • Matriz que permite visualizar as principais confusões do sistema. • Considere um sistema com 3 classes, 100 exemplos por classe. Erros de classificação 100% de classificação 10 exemplos de C1 foram classificados como C2
Exercício • Implementar em C um kNN. • Mostrar a taxa de reconhecimento do sistema para k= {1,3,5,7} • Mostrar a matriz de confusão. • Analisar o impacto da base de aprendizagem na taxa de reconhecimento.
Aprendizagem Não-Supervisionada • O que pode ser feito quando se tem um conjunto de exemplos mas não se conhece as categorias envolvidas?
Como classificar esses pontos? Por que estudar esse tipo de problema?
Aprendizagem Não-Supervisionada • Primeiramente, coletar e rotular bases de dados pode ser extremamente caro. • Ex: Gravar voz é barato, mas rotular todo o material gravado é caro. • Segundo, muitas vezes não se tem conhecimento das classes envolvidas. • Trabalho exploratório nos dados(ex. Data Mining.)
Aprendizagem Não-Supervisionada • Pré-classificação: • Suponha que as categorias envolvidas são conhecidas, mas a base não está rotulada. • Pode-se utilizar a aprendizagem não-supervisionada para fazer uma pré-classificação, e então treinar um classificador de maneira supervisionada.
Clustering • É a organização dos objetos similares (em algum aspecto) em grupos. Quatro grupos (clusters)
Cluster • Uma coleção de objetos que são similares entre si, e diferentes dos objetos pertencentes a outros clusters. • Isso requer uma medida de similaridade. • No exemplo anterior, a similaridade utilizada foi a distância. • Distance-based Clustering
k-Means Clustering • É a técnica mais simples de aprendizagem não supervisionada. • Consiste em fixar k centróides (de maneira aleatória), um para cada grupo (clusters). • Associar cada indivíduo ao seu centróide mais próximo. • Recalcular os centróides com base nos indivíduos classificados.
Algoritmo k-Means • Determinar os centróides • Atribuir a cada objeto do grupo o centróide mais próximo. • Após atribuir um centróide a cada objeto, recalcular os centróides. • Repetir os passos 2 e 3 até que os centróides não sejam modificados.
k-Means – Um Exemplo Objetos em um plano 2D
k-Means – Um Exemplo Passo 1:Centróides inseridos aleatoriamente
k-Means – Um Exemplo Passo 2: Atribuir a cada objeto o centróide mais próximo
k-Means – Um Exemplo Passo 3: Recalcular os centróides
k-Means – Um Exemplo Impacto da inicialização aleatória.
k-Means – Um Exemplo Fronteira Diferente Impacto da inicialização aleatória
k-Means – Inicialização • Importância da inicialização. • Quando se têm noção dos centróides, pode-se melhorar a convergência do algoritmo. • Execução do algoritmo várias vezes, permite reduzir impacto da inicialização aleatória.
k-Means – Um Exemplo 4 Centróides
y y x x Calculando Distâncias • Distância Euclidiana • Manhattan (City Block)
Calculando Distâncias • Minkowski • Parâmetro r • r = 2, distância Euclidiana • r = 1, City Block
Calculando Distâncias • Mahalanobis • Leva em consideração as variações estatísticas dos pontos. Por exemplo ser x e y são dois pontos da mesma distribuição, com matriz de covariância C, a distância é dada pela equação • Se a matriz C for uma matriz identidade, essa distância é igual a distância Euclidiana.
A Importância das Medidas de Distâncias • Suponha que dois exemplos pertencem ao mesmo cluster se a distância Euclidiana entre eles for menor que d. • É obvio que a escolha de d é importante. • Se d for muito grande, provavelmente teremos um único cluster, se for muito pequeno, vários clusters.
A Importância das Medidas de Distâncias • Nesse caso, estamos definido d e não k.
Critérios de Otimização • Até agora discutimos somente como medir a similaridade. • Um outros aspecto importante em clustering é o critério a ser otimizado. • Considere um conjunto composto de n exemplos, e que deve ser dividido em c sub-conjuntos disjuntos . • Cada sub-conjunto representa um cluster.
Critérios de Otimização • O problema consiste em encontrar os clusters que minimizam/maximizam um dado critério. • Alguns critérios de otimização: • Soma dos Erros Quadrados. • Critérios de Dispersão
Soma dos Erros Quadrados • É o mais simples e usado critério de otimização em clustering. • Seja ni o número de exemplos no cluster Di e seja mi a média desse exemplos • A soma dos erros quadrados é definida
Soma dos Erros Quadrados Je = pequeno Je = grande Je = pequeno Adequado nesses casos - Separação natural Não é muito adequado para dados mais dispersos. Outliers podem afetar bastante os vetores médios m
Critérios de Dispersão • Vetor médio do cluster i • Vetor médio total • Dispersão do cluster i • Within-cluster • Between-cluster
Critérios de Dispersão • Relação Within-Between Caso ideal Alto between (Sb) Clusters distantes um do outro. Baixo within (Sw) (boa compactação)
Critérios de Dispersão Caso não ideal Baixo between (Sb) Baixa distância entre os clusters. Clusters dispersos Alto within
Critérios de Dispersão • Podemos entender melhor os critérios de dispersão analisando o seguinte exemplo:
Diferentes clusters para c=2 usando diferentes critérios de otimização Erro Quadrado Sw Relação Sw/Sb
Algumas Aplicações de Clustering • Marketing: Encontrar grupos de consumidores com comportamento similares • Biologia: Classificar grupos de plantas e animais. • Bibliotecas: Organização de livros. • Administração: Organização de cidades, classificando casas de acordo com suas características. • WWW: Classificação de conteúdos.
Problemas • Vetores de característica muito grandes: tempo de processamento elevado. • Definição da melhor medida de distância: Depende do problema. As vezes é difícil, especialmente quando se trabalha com grandes dimensões. • O resultado do clustering pode ser interpretado de diferentes maneiras.
k-Means - Simulação • Um applet java para a simulação do k-Means pode ser encontrado na seguinte URL: http://www.elet.polimi.it/upload/matteucc/Clustering/tutorial_html/AppletKM.html
Aprendizagem Incremental • Também conhecida com aprendizagem on-line. • Interessante quando a aquisição de dados é difícil e cara. • Pequenos lotes de dados com o decorrer do tempo. • Podem não estar disponível em um futuro próximo.
Aprendizagem Incremental • Isso torna necessário ter um classificador que aprenda incrementalmente. • Processo incremental genérico:
Aprendizagem Incremental • Dilema da Estabilidade-Plasticidade: • Aprender novas informações sem esquecer aquelas aprendidas anteriormente • Tipos clássicos de redes neuronais, tais como MLP não possuem essa propriedade. • Catastrophic forgetting (quando novos dados são apresentados, aqueles aprendidos anteriormente são esquecidos).
Aprendizagem Incremental • Um algoritmo de aprendizagem incremental deve possuir as seguintes propriedades: • Aprender a partir de novos dados. • Não necessitar dos dados antigos. • Preservar conhecimento adquirido. • Acomodar novas classes, introduzidas com os novos dados.
Aprendizagem Incremental • Quais classificador tem essas características? • SOM (Self Organization Map) • ???
Aprendizagem por Reforço ART (Adaptative Resonance Theory) Aprendizagem não supervisionada