Download
1 / 93
940 likes | 1.14k Views
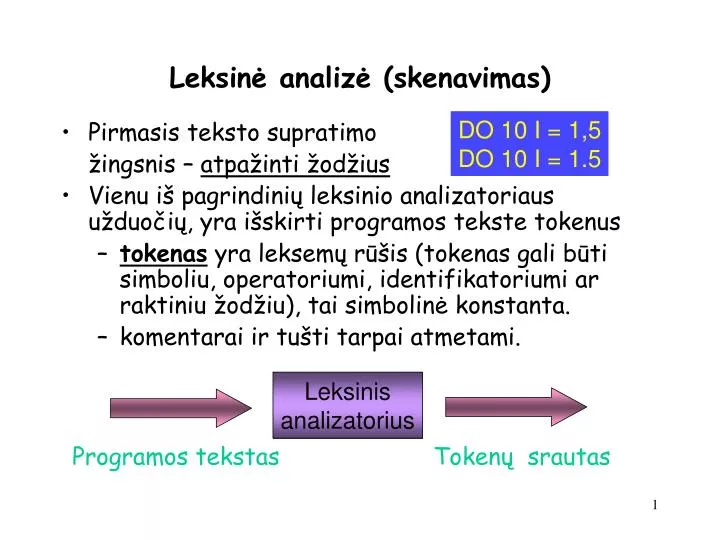
L eksinė analizė ( sk e navimas). DO 10 I = 1 ,5 DO 10 I = 1 .5. Pirmasis teksto supratimo žingsnis – atpažinti žodžius Vienu i š pagrindini ų leksinio analizatoriaus užduočių, yra išskirti programos tekste tokenus

E N D
Leksinė analizė (skenavimas) DO 10 I = 1,5 DO 10 I = 1.5 • Pirmasis teksto supratimo žingsnis – atpažinti žodžius • Vienu iš pagrindinių leksinio analizatoriaus užduočių, yra išskirti programos tekste tokenus • tokenas yra leksemų rūšis (tokenas gali būti simboliu, operatoriumi, identifikatoriumi ar raktiniu žodžiu), tai simbolinė konstanta. • komentarai ir tušti tarpai atmetami. Leksinis analizatorius Programos tekstas Tokenų srautas
Leksinė analizė (skenavimas)Pavyzdys sum = oldsum – value / 100; Leksema sum = oldsum - value / 100 ; Tokenas IDENTIFIER ASSIGN_OP IDENTIFIER SUBTRACT_OP IDENTIFIER DIVISION_OP INIT_LITERAL SEMICOLON
Kaip aprašyti tokenus? • Šablonas – tai taisyklė aprašanti tokeną atitinkančias leksemas. • Šioms taisyklėms aprašyti yra sukurtas specialus žymėjimas – reguliarios išraiškos. • Programavimo kalbos atominiai vienetai – tokenai yra aprašomi reguliariomis išraiškomis • Tarp tokenų reikia mokėti išskirti rezervuotus žodžius, jei kalboje nėra rezervuotų žodžių, leksinė analizė tampa labai sudėtinga • Pavyzdžiui PL/I kalba: IF THEN THEN THEN = ELSE; ELSE ELSE = THEN; • FORTRAN kalba.
Kalba (apibrėžimai) • Terminas alfabetas žymi bet kokią baigtinę simbolių aibę. • Aibė {0, 1} yra binarinis alfabetas • ASCII, EBCDIC yra kompiuteriniai alfabetai • Alfabeto eilutė, tai baigtinė alfabeto simbolių seka. • Kalba, tai bet kokia alfabeto eilučių aibė. • tuščia aibė irgi kalba! • tuščių eilučių aibė {ε} irgi kalba! • visi lietuvių kalbos sakiniai irgi sudaro kalbą.
Operacijos su kalbomis • Kalbų L ir MjunginysLUM={s|sєL arba sєM} • Kalbų L ir MkonkatenacijaLM={st|sєL ir tєM} • Kalbos LKleene uždarinysL*=Ui=0∞Li • tai nulis arba daugiau konkatenacijų • Kalbos Lteigiamas uždarinysL+=Ui=1∞Li • tai viena arba daugiau konkatenacijų • čia L0={ε}, Li=Li-1L.
Kalbų kūrimo pavyzdžiai • Tegu L={A,B,...,Z,a,b,...,z} ir M={0,1,2,...,9} • Kadangi simbolį galima laikyti vienetinio ilgio eilute, aibės L ir M yra baigtinės kalbos. • LUM yra raidžių ir skaičių aibė • LM yra aibė eilučių sudarytų iš raidės po kuria seka skaičius • L4 tai visų keturraidžių eilučių aibė • L* aibė eilučių iš visų raidžių, tame tarpe ir tuščia eilutė ε • L(LUM)* aibė eilučių iš raidžių ir skaičių prasidedanti raide • M+ aibė eilučių sudarytų iš vieno ir daugiau simbolių
Reguliarios išraiškos • Daugumos programavimo kalbų leksinė struktūra gali būti apibrėžta reguliariomis išraiškomis. • Reguliarios išraiškos yra apibrėžiamos virš tam tikro (nustatyto) alfabetoΣ • Dauguma programavimo kalbų alfabetu naudoja ASCII arba Unicode • Jeireyra reguliari išraiška, tuometL(re )yra re sugeneruota kalba (simbolinių eilučių rinkinys)
Reguliarios išraiškos • Reguliari išraiška apibrėžiama tam tikromis taisyklėmis. • tuščia eilutė ε yra reguliari išraiška • simbolis, pavyzdžiui a yra reguliari išraiška • Jei R ir S yra reguliarios išraiškos, tai reguliaria išraiška bus ir • R|S (reiškia R arba S) • RS (konkatenacija) • R* (nulis arba daug R tarpusavio konkatenacijų) • (R) (reguliarias išraiškas galima grupuoti) • Reguliarias išraiškas galima įvardinti: vardas → r
Pavyzdžiai (1) • Reguliari išraiškaa|b reiškia aibę {a,b} • Reguliari išraiška (a|b)(a|b) reiškia aibę {aa,ab,ba,bb} – aibęvisų eilučių iš a ir b, kurių ilgis 2. • Kita šiai aibei atitinkanti reguliari išraiška aa|ab|ba|bb • Reguliari išraiškaa* reiškia aibę {ε,a,aa,aaa,...} • Reguliari išraiška(a|b)* reiškia aibę visų galimų eilučių iš a ir b: {ε,a,b,aa,ab,bb,...} • Kita šiai aibei atitinkanti reguliari išraiška (a*b*)*
Pavyzdžiai (2) • Reguliari išraiškaa|a*b reiškia aibę turinčią a ir eilutes turinčias nulį ar daugiau a ir besibaigiančias b • Reguliari išraiškaba* reiškia aibę {b,ba,baa,baaa,...} • Reguliari išraiškaa*|b reiškia aibę {b,ε,a,aa,aaa,...} • (0|1)*1 reiškia aibę binarinių skaičių besibaigiančių1
Algebrinės reguliarių išraiškų savybės • r|s=s|r – operatorius | komutatyvus • r|(s|t)=(r|s)|t – operatorius | asociatyvus • (rs)t=r(st) – konkatenacija asociatyvi • r(s|t)=rs|rt, (s|t)r=sr|tr – konkatenacija distributyvi operatoriaus | atžvilgiu • εr=r, rε=r – konkatenacijos atžvilgiu, εyra vienetinis elementas • r*=(r|ε)* - ryšys tarp * ir ε • r**=r*
Pavyzdžiai • Paskalio identifikatorių apibrėžianti reguliari išraiška letter → A|B|...|Z|a|b|...|z digit → 0|1|2|3|4|5|6|7|8|9 id → letter(letter|digit)* • Skaičius (pvz.: 1.89E-4) apibrėžianti reguliari išraiška digit → 0|1|...|9 digits → digit digit* optional_fraction → .digits|ε optional_exponent → (E(+|-|ε)digits)|ε num →digits optional_fraction optional_exponent
Sutrumpinimai • R+ (vienasardaugiauR) • a+ aprašo visas eilutes sudarytas iš vieno ar daugiau a simbolių a, aa, aaa, ... • r*=r+|ε, r+=rr* • R? (nulis arba vienas R) • r? =r|ε • [a-z], [A-Z], [0-9] (sutrumpintas simbolių klasės žymėjimas) • [abc] = a|b|c • [a-z]= a|b|...|z • Paskalio identifikatorius [A-Za-z] [A-Za-z0-9]*
Pavyzdys • Skaičius (pvz.: 1.89E-4) apibrėžianti reguliari išraiška, naudojanti sutrumpinimus digit →[0-9] digits → digit+ optional_fraction → (.digits)? optional_exponent → (E(+|-)?digits)? num →digits optional_fraction optional_exponent
Prioritetai • Operatoriai *, + ir ? turi aukščiausią prioritetą. • Konkatenacijos prioritetas žemesnis. • |turi žemiausią prioritetą. • Visi operatoriai yra asociatyvūs iš kairės. • Pavyzdžiui, šių susitarimų dėka išraiška (a)|((b)*(c)) yra ekvivalenti a|b*c • Tai aibė eilučių kurias sudaro arba vienintelis a, arba nulis arba keletas b, po kurių seka vienintelis c.
Leksinių analizatorių istorija • LEX • Leksinis analizatorius sukurtas Lesk ir Schmidt iš Bell Labs 1975 UNIX operacinei sistemai • Šiuo metu egzistuoja daugumoje operacinių sistemų • LEX generuoja leksinį analizatorių - C kalba parašytą programą • LEX nurodytoms reguliarioms išraiškoms įgalina atlikti nurodytas veikas • JLex • sukurtas Elliot Berk iš PrincetonUniversity 1996 • tai Lex generuojantis leksinį analizatorių - Java kalba parašytą programą • JLex pats parašytas Java kalba
JLexveikla Tokenų apibrėžimas Reguliarios Išraiškos JLex Java Failas: ScannerClass (Yylex, leksinę analizę atlieka metodas yylex()) Tokenų atpažinimas Regular expression NFA DFA lexer
JLex aprašymo failo struktūra vartotojo kodas(user code) %% JLex direktyvos(JLex directives) %% reguliarių išraiškų taisyklės(regular expression rules) • Komentarai • prasideda // • arba keletui eilučių /* */ galimi tik pirmose dvejose dalyse
vartotojo kodas • JLex suteikia vartotojui galimybę, esant reikalui, panaudoti savo parašytą programinį kodą. • Vartotojo kodas bus be pakeitimų įrašytas į JLex išvesties failą, pačioje jo pradžioje. • Dažniausiai tai būna: • paketų deklaracijos • import deklaracijos • Papildomos, vartotojo parašytos klasės
JLex direktyvos • Šiame skyriuje pateikiami • makrosų apibrėžimai(macro definitions) –reguliarių išraiškų sutrumpinti pavadinimai • naudojami apibrėžti kas yra raidės, skaičiai ir tušti tarpai. • būsenų deklaracijos • analizatoriaus savybių pasirinkimai • standartinės leksinio analizatoriaus klasės papildymai • Kiekviena JLex direktyva turi būti užrašoma atskiroje eilutėje ir turi pradėti tą eilutę.
Reguliarių išraiškų taisyklės • Šį skyrių sudaro taisyklių rinkinys nurodantis kaip suskaidyti įvesties srautą į tokenus. • Reguliarių išraiškų taisyklės yra sudarytos iš trijų dalių: • būsenų sąrašas (nebūtinas) • reguliari išraiška • susieta veika (Java kodo fragmentai) • Kiekviena veika turi grąžinti reikšmę apibrėžtą %type deklaracijoje esančioje antrojoje JLex aprašo dalyje. • Jei veika nieko negrąžina, einamasis tokenas atmetamas ir leksinis analizatorius dar kartą iškviečia pats save. [<būsenos>] <reg. išraiška> { <veika>}
JLex direktyvos (1) • Direktyva%{...%}leidžia vartotojui įrašyti Java kodą tiesiai į leksinio analizatoriaus klasę. • Direktyvos naudojimo pavyzdys: %{ <kodas> %} • JLex įrašys Java kodą į sukuriamą leksinio analizatoriaus klasę: class Yylex { ... <kodas> ... } • Tai leidžia aprašyti papildomus vidinius leksinio analizatoriaus klasės kintamuosius ir metodus. • Pažymėtina, kad negalima naudoti kintamųjų vardų prasidedančių yy – tokius vardus naudoja pati leksinio analizatoriaus klasė.
JLex direktyvos (2) • Direktyva%init{ ... %init}leidžia vartotojui įrašyti Java kodą tiesiai į leksinio analizatoriaus klasės konstruktorių %init{ <kodas> %init} • JLex įrašys Java kodą į sukuriamą leksinio analizatoriaus klasės konstruktorių: class Yylex { Yylex () { ... <kodas> ... } • Ši direktyva leidžia atlikti papildomą leksinio analizatoriaus klasės inicializaciją.
JLex direktyvos (3) • Makrosų paskirtis: • vieną kartą apibrėžus reguliarią išraišką, toliau atitinkamose vietose galima naudoti tik jos vardą (daugelį kartų). • Praktiškai būtini didesnėms reguliarioms išraiškoms. • Makrosų apibrėžimo formatas: <vardas> = <apibrėžimas> • Makroso vardas yra identifikatorius, t.y. gali būti sudarytas iš raidžių, skaitmenų ir apatinių brūkšnių, bei turi prasidėti raide arba apatiniu brūkšniu. • Makroso apibrėžimas turi būti teisingai užrašyta reguliari išraiška. • Makrosų apibrėžimuose gali būti panaudoti kiti makrosai - {<vardas>}
JLex direktyvos (4) • Leksinių būsenų pagalba kontroliuojamas reguliarių išraiškų atitikimas. • Leksinių būsenų deklaravimo formatas %state state[0][, state[1], state[2], ...] • Leksinės būsenos vardas turi būti identifikatorius. • Pagal nutylėjimą JLex pats deklaruoja vieną būseną - YYINITIAL, kuria sukurtas leksinis analizatorius pradeda leksinę analizę. • Jei būsenų sąrašas nenurodytas, reguliarios išraiškos atitikimas neribojamas. • Jei būsenų sąrašas nurodytas, reguliariai išraiškai bus leidžiama atitikti tik tuomet, jei leksinis analizatorius bus vienoje iš nurodytų būsenų. • Būsenų vardai turi būti unikalūs – tam tikslui patartina juos pradėti didžiaja raide.
JLex direktyvos (5) • JavaCUP– sintaksinio analizatoriaus generatorius Java kalbai buvo sukurtas Scott Hudson iš Georgia Tech universiteto, ir išvystytas Frank Flannery, Dan Wang, ir C. Scott Ananian pastangomis. • Smulkiau apie šį įrankį: http://www.cs.princeton.edu/~appel/modern/java/CUP/ • Suderinamumas su JavaCUPaktyvuojamas sekančia JLex direktyva %cup
Simbolių ir eilučių skaičiavimo direktyvos • Kartais naudinga žinoti kur tekste yra tokenas. Tokeno padėtis nusakoma jo eilutės ir jo pirmojo simbolio eilės numeriu tekste. • Simbolių skaičiavimas aktyvuojamas direktyva“%char” • Sukuriamas kintamasis yychar (leks. analizatoriaus); • jo reikšmė – pirmojoatitikusioje šabloną leksemoje simbolio eilės numeris. • Eilučių skaičiavimas aktyvuojamas direktyva“%line” • Sukuriamas kintamasis yyline; • jo reikšmė – atitikusiosšabloną simbolinės eilutės pirmosios eilutės eilės numeris. • Pavyzdys: “int” { return (new Yytoken(4,yytext(),yyline,yychar,yychar+3)); }
Reguliarių išraiškų taisyklės • Jei nuskaitymo metu simbolinei eilutei atitinka keletas taisyklių, jos skaidymas į tokenus vyksta pagal tą taisyklę, kuri atitinka ilgiausią tokeną. • Jei keletas taisyklių atitinka to pačio ilgio simbolinę eilutę, pasirenkama ta taisyklė, kuri JLex aprašyme yra pirmoji (ankstesnės taisyklės turi aukštesnį prioritetą). • JLex aprašyme reikia numatyti reguliarias taisykles visiems galimiems atvejams. • Jei leksinio analizatoriaus įvestis neatitiks jokiai aprašytai taisyklei, leksinis analizatorius nutrauks darbą. • Galima apsidrausti, JLex aprašymo pabaigoje patalpinus sekančią taisyklę: . { java.lang.System.out.println("Unmatched input: " + yytext()); } • Čia taškas (.) nurodo atitikimą bet kokiai įvesčiai, išskyrus naują eilutę (newline).
Reguliarios išraiškos (1) • JLex alfabetas yra ASCII simboliai nuo 0 iki 127 imtinai. • Šie simboliai yra reguliarios išraiškos patys sau. • Reguliariose išraiškose negalima tiesiogiai naudoti tarpų - tarpas laikomas reguliarios išraiškos pabaiga. • Jei tuščias tarpas reikalingas reguliarioje išraiškoje, jį reikia nurodyti tarp dvigubų kabučių: " " • Sekantys simboliai yra meta simboliai, turintys JLex reguliariose išraiškose specialią reikšmę: ? * + | ( ) ^ $ . [ ] { } " \
Reguliarios išraiškos (2) • ef viena po kitos einančios reguliarios išraiškos reiškia jų konkatenaciją. • e|f vertikalus brūkšnys | nurodo kad atitikti gali arba išraiška e arba f. • \b reiškia Backspace • \n reiškia newline • \t reiškia Tab • \f reiškia Formfeed • \r reiškia Carriage return • \^C reiškia Control character • \c - bet koks simbolis po \ reiškia save patį.
Reguliarios išraiškos (3) • $ žymi eilutės pabaigą. • Jei reguliari išraiška baigiasi $ jos atitikimas tikrinamas tik eilutės pabaigoje (t.y. iš kito galo). • . atitinka bet kokį simbolį išskyrus naują eilutę. • Taigi, ši išraiška ekvivalenti [^\n]. • "..." metasimboliai tampa paprastais simboliais dvigubose kabutėse. • Pažymėsime, kad \" reiškia simbolį " • {vardas} nurodo čia bus išskleistas makrosas su nurodytu vardu. • * pažymi Kleene uždarinį nurodantį nulį ar daugiau reguliarios išraiškos pasikartojimų. • + nurodo vieną ar daugiau reguliarios išraiškos pasikartojimų.Taigi e+ yra ekvivalenti ee* • ? nurodo,kad reguliari išraiška gali būti taikoma arba ne.
Reguliarios išraiškos (4) • (...) skliaustai naudojami reguliarių išraiškų grupavimui. • [...] pažymi simbolių klasę - reguliari išraiška atitinka visiems klasės simboliams. • Jei pirmasis simbolis [...]yra (^), tai nurodo kad reguliari išraiška atitinka visiems simboliams išskyrus nurodytus skliaustuose. • Pavyzdžiui, • [a-z] atitinka visas mažasias raides, • [^0-9] atitinka viską išskyrus skaičius, • [\-\\] atitinka -\, • ["A-Z"] atitinka tris simbolius: A-Z, • [+-] ir [-+] atitinka + ir -.
Pavyzdžiai • “a|b” atitinka a|b bet ne a arba b • ^mainatitiks leksemą“main”tik tuomet kai ji bus eilutės pradžioje. • main$atitiks leksemą“main”tik tuomet kai ji bus eilutės pabaigoje. • [a bc]yra ekvivalentusa|" "|b|c
Susieta veika (action) • Ši veika atliekama kai nurodytas šablonas yra atpažystamas • Veika, tai Java sakiniai (standartiniai) grąžinantys tokenus.
Leksinis analizatorius • JLex taisyklingai parašytą aprašą transformuoja į java programą vardu Yylex. • Ši klasė turi du konstruktorius turinčius vieną argumentą - įvesties srautą (input stream) kuri reikia išskaidyti į tokenus. • Įvesties srautas gali būti atitinkamai arba java.io.InputStream, arba java.io.Reader (pavyzdžiui StringReader). • Konstruktorius java.io.Reader naudojamas jei įvesties sraute gali būti unicode simbolių. • Sekantį tokeną iš įvesties srauto grąžina leksinio analizatoriaus metodas Yylex.yylex(). • Grąžinamos reikšmės tipas yra Yytoken.
Specialūs JLex kintamieji/metodai • yytext() – grąžina simbolinę eilutę kuriai leksinis analizatorius rado atitikmenį (galima nustatyti šios simbolinės eilutės semantinę reikšmę) • t.y. tai tokeno, kurį grąžina yylex() leksema • yylength() – grąžina atitiktos simbolinės eilutės ilgį • yychar – saugo atitiktos eilutės (matched string) pradžios padėtį faile • tokeno pradžia: yychar • tokeno pabaiga: yychar + yylength() • yylex()paprastai grąžinaYytoken klasės egzempliorių, nors galima deklaruoti ir kitą tipą direktyva %type
Tokenai • Paprastai kiekvienas tokenas yra klasės Symbol iš paketo - java_cup.runtime elementas. • Šį paketą eksportuoja analizatorius JavaCUP • Symbol klasėje nustatomi sveiki skaičiai atitinkantys kiekvienam tokenui. • Pavyzdžiui, čia aprašytos sveiko tipo konstantos, tokios kaip sym.ID, sym.IF
Reguliarios išraiškos pavyzdys reguliariIšraiška{ veika } • Pavyzdys: {IDENTIFIER}{ System.out.println("ID is ..." + yytext());} • Prasmė: • Pirmuosiuose skliaustuose šablonas, kurio atitikmens ieškome; • antruosiuose skliaustuose kodas, kuris bus vykdomas jei atitikmuo bus rastas.
Makrosų pavyzdžiai • Apibrėžimas (antroji JLex aprašymo dalis): IDENTIFIER = [a-zA-z_][a-zA-Z0-9_]* LETTER=[A-Za-z_] DIGIT=[0-9] WHITESPACE= [ \t\n] ALPHA_NUMERIC={LETTER}|{DIGIT} • Panaudojimas (trečioji JLex aprašymo dalis): {IDENTIFIER} {return new Token(ID, yytext());
Būsenų deklaracijos (1) • Kai kurioms simbolinėms eilutėms atitikmuo turi būti ieškomas su skirtingomis reguliariomis išraiškomis. • Taigi reikia turėti galimybę pervesti leksinį analizatorių į įvairias būsenas, kuriose jis funkcionuotų skirtingai, t.y. naudotų kitas reguliarias išraiškas. • Pradėdamas darbą leksinis analizatorius yra būsenoje YYINITIAL. • Jei norime naudoti savo būsenas, aprašome jas antrojoje JLex aprašo dalyje. • Pavyzdžiui: %state COMMENTS • Perėjimui tarp būsenų naudojamas metodas yybegin().
Būsenų deklaracijos (2) • Pavyzdys: <YYINITIAL> "//" {yybegin(COMMENTS);} <COMMENTS> [^\n] {} <COMMENTS> [\n] {yybegin(YYINITIAL);} • Jei Yylex yra pradinėje YYINITIAL būsenoje ir atpažysta //, tuomet jis pereina į būseną COMMENTS • Jei jis yra būsenoje COMMENTS ir atpažysta bet kokį simbolį išskyrus \n, tuomet jokia veika neatliekama • Jei jis yra būsenoje COMMENTS ir atpažysta \n, tuomet jis grįžta atgal į būseną YYINITIAL
minimal.lex package Example; import java_cup.runtime.Symbol; %% %cup %% ";" { return new Symbol(sym.SEMI); } "+" { return new Symbol(sym.PLUS); } "*" { return new Symbol(sym.TIMES); } "(" { return new Symbol(sym.LPAREN); } ")" { return new Symbol(sym.RPAREN); } [0-9]+ { return new Symbol(sym.NUMBER, new Integer(yytext())); } [ \t\r\n\f] { /* ignore white space. */ } . { System.err.println("Illegal character: "+yytext()); }
import java_cup.runtime.Symbol; • Ši eilutė importuoja klasę Symbol. • Kai sintaksinis analizatorius iškviečia Yylex sekančiam tokenui, Yylex objektas grąžina Symbol klasės egzempliorių.
Symbol klasė • Symbol klasės egzempliorius turi keletą konstruktorių. • "+" { return new Symbol(sym.PLUS); } • Paprasčiausias naudoja tik tokeno eilės numerį (t.y. vieną iš sugeneruotos sym klasės konstantų) • Šioms konstantoms vardus duodame mes patys, o reikšmes priskiria JavaCUP generuodamas sym.java failą. • [0-9]+ { return new Symbol(sym.NUMBER, new Integer(yytext())); } • Sudėtingesnis konstruktorius dar naudoja leksinę reikšmę kurią apibrėžia tam skirtas objektas • čia naudojamas Java objektas • gali būti naudojamas ir mūsų sukurtos klasės objektas
minimal.lex tokenams atitinkantys sveiki skaičiai //---------------------------------------------------- // The following code was generated by CUP v0.10k // Sat Oct 02 09:56:56 EEST 2004 //---------------------------------------------------- package Example; /** CUP generated class containing symbol constants. */ public class sym { /* terminals */ public static final int RPAREN = 6; public static final int error = 1; public static final int PLUS = 3; public static final int NUMBER = 7; public static final int SEMI = 2; public static final int LPAREN = 5; public static final int TIMES = 4; public static final int EOF = 0; }
Anglų kalbos gramatika A sentence is a noun phrase, a verb, and a noun phrase. A noun phrase is an article and a noun. A verb is… An article is… A noun is... <S> ::= <NP> <V> <NP> <NP> ::= <A> <N> <V> ::= loves | hates|eats <A> ::= a | the<N> ::= dog | cat | rat
Gramatikos taikymas • Gramatika yra taisyklių rinkinys nusakantis kaip sukonstruoti sintaksinį medį – aparse tree • Medžio šaknyje (root) patalpinameaukščiausią hierarchijos elementą – t.y. <S> • Gramatikos taisyklės nusako kaip toliau yra pridedami sekantys mazgai - vaikai. • Pavyzdžiui, taisyklė <S> ::= <NP> <V> <NP> parodo kokia tvarka pridedami mazgai <NP>, <V> ir<NP> – t.y. <S> vaikai.
start symbol <S> ::= <NP> <V> <NP> <NP> ::= <A> <N> <V> ::= loves | hates|eats <A> ::= a | the<N> ::= dog | cat| rat a production non-terminalsymbols tokens






















