Download

1 / 87
990 likes | 1.78k Views
Multiplicación de matrices . Manuel Sánchez Cuenca Manolo Pérez Hernández. Multiplicación de matrices . Nociones básicas sobre matrices Algoritmo secuencial Algoritmo paralelo Submatrices Implementación directa Implementación con submatrices Implementación recursiva Algoritmo de Cannon

E N D
Multiplicación de matrices Manuel Sánchez Cuenca Manolo Pérez Hernández
Multiplicación de matrices • Nociones básicas sobre matrices • Algoritmo secuencial • Algoritmo paralelo • Submatrices • Implementación directa • Implementación con submatrices • Implementación recursiva • Algoritmo de Cannon • Array sistólico • Algoritmo de Fox • Algoritmo DNS • Mapeo de matrices en procesadores
Multiplicación de matrices • Nociones básicas sobre matrices • Algoritmo secuencial • Algoritmo paralelo • Submatrices • Implementación directa • Implementación con submatrices • Implementación recursiva • Algoritmo de Cannon • Array sistólico • Algoritmo de Fox • Algoritmo DNS • Mapeo de matrices en procesadores
Nociones básicas sobre matrices • Array bidimensional de números • Matriz n x m n filas y m columnas Matriz 3 x 4: 1 3 2 2 2 4 6 3 2 7 4 5
Nociones básicas sobre matrices • Suma de matrices Se suman los elementos de la misma posición en ambas matrices: 1 3 2 3 2 3 4 5 5 3 4 1 + 4 1 2 = 7 5 3 1 1 2 1 2 2 2 3 4
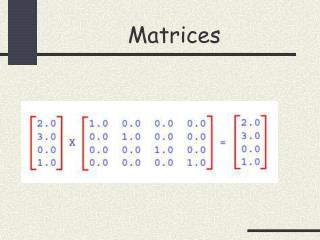
Nociones básicas sobre matrices • Multiplicación de matrices Sean A (n x l) y B (l x m) dos matrices, entonces cada elemento cij de la matriz resultante se calcula como:
Nociones básicas sobre matrices • Ej: • También se puede multiplicar una matriz por una constante multiplicando todos los elementos por dicha constante
Nociones básicas sobre matrices • Multiplicación de una matriz por un vector Desde el momento que un vector es una matriz con una solo fila o una columna, podemos usar el algoritmo de multiplicación de matrices. Entonces, si el vector B es de la forma n x 1 podemos multiplicarlo por la matriz A (m x n) como A x B; y si el vector A es de la forma 1 x n podemos multiplicarlo por la matriz B (n x m) como A x B.
Multiplicación de matrices • Nociones básicas sobre matrices • Algoritmo secuencial • Algoritmo paralelo • Submatrices • Implementación directa • Implementación con submatrices • Implementación recursiva • Algoritmo de Cannon • Array sistólico • Algoritmo de Fox • Algoritmo DNS • Mapeo de matrices en procesadores
Algoritmo secuencial • Por simplicidad, todo el tiempo trabajaremos con matrices cuadradas. • for (i = 0; i < n; i++) { for (j = 0; i < n; j++) { c[i][j] = 0; for (k = 0; k < n; k++) { c[i][j] += a[i][k] * b[k][j] } } } • n3 multiplicaciones y n3 sumas O (n3)
Multiplicación de matrices • Nociones básicas sobre matrices • Algoritmo secuencial • Algoritmo paralelo • Submatrices • Implementación directa • Implementación con submatrices • Implementación recursiva • Algoritmo de Cannon • Array sistólico • Algoritmo de Fox • Algoritmo DNS • Mapeo de matrices en procesadores
Algoritmo paralelo • Podemos basarnos en el código secuencial, ya que los dos bucles externos son independientes en cada iteración. • Con n procesadores podemos obtener O (n2) • Con n2 procesadores O (n) • Estas implementaciones son óptimas en coste, ya que O (n3) = n x O (n2) = n2 x O (n) • Estas cálculos no incluyen el coste de las comunicaciones.
Multiplicación de matrices • Nociones básicas sobre matrices • Algoritmo secuencial • Algoritmo paralelo • Submatrices • Implementación directa • Implementación con submatrices • Implementación recursiva • Algoritmo de Cannon • Array sistólico • Algoritmo de Fox • Algoritmo DNS • Mapeo de matrices en procesadores
Submatrices • Si tenemos muchos menos de n procesadores, cada procesador debe trabajar con un subconjunto de cada una de las matrices submatrices. • Estas submatrices se utilizan como elementos normales, pero teniendo en cuenta que utilizaremos el algoritmo de multiplicación de matrices y de suma de matrices en lugar de la multiplicación y la suma de números implementación recursiva.
Multiplicación de matrices • Nociones básicas sobre matrices • Algoritmo secuencial • Algoritmo paralelo • Submatrices • Implementación directa • Implementación con submatrices • Implementación recursiva • Algoritmo de Cannon • Array sistólico • Algoritmo de Fox • Algoritmo DNS • Mapeo de matrices en procesadores
Implementación directa • Con n2 procesadores, cada procesador calcula un elemento de C, por lo que necesita una fila de A y una columna de B. • Si usamos submatrices, cada procesador deberá calcular una submatriz de C.
Implementación directa • Análisis de comunicaciones Cada uno de los n2 procesadores recibe una fila de A y una columna de B, y devuelve un elemento: • Mediante un broadcast de las dos matrices podemos ahorrar tiempo, por ejemplo en un bus tenemos:
Implementación directa • Análisis de computación Cada procesador realiza n multiplicaciones y n sumas, por lo que tenemos: • Usando una estructura de árbol y n3 procesadores podemos obtener un tiempo de computación de O (log n)
Implementación directa • Cálculo de c00 para matrices de 4x4 y cálculos en estructura de árbol: a00 b00 a01 b10 a02 b20 a03 b30 x x x x + + +
Multiplicación de matrices • Nociones básicas sobre matrices • Algoritmo secuencial • Algoritmo paralelo • Submatrices • Implementación directa • Implementación con submatrices • Implementación recursiva • Algoritmo de Cannon • Array sistólico • Algoritmo de Fox • Algoritmo DNS • Mapeo de matrices en procesadores
Implementación con submatrices • En cualquiera de los métodos se pueden sustituir los elementos de la matriz por submatrices para reducir el número de procesadores • Con submatrices de m x m y s = n/m es como si tuviésemos matrices de s x s con submatrices de m x m en lugar de elementos simples.
Implementación con submatrices • Análisis de comunicaciones Cada uno de los s2 procesadores recibe una fila de submatrices de A y una columna de submatrices de B, y devuelve una submatriz:
Implementación con submatrices Al aumentar el tamaño de las submatrices (y disminuir el número de procesadores) el tiempo de transmitir un mensaje aumenta pero el número de mensajes disminuye, por lo que es posible encontrar un valor óptimo del tamaño de la submatriz. Además, también es posible hacer un broadcast de las dos matrices completas.
Implementación con submatrices • Análisis de computación Cada procesador realiza s multiplicaciones y s sumas de submatrices, una multiplicación de submatrices necesita m3multiplicaciones y m3 sumas y una suma m2sumas, por lo que en resumen, el tiempo de computación es:
Multiplicación de matrices • Nociones básicas sobre matrices • Algoritmo secuencial • Algoritmo paralelo • Submatrices • Implementación directa • Implementación con submatrices • Implementación recursiva • Algoritmo de Cannon • Array sistólico • Algoritmo de Fox • Algoritmo DNS • Mapeo de matrices en procesadores
Implementación recursiva • La división en submatrices sugiere una estrategia recursiva de divide y vencerás, que puede ser especialmente ventajoso en sistemas de memoria compartida. • El proceso de dividir una matriz en submatrices para repartir el trabajo entre otros procesadores debe parar cuando ya no queden procesadores libres. • La ventaja de esta estrategia es que en cada paso de recursión, los datos transmitidos son más pequeños y están más localizados.
Multiplicación de matrices • Nociones básicas sobre matrices • Algoritmo secuencial • Algoritmo paralelo • Submatrices • Implementación directa • Implementación con submatrices • Implementación recursiva • Algoritmo de Cannon • Array sistólico • Algoritmo de Fox • Algoritmo DNS • Mapeo de matrices en procesadores
Algoritmo de Cannon • Este algoritmo y el siguiente son especialmente apropiados para sistemas de paso de mensajes, y la arquitectura de paso de mensajes que más se ajusta a las matrices es una malla. Realmente, aunque la arquitectura física no sea una malla, lógicamente cualquier arquitectura puede representarse como una malla.
Algoritmo de Cannon • Utiliza una malla con conexiones entre los elementos de cada lado (toro) para desplazar los elementos de A hacia la izquierda y los de B hacia arriba. • El algoritmo sigue los siguientes pasos: 1. El procesador Pij tiene los elementos aij y bij.
Algoritmo de Cannon 2. La fila i-ésima de A se desplaza i posiciones a la izquierda, y la columna j-ésima de B se desplaza j posiciones hacia arriba, y todo esto teniendo en cuenta que el elemento que sale por un extremo entra por el otro. Con este paso se consigue que el procesador Pij contenga los elementos aij+i y bi+jj, que son necesarios para calcular cij.
Algoritmo de Cannon 3. Cada procesador multiplica su par de elementos. 4. Cada fila de A se desplaza una posición a la izquierda, y cada columna de B una posición hacia arriba. 5. Cada procesador multiplica su nuevo par de elementos, y suma el resultado al anterior. 6. Se repiten los pasos 4 y 5 hasta terminar, es decir n – 1 desplazanientos
Algoritmo de Cannon • Análisis de comunicaciones Los desplazamientos iniciales requieren un máximo de n-1 desplazamientos, y después se realizarán n-1 desplazamientos (uno en cada paso) por lo que tenemos el siguiente tiempo de comunicaciones: Esto nos da O (n)
Algoritmo de Cannon En el caso de que estemos trabajando con submatrices, tenemos s-1 desplazamientos iniciales como máximo, y s-1 desplazamientos después, cada uno de ellos de m2 elementos: Lo que nos da O (sm2) = O (nm)
Algoritmo de Cannon • Análisis de computación Cada procesador realiza n multiplicaciones y n-1 sumas para calcular su elemento de C, lo que implica O (n). Usando submatrices, cada procesador realiza m3 multiplicaciones y m3 sumas por cada multiplicación, y m2 sumas por cada suma, y realiza s multiplicaciones y s-1 sumas: Lo que da O (sm3) = O (nm2)
Multiplicación de matrices • Nociones básicas sobre matrices • Algoritmo secuencial • Algoritmo paralelo • Submatrices • Implementación directa • Implementación con submatrices • Implementación recursiva • Algoritmo de Cannon • Array sistólico • Algoritmo de Fox • Algoritmo DNS • Mapeo de matrices en procesadores
Array sistólico • La información es bombeada al array sistólico en varias direcciones a intervalos regulares. • Concretamente, la información es bombeada desde la izquierda hacia la derecha y desde arriba hacia abajo. • Los datos se encuentran en los nodos, y entonces se multiplican y suman al valor calculado anteriormente.
Array sistólico Ej:
Array sistólico • Análisis de comunicaciones Se realizan n desplazamientos para que la última fila y ultima columna entren, n–1 para que entre el último elemento y n-1 para que llegue al final, por lo que tenemos el siguiente tiempo de comunicaciones: Esto nos da O (n)
Array sistólico • Análisis de computación Cada procesador realiza n multiplicaciones y n-1 sumas, lo que nos da un orden de complejidad O (n)
Array sistólico • Multiplicación de una matriz por un vector: Esta técnica puede utilizarse directamente para multiplicar una matriz por un vector usando simplemente un array de 1xn o de nx1, según sea el vector.
Multiplicación de matrices • Nociones básicas sobre matrices • Algoritmo secuencial • Algoritmo paralelo • Submatrices • Implementación directa • Implementación con submatrices • Implementación recursiva • Algoritmo de Cannon • Array sistólico • Algoritmo de Fox • Algoritmo DNS • Mapeo de matrices en procesadores
Algoritmo de Fox • Matrices de tamaño n x n • Se particionan a través de p procesadores. • Hace uso de un broadcast de uno a muchos de los bloques de la matriz A en filas de procesadores, y de un paso de bloques de la matriz B a través de las columnas de los procesadores en forma ascendente de procesador en procesador. • Inicialmente se selecciona cada bloque Ai,j de la diagonal para un broadcast.
Algoritmo de Fox Repetir veces • Broadcast del bloque seleccionado de A a través de los procesadores de la fila en que está ubicado el bloque. • Multiplicar el bloque recibido de A como resultado del broadcast por el bloque residente de B (el procesador que inicia el broadcast ya tiene el bloque requerido de A). • Enviar el bloque de B al procesador directamente precedente en la columna del procesador (con enrollamiento), y recibir un bloque de refresco de B desde el procesador posterior. • Seleccionar el bloque de A para el broadcast de la siguiente fila. Si se ha realizado un broadcast de Ai,j en la etapa actual, entonces seleccionar para el próximo broadcast A [i,(j+1)mod ].

![[MATRICES ]](https://cdn4.slideserve.com/144276/matrices-dt.jpg)