Download
1 / 11
110 likes | 227 Views
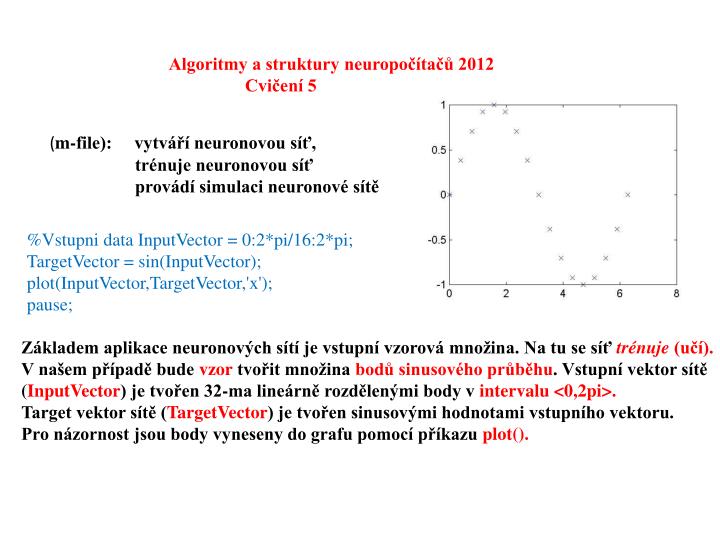
Algoritmy a struktury neuropočítačů 2012 Cvičení 5. ( m-file): vytváří neuronovou síť, trénuje neuronovou síť provádí simulaci neuronové sítě. %Vstupni data InputVector = 0:2*pi/16:2*pi; TargetVector = sin(InputVector);

E N D
Algoritmy a struktury neuropočítačů 2012 Cvičení 5 (m-file): vytváří neuronovou síť, trénuje neuronovou síť provádí simulaci neuronové sítě %Vstupni data InputVector = 0:2*pi/16:2*pi; TargetVector = sin(InputVector); plot(InputVector,TargetVector,'x'); pause; Základem aplikace neuronových sítí je vstupní vzorová množina. Na tu se síť trénuje (učí). V našem případě bude vzor tvořit množina bodů sinusového průběhu. Vstupní vektor sítě (InputVector) je tvořen 32-ma lineárně rozdělenými body v intervalu <0,2pi>. Target vektor sítě (TargetVector) je tvořen sinusovými hodnotami vstupního vektoru. Pro názornost jsou body vyneseny do grafu pomocí příkazu plot().
%Vytvoreni objektu neuronove site PR = minmax(InputVector); Layers = [2 1]; TransFcns = {'logsig' 'purelin'}; BTF = 'traingdx'; BLF = 'learngdm'; PF = 'mse'; net = newff(PR,Layers,TransFcns,BTF,BLF,PF); pause; Vytvoření objektu neuronové sítě. Dopředná NN bez zpětných vazeb ---- newff() vstupní proměnné: PR - udává rozsah vstupních hodnot intervalem minimálních a maximálních hodnot vstupů. Layers - udává počty neuronů v jednotlivých vrstvách. Počet vrstev není omezen. (Principielně si vystačíme vždy se dvěma vrstvami.) TransFcns - udává přenosové funkce neuronů jednotlivých vrstev. BTF - udává název trénovací funkce sítě (beachtraining). BLF - udává název lerning funkce sítě (steptraining). PF - udává název funkce pro výpočet chyby při trénování.
Do proměnné net se uloží data vytvořeného objektu NN. Objekt kóduje veškerá paradigmata NN. Jsou zde uloženy informace o topologii, přenosových funkcích, chybových funkcích, hodnoty vah, prahů, ... Datovou strukturu objektu NN zobrazíte zadáním názvu proměnně net a potvrdíte klávesou ENTER. %Inicializace net = init(net); pause; Během inicializace dochází k výchozímu nastavení vah a prahů NN. Použitá inicializační metoda se uloží v proměnných: • net.initFcn • net.initParam • net.layers{i}.initFcn • net.inputWeights{i}.initFcn • net.layerWeights{i,j}.initFcn Inicializace se provede implicitně již při tvorbě NN, v našem případě je zbytečná.
Vlastní proces trénování se spouští pomocí příkzu train(). Vstupními a výstupními proměnnými jsou: • net - název objektu sítě, která se má trénovat. • Naučenou síť lze uložit do nové proměnné - viz výstupní data příkazu net(). • InputVector - vstupní vektor dat vzorové množiny. • TargetVector - vektor požadovaných hodnot dat vzorové množiny. • tr - [training record] data reprezentující průběh trénovacího procesu. Trénovací metoda a parametry trénování jsou uloženy v objektu net v proměnných net.trainFcn a net.trainParam. Během trénování se postupně vykresluje chybová trénovací křivka. Ta ukazuje, jak postupně klesá chybová funkce trénování. %Trenovani site [net,tr] = train(net,InputVector,TargetVector); pause;
Simulace NN je natrénovaná, je nutné ověřit, jak se natrénovala. K simulaci sítě slouží příkaz sim(). Vstupními a výstupními proměnnými jsou: net- jméno objektu sítě, pomocí které se má simulace provést. InputVector- vstupní data simulace (definiční obor simulace). Simulujeme přesně data, na která byla síť naučena. OutputVector- výstupní data simulace (obor hodnot simulace). %Simulace [OutputVector] = sim(net,InputVector); subplot(2,1,1); plot(InputVector,TargetVector,'x-'); subplot(2,1,2); plot(InputVector,OutputVector,'x-'); Abychom mohli posoudit, jak se NN naučila zadaná vzorová data, jsou jak vstupní vzorová data, tak výstupní simulovaná vykreslena do společného grafu:
Nastavení parametrů trénování NN se nenaučila dobře . Stále generuje výstupy s velkou chybou. Problém je v nastavení trénovacích parametrů. Po ukončení trénování stále ještě klesala chybová funkce (slide 5). Změníme proto trénovací parametry. Ty jsou uloženy v datové struktuře objektu net. Před příkazem trénování [net,tr] = train(net,InputVector,TargetVector); změňte následující parametry učení: net.trainFcn - udává, jaká trénovací funkce se má použít. K dispozici jsou funkce traing, traingda, traingdm, traingdx, trainlm, ... Podrobnosti o trénovacích funkcích naleznete v help-u. My jsme si zvolili traingdx. Udělali jsme tak již při vytváření objektu NN. net.trainParam.epochs - udává, kolik epoch se má NN učit. Výchozí hodnota je 100. 100 epoch nestačilo. Zvýšíme tedy tento parametr na 500. net.trainParam.show - udává, jak často se má chybová funkce vykreslovat. Výchozí hodnota je 25. Po každých 25 epochách učení nám MatLab ukáže, jak se síť učí (vykreslením chybové funkce). Tento parametr nemusíme měnit. net.trainParam.lr - [learning rate] udává, jak moc se mají měnit koeficienty vah a prahů v závislosti na chybové funkci. Udává tzv. rychlost učení. Pokuste se experimentovat. Bude-li lr malé, NN se bude učit pomalu. Bude-li lr velké, bude NN při učení oscilovat.
net.trainParam.goal - udává, při jaké hodnotě chybové funkce se má trénování ukončit. S tímto parametrem se pokuste experimentovat. net.trainParam – Vypíše všechny nastavitelné parametry učení. Výsledný průběh trénovací funkce : NN se naučila lépe. Průběh chybové funkce již neklesá. Přesto výstup ze simulace neodpovídá svému vzoru. Je to proto, že máme malou síť (zvolená síť má málo neuronů). Změníme velikost sítě. Ukážeme si, jak zvolit optimální počet neuronů.
Optimalizace počtu neuronů sítě, generalizace 2 neurony v první vrstvě a 1 výstupní neuron pro aproximaci námi zadaných dat nestačí. Změníme počet neuronů v první vrstvě. V části programu upravíme proměnnou Layers=[20 1]; Nová NN bude mít 20 neuronů v první vrstvě a 1 neuron ve výstupní vrstvě. Spustíme upravený skript (m-file). Chybová funkce klesla mnohem více. Experimentujte s koeficienty trénování tak, abyste dosáhli co nejlepší naučenost NN. Příklad průběhu chybové funkce je na následujícím obrázku.
Z tohoto pokusu by vyplývalo, že čím více neuronů v NN použijeme, tím lépe se NN vzorová data naučí. To je pravda. Problém ale nastává, když chceme, aby NN generovala data, na která nebyla naučena. Změníme vstupní vektor simulace. Nebudeme simulovat jen data, na která jsme NN naučili, ale i ta, která NN nezná. Obměna: %Simulace ExtendedInputVector = 0:2*pi/256:2*pi; OutputVector] = sim(net,ExtendedInputVector); subplot(2,1,1); plot(InputVector,TargetVector,'x-'); subplot(2,1,2); plot(ExtendedInputVector,OutputVector,'x-'); Z následujícího obrázku plyne, že v bodech, které nebyly součástí trénovací databáze, odpovídá NN chybně. Svědčí to o tom, že je NN předimenzovaná. 20 neuronů v první vrstvě je příliš mnoho. Odvoďte, kolik neuronů by bylo optimální? Experimentujte.
Pro jednu periodu sinusovky by měla stačit NN o konfiguraci 1-3-1. Vyplývá to z podstaty neuronu. Jeden neuron je schopen generovat pouze 1 zlom funkce. Funkce sinus má zlomy 3, je zapotřebí 3 neuronů. Příklad simulace NN tvořené 3 skrytými a 1 výstupním neuronem je na obrázku. Výsledek: Se 3-mi neurony jsme dokázali věrohodněji reprodukovat vstupní data, než s původními 20-ti neurony. Úkol: Jak bude simulace vypadat mimo interval <0,2pi>? Jak se bude lišit chování optimální NN (1-3-1) a předimenzované NN (1-20-1) mimo interval <0,2pi>? Jak by se asi chovala síť 1-100-1? Vyzkoušejte.






















