Download
1 / 33
330 likes | 641 Views
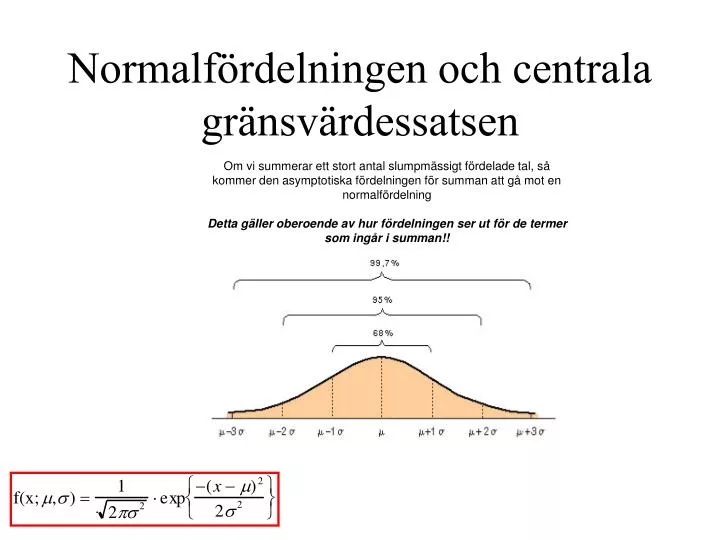
Normalfördelningen och centrala gränsvärdessatsen. Om vi summerar ett stort antal slumpmässigt fördelade tal, så kommer den asymptotiska fördelningen för summan att gå mot en normalfördelning Detta gäller oberoende av hur fördelningen ser ut för de termer som ingår i summan!!.

E N D
Normalfördelningen och centrala gränsvärdessatsen Om vi summerar ett stort antal slumpmässigt fördelade tal, så kommer den asymptotiska fördelningen för summan att gå mot en normalfördelning Detta gäller oberoende av hur fördelningen ser ut för de termer som ingår i summan!!
Felet i medelvärdet Det vill säga standardavvikelsen hos normalfördelningen I fråga (uppskattad med variansen av datapunkterna) dividerad med kvadratroten ur antalet mätvärden). “De stora talens välsignelse”
Statistisk signifikans • Resultatet av en mätning (observation) sägs vara statistiskt signifikant om det är osannolikt att resultatet beror på slumpen. • Tex: • Sannolikheten att det inträffat på grund av slumpen är mindre än 0,05 (dvs 1 på 20) • Tex: • Sannolikheten att det inträffat på grund av slumpen är mindre än 0,01 (dvs 1 på 100)
Men kom ihåg!! • Sannolikheten att det inträffat på grund av slumpen är mindre än 0,05 (dvs 1 på 20) • En gång på 20 är det ”signifikant” på grund av slumpen!!!!!!!!!!! • Signifikansnivån är mycket viktig!! • 0,05, 0.001, 10-6 …..
Olika sannolikheter • Om man kan anta på goda grunder att en viss händelse sker kallas det teoretisk sannolikhet. • Om man baserar sannolikheten på observerade händelser kallas det relativ frekvenssannolikhet • Om man baserar sannolikheten på erfarenhet och intuition kallas det subjektiv sannolikhet
Sannolikhetsfördelningen för summan av två tärningar Utfall Kombinationer antal Sannolikhet 1+1 1 1/36 1+2, 2+1 2 2/36 1+3, 3+1, 2+2 3 3/36 1+4, 4+1, 2+3, 3+2 4 4/36 1+5, 5+1, 2+4, 4+2, 3+3 5 5/36 1+6, 6+1, 2+5, 5+2, 3+4, 4+3 6 6/36 2+6, 6+2, 3+5, 5+3, 4+4 5 5/36 3+6, 6+3, 4+5, 5+4 4 4/36 4+6, 6+4, 5+5 3 3/36 5+6, 6+5 2 2/36 12 6+6 1 1/36
Bakgrundsfaktorer som ger falsk korrelation • Exempel: Under vintern säljs mindre glass, sker fler benbrott, dricks mer glögg, säljs fler skidresor och fler åker buss till jobbet än på sommaren. Men det är väl ingen som drar slutsatsen att det är ökad bussåkning som ger upphov till ökad glöggkonsumtion. Det beror mer på det kalla vädret.
Möjliga förklaringar för en korrelation • Statistisk fluktuation (se tabell 7.3) • Bakomliggande faktorer (tex väder etc) • En variabel beror av den andra (ett kausalt samband)
Kausalitet • En korrelation mellan två variabler kan indikera en kausalitet (en variabel beror av den andra) men inte ensam bevisa att man har en kausalitet. • En mängd andra undersökningar behövs!
Riktlinjer för att visa kausalitet • Kontroller att korrelationen existerar även när andra parametrar varieras • Kontrollera att korrelationen förstärks då en misstänkt parameter förstärks • Om effekten kan orsakas av någon känd effekt, kontrollera att effekten finns kvar då man tagit hänsyn till den kända effekten. • Försök att göra ett experiment • Försök finna en fysisk orsak till korrelationen
Ex. hur man visade att rökning orsakade lungcancer • Observerad korrelation mellan rökning och lungcancer för alla typer av människor • Man fann att för människor med lika förutsättningar att icke rökare hade mer sällan lungcancer än rökare • Folk som rökte mycket och länge hade högre chans att få luncancer • När man korrigerade för kända orsaker till lungcancer som tex radon hade rökare fortfarande högre frekvens än icke rökare • Man gjorde djurförsök och fann att de ”rökande” fick lungcancer • Biologer studerade cellkulturer och fann att röken orsakade mutationeroch att det inte fanns någon genetisk faktor
Medelvärdet hos en population Medelvärdet för fem basketspelare är 242,4 pound Vi delar upp de fem i så många samplestorlekar som möjligt
Egenskaper • Medelvärdet är detsamma för de olika fördelningarna • Spridningen blir mindre ju större sample
Samplemedelvärden för större populationer • Populationsmedelvärdet (m) på samtliga personer i populationen är det sanna värdet. • Ett urval (sample) med en del av populationen kommer att ha ett medelvärde (x) som skiljer sig något från populationsmedelvärdet (m) • Men medelvärdet för en mängd olika samples kommer att vara normalfördelade med ett medelvärde nära m
Andelar av en population • För en ja/nej fråga har man bara två svar och vi har att en andel av populationen • Tex p= 550/1100 = 0,50 • För en delmängd (sample) av populationen har vi p = 50/100 • Standardavvikelsen hos p är ^
95% konfidensintervall • Uppskatta ”felmarginalen”,E, för 95% KI • E=1,96s/ n (s= standardavvikelsen för samplet) • x - E < m < x + E • Betyder att 95% av alla samplemedelvärden ligger inom intervallet
95% konfidensintervall för andelar av en population • Felmarginalen, E, för 95% konfidensintervallet är:
Hypotesprövning • Nollhypotesen H0 är den man testar • Alternativa hypotesen Ha antar att parametern som testas avviker från H0 • Definitionen av hypoteserna skall bestämmas innan man utför testen!!!
Hypotestestning • Man behöver: • 1. Det antagna värdet för populationsparametern (m) eller p • 2. Medelvärdet x eller p • 3. Samplestorleken, n • 4. Standardavvikelsen för populationen, s, eller för stora samples standardavvikelsen för samplet, s ^
P-värdet • P-värdet för en hypotes om en parameter är sannolikheten att ett sample minst lika extremt som det observerade, under antagandet att nollhypotesen är sann.
Fel i hypotesprövningen H0 sann H0 falsk Förkasta H0 Feltyp 1 Korrekt Acceptera H0 Korrekt Feltyp II Vid en signifikansnivå på 0,05 kommer vi att förkasta H0 i 5% av fallen. Signifikansnivån är sannolikheten för Feltyp 1