Download

1 / 13
130 likes | 420 Views
République Algérienne Démocratique et Populaire Ministère de l’Enseignement Supérieur et de la Recherche Scientifique. Une Modélisation des Contraintes dans les Processus Décisionnels de Markov. Hiba Abdelmoumène , Habiba Belleili Laboratoire LABGED, Université Badji Mokhtar

E N D
République Algérienne Démocratique et Populaire Ministère de l’Enseignement Supérieur et de la Recherche Scientifique Une Modélisation des Contraintes dans les Processus Décisionnels de Markov HibaAbdelmoumène, HabibaBelleili Laboratoire LABGED, UniversitéBadjiMokhtar Annaba, Algérie . 1
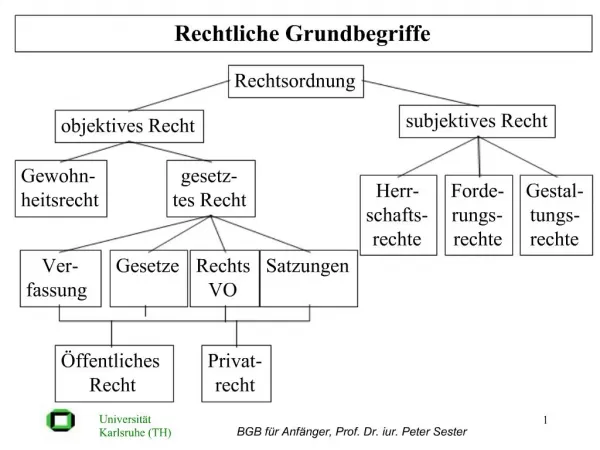
PLAN DE L’EXPOSÉ • Introduction • Description du problème • Modélisation proposée • Conclusion 2
INTRODUCTION • Les processus décisionnels de Markov (MDPs: Markov DecisionProcesses) sont une formalisation mathématique qui permet de modéliser les problèmes de décision séquentiels sous incertitude. Ils intègrent les concepts d’état qui résume la situation de l’agent à chaque instant, d’action qui influence la dynamique de l’état, de récompense qui est associée à chacune des transitions d’état. • Cependant, ces modèles n’intègrent pas d’hypothèse sur les durées des actions ni de contraintes temporelles ou de précédence sur les actions. • Le but de notre travail est la prise en considération des contraintes temporelles et de précédence lors de l’ordonnancement de tâches ayant des durées d’exécution probabilistes 3
Description du problème • Notre problème consiste à la prise en considération des contraintes temporelles et de précédence lors de l’ordonnancement de tâches ayant des durées d’exécution probabilistes. Ce problème a été soulevé par Baki et Bouzidmais aucune modélisation du problème n’a été proposée. En effet, les auteurs ont proposé des algorithmes qui génèrent tous les plans possibles et calculent les coûts de chaque plan avec les utilités respectives de chaque plan. • Notre proposition est différente, car notre objectif est de modéliser le problème en un MDP. • Cette modélisation, que nous voulons représentative du problème soulevé, revient à définir l’ensemble des états, la fonction de transition et la fonction de récompense. • Le MDP du problème ainsi modélisé, sera par la suite soumis à l’un des résolveurs des MDPs. La résolution du MDP nous fournira pour chaque état la politique optimale.
Description du problème Différents plans sont possibles: (t1, t2, t4, t8); (t1, t2, t3, t5, t8); (t1, t2, t3, t6, t7); (t1, t3, t6, t7) une stratégie d’ordonnancement pour compléter la mission avec des coûts réduits en respectant les contraintes 5
Description du problème • Une tâche t est définie par sa fenêtre temporelle, une distribution des probabilités sur ses durées d’exécution, le coût d’exécution associé à chaque durée. • Exemple: t1 <[2,6],(2, 0.6),(3, 0.4), (5,8)> [2,6]: fenêtre temporelle de la tâche t1, 2 est la date de début au plus tôt, 6 est la date de fin au plus tard de t1. (2, 0.6), (3, 0.4): l’exécution de t1 dure 2 unités de temps avec une probabilité de 0.6 et 3 unités de temps avec une probabilité de 0.4. (5,8): 5 représente le coût associé à la durée d’exécution 2 et 8 représente le coût associé à la durée d’exécution 3. • Une tâche t ne peut pas être exécutée que si tous ses prédécesseurs sont exécutés en respectant les contraintes. • Des contraintes de précédence conjonctives et des contraintes de précédence disjonctives sont envisagées. • On suppose que l’ensemble des tâches est connu à l’avance. On ne considère pas les tâches qui viennent dynamiquement. 6
Modélisation proposée • La modélisation de ce problème en un MDP revient à définir l’espace d’états, les actions, la fonction de récompense. Quant aux actions, elles correspondent aux actions de notre problème (tâches), les autres éléments nécessitent une modélisation spécifique au problème à traiter. Construction de l’espace d’états Le problème présente des contraintes temporelles et de précédence conserver la dernière tâche exécutée La tâche peut être exécutée dans différents intervalles d’exécution conserver l’intervalle d’exécution Maintenant, comment peut-on modéliser les contraintes de précédence? 7
Modélisation proposée • Puisque l’état d’un MDP doit être Markovien (résume l’historique), l’idée que nous proposons consiste à l’utilisation d’un état factorisé Etat factorisé dernière tâche exécutée + intervalle d’exécution + variable aléatoire pour chaque tâche. Où chaque variable prend ses valeurs dans: {E: Enable, D: Disable, S: Success, F: Failure} • La construction des intervalles d’exécution possibles de chaque tâche se fait en appliquant à la première tâche toutes les durées possibles et en propageant les durées d’exécution dans le graphe des tâches. 8
Modélisation proposée • Exemple: État de succès: <t2,[4,6],(S,S,E,E,D,D,D,D)> Deux premières tâches: exécution avec succès t3:E;t4:E État d’échec: <t2,[5,11],S,F,E,D,D,D,D,D> • État initial: (’ ’,[start_time,start_time],(E,D,D,…)) • Les états peuvent être classés en état de succès quand les contraintes temporelles sont respectées, état d’échec correspond à une exécution avec violation des contraintes temporelles, état terminal avec succès de la mission et état terminal avec échec de la mission. 9
Modélisation proposée Construction de la fonction de transition • Nous rappelons que notre problème est stochastique à cause des durées probabilistes de chaque action. Ainsi, à partir des distributions de probabilité sur la durée de chaque action on peut aisément calculer les probabilités de transiter d’un état factorisé à un autre. • En effet, la probabilité qu’une tâche t transite d’un état s à un état s’ correspond à la probabilité de l’intervalle d’exécution de s’. Cette probabilité est obtenue à partir des probabilités sur les dates de début d’une tâche t ainsi que les probabilités de ses durées d’exécution. 10
Modélisation proposée La fonction de récompense • La récompense est donnée en se basant sur le coût qui est dans notre cas relatif aux durées d’exécution possibles de chaque tâche. • On distingue état de succès (S), état d’échec partiel (Fp) et état d’échec total (Ft). S, r(s) = scalaire-coût, avec 0 < coût <s calaire État (s) Fp, r(s) = pénalité_Fp-coût, avec pénalité_Fp<0 Ft, r(s) = pénalité_Ft, avec pénalité_Ft < pénalité_Fp< 0 11
CONCLUSION • Le but de ce travail était de prendre en compte les contraintes temporelles et de précédence envisagées lors de l’exécution des tâches ayant des durées d’exécution probabilistes. • Pour ce faire, nous avons proposé de modéliser ce problème en un MDP qui est un formalisme puissant pour représenter les problèmes séquentiels et stochastiques, afin de pouvoir le résoudre et trouver la politique optimale. • La gestion des contraintes et des incertitudes sur les durées d’exécution des actions a nécessité l’amélioration de la modélisation du temps et des actions réalisées usuellement dans les modèles Markoviens. • Actuellement, des expérimentations sont en cours pour tester la résolution de ce MDP , d’autres travaux seront aussi réalisés pour tester le passage à l’échelle de la construction de l’espace d’états et la fonction de transition. 12