Download

1 / 48
480 likes | 558 Views
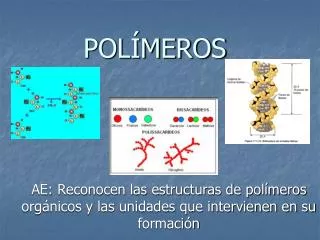
Métodos estatísticos II. Almir R. Pepato (Aula preparada com a ajuda daquelas disponibilizadas por Fred(rik) Ronquist). Resolução do exemplo numérico. 0 1 0 0. 0 0 1 0. 0 1 0 0. 0 1 0 0. Resolução do exemplo numérico. 0 1 0 0. 0 0 1 0. 0 1 0 0. 0 1 0 0.

E N D
Métodos estatísticos II Almir R. Pepato (Aula preparada com a ajuda daquelas disponibilizadas por Fred(rik) Ronquist)
Resolução do exemplo numérico 0 1 0 0 0 0 1 0 0 1 0 0 0 1 0 0
Resolução do exemplo numérico 0 1 0 0 0 0 1 0 0 1 0 0 0 1 0 0 0.00097 0.02828 0.02828 0.00097
Resolução do exemplo numérico 0 1 0 0 0 0 1 0 0 1 0 0 0 1 0 0 0.00097 0.02828 0.02828 0.00097 0.0000026
Resolução do exemplo numérico 0 1 0 0 0 0 1 0 0 1 0 0 0 1 0 0 0.00097 0.02828 0.02828 0.00097 0.0000026 0.0218338
Resolução do exemplo numérico 0 1 0 0 0 0 1 0 0 1 0 0 0 1 0 0 0.00097 0.02828 0.02828 0.00097 0.0000026 0.0218338 0.0000259
Resolução do exemplo numérico 0 1 0 0 0 0 1 0 0 1 0 0 0 1 0 0 0.00097 0.02828 0.02828 0.00097 0.0000026 0.0218338 0.0000259 0.0000026
Resolução do exemplo numérico 0 1 0 0 0 0 1 0 0 1 0 0 0 1 0 0 0.00097 0.02828 0.02828 0.00097 0.0000026 0.0218338 0.0000259 0.0000026
InferênciaBayesiana Exemplo Simples, comparando dois modelos. Há dois sapos de origami, Joe e Herman. Por experiências anteriores sabe-se que Joe cai 60% das vezes em pé, enquanto Herman cai apenas 20% das vezes. O nome dos sapos foi apagado. Como podemos inferir qual é Joe apenas fazendo-os saltar? Primeiro lançamento, caiu em pé:
Inferência Bayesiana Segundo lançamento, caiu em pé: Terceiro lançamento, caiu de costas:
Inferência Bayesiana aplicada à filogenias Grupo externo:
Inferência Bayesiana aplicada à filogenias Probabilidade a priori Probabilidade Dados Probabilidade a posteriori Probabilidade
Inferência Bayesiana aplicada à filogenias Probabilidade posterior tree 3 tree 1 tree 2 Espaço paramétrico
Inferência Bayesiana aplicada à filogenias D = Dados = Parâmetros do modelo ”Verossimilhança” Probabilidade Posterior Prior Constante Normalizadora
Monte Carlo-Cadeia de Markov 1-Inicia-se em um ponto arbitrário (θ) 2-Faz-se uma pequena modificação propondo um novo estado (θ*) 3-Calcula-se a razão r entre novo estado θ*, e θ: r>1: novo estado é aceito. R<1: novo estado é aceito com uma probabilidade r.
Monte Carlo-Cadeia de Markov 1-Inicia-se em um ponto arbitrário (θ) 2-Faz-se uma pequena modificação propondo um novo estado (θ*) 3-Calcula-se a razão r entre novo estado θ*, e θ: r>1: novo estado é aceito. R<1: novo estado é aceito com uma probabilidade r. Sempre aceito 2a O tempo que a MCMC passa amostrando uma região do espaço paramétrico é uma estimativa da densidade da probabilidade posterior naquela região. 1 Aceito às vezes 2b 48 % 32 % 20 % tree 3 tree 1 tree 2
Regulando a cadeia de Markov • Tipicamente um ou poucos parâmetros são modificados por vez. • Uma geração é um ciclo completo ou uma nova proposta tomada ao acaso. Novos valores são retirados uniformemente de uma janela de tamanho δ e centrada em x. Para lances mais “ousados”: aumente δ, mas isso também diminuirá as chances de novos estados serem aceitos...
Regulando a cadeia de Markov ”burn-in” “Mixing”: capacidade da cadeia de explorar adequadamente as regiões de maior probabilidade posterior do espaço paramétrico Não adianta amostrar todas as gerações. As mais próximas estão muito correlacionadas.
Regulando a cadeia de Markov Distribuição esperada Lances muito acanhados: taxa de aceitação dos novos estados altos. “Mixing” deficiente. Lances muito ousados: taxa de aceitação muito baixa. “Mixing” deficiente. Valores amostrados Lances “na medida” Bom “mixing”
Convergência Convergência é o grau em que a cadeia convergiu para a distribuição de máxima probabilidade posterior. Trocando em miúdos: MCMC é uma técnica heurística, precisamos algo que nos dê segurança a respeito da busca. Indicadores de convergência: 1- A cadeia atingiu um platô. 2- O comportamento da busca parece adequado: Através do ESS (EffectiveSampleSize ): O número de amostras realmente independentes da distribuição posterior à que a cadeia de Markov é equivalente.
Convergência Telas do programa TRACER
Convergência entre corridas • Topologias: • Compara as probabilidades dos clados (”split frequencies”), a diferença entre o desvio padrão das duas ou mais corridas deve tender a zero. • Variáveis contínuas • ”Potential scale reduction factor” (PSRF). Compara variância dentro e entre as corridas. Deve tender a zero na medida em que as corridas convergem.
Convergência Telas do programa AWTY (Are WeThereYet) Esta análise funciona como que parando a corrida em pontos a intervalos regulares e verificando as probabilidades posteriores até aquele ponto. Comparação das probabilidades posteriores dos clados de duas corridas.
MC3: Metropolis Coupling Markov Chain Monte Carlo T é a temperatura, é o coeficiente de aquecimento A idéia consiste em introduzir uma série de cadeias rodando em paralelo e acopladas, ou seja, trocando valores entre si. Algumas dessas cadeias’ são aquecidas, isto é: a sua probabilidade posterior é elevado a um número menor que 1. Assim o espaço de probabilidades aparece como que aplainado. Determinar a melhor temperatura é crucial. Exemplo para = 0.2: Cadeia fria Cadeia aquecida
MC3: Metropolis Coupling Markov Chain Monte Carlo Cadeia fria Cadeia aquecida
Cadeia fria Cadeia aquecida
Cadeia fria Cadeia aquecida
Cadeia fria Cadeia aquecida
Cadeia fria Troca mal sucedida Cadeia aquecida
Cadeia fria Cadeia aquecida
Cadeia fria Cadeia aquecida
Cadeia fria Troca bem sucedida Cadeia aquecida
Sumarizando as árvores • Árvore de Maior Probabilidade Posterior • Pode ser difícil de encontrar • Pode ter baixa probabilidade para alguns clados (não reflete suporte) • Árvore de consenso de Maioria • Reflete melhor a probabilidade posterior dos clados • Distribuição de comprimento de ramos pode ser multimodal • Intervalo de credibilidade de árvores • Incluí as árvores em ordem decrescente de probabilidade até obter um intervalo de credibilidade de, e.g., 95 %
Consenso de maioria Frequências representam a probabilidade posterior dos clados
Sumarizando os parâmetros • Média, mediana, variância são os mais comuns • intervalo de credibilidade de 95 %: descarte os 2.5 % superiores e inferiores • Intervalo de 95 % de maior densidade posterior: encontre a menor região contendo 95 % da probabilidade posterior
Média e o intervalo de credibilidade de 95% para os parâmetros do modelo.
Priors Antes de falar dos priors é necessário revisar as principais distribuições contínuas e discretas. • Distribuições contínuas • Normal • Beta • Gama • Dirichlet • Exponencial • Uniforme • Lognormal • Distribuições discretas • Uniforme • Binomial • Multinomial • Poisson
Espaço amostral Função da distribuição Distribuição uniforme discreta Distribuições uniformes são utilizadas quando quer se expressar ausência completa de conhecimento a respeito de um parâmetro que tem impacto uniforme sobre a verossimilhança. A uniforme discreta é utilizada para as topologias, por exemplo.
Distribuição contínua Disco com circumferência 1 Espaço Amostral (um intervalo) Função da densidade de probabilidades (e.g. Uniforme (0,1)) a b Evento (um subespaço do espaço amostral) Probabilidade
X ~ Distribuição exponencial Lembram dessas equações? Parametros: = taxa de decaimento Média: Nelas percebemos que a probabilidade, base do calculo da verossimilhança é uma função exponencial negativa do comprimento do ramo. Nada mais natural portanto que usar uma distribuição exponencial para seu prior.
Distribuição Gama X ~ Como vimos na aula sobre modelos, a distribuição gama é utilizada para descrever a variação na taxa de evolução entre sítios. Na verdade, aqui temos um Hiperprior , isto é, α dita a distribuição a priori das taxas de variação e é retirado de uma distribuição (uniforme por exemplo) . = formato = escalar Parâmetros: Média: Gama escalonado: Gama escalonado
X ~ Distribuição Beta Parâmetros: = formato É utilizada para parâmetros que descrevem proporções de um todo, com apenas dois eventos possíveis. Por exemplo: proporção de invariáveis e razão de Transversões/Transições. Modo:
Distribuição Dirichet X ~ Parâmetros: = vetor de k shapes Semelhante à Beta, mas para várias classes de eventos: descreve a frequência de nucleotídeos e as taxas no GTR por exemplo. Definida como k proporções de um todo Dir(1,1,1,1) Dir(300,300,300,300)
Porque usar análises Bayesianas Nós podemos focar em qualquer parâmetro de interesse (não existem parâmetros “sem uso”) marginalizando a probabilidade posterior por sobre outros parâmetros (integrando a incerteza dos outros parâmetros) 48% 32% 20% tree 3 tree 1 tree 2 (Porcentagens mostram a probabilidade marginal das árvores)
Porque usar análises Bayesianas árvores Probabilidades conjuntas Comprimentos dos ramos Probabilidades marginais
Porque usar análises Bayesianas • Capaz de implementar modelos altamente parametrizados. • A estimativa da incerteza da árvore e a hipótese filogenética são obtidas ao mesmo tempo. • As probabilidades posteriores são de interpretação intuitiva • Pode incorporar conhecimento prévio a respeito do problema (através do Prior)
Possível problema Os Priors!