Download

1 / 20
200 likes | 340 Views
Digitizing California Arthropod Collections. Peter Oboyski, Phuc Nguyen, Serge Belongie , Rosemary Gillespie Essig Museum of Entomology University of California Berkeley, California, USA. Who is CalBug ?. Essig Museum of Entomology California Academy of Sciences

E N D
Digitizing California Arthropod Collections Peter Oboyski, Phuc Nguyen, Serge Belongie, Rosemary Gillespie Essig Museum of Entomology University of California Berkeley, California, USA
Who is CalBug? Essig Museum of Entomology California Academy of Sciences California State Collection of Arthropods Bohart Museum, UC Davis Entomology Research Museum, UC Riverside San Diego Natural History Museum LA County Museum Santa Barbara Museum of Natural History
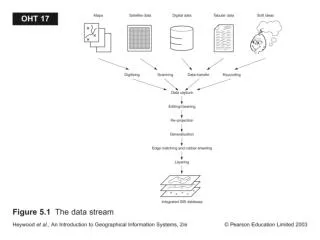
Digitization workflow Optical Character Recognition (OCR) & Automated data parsing (Optional) Sort by locality, date, sex, etc. Online crowd-sourcing of manual data entry Manually enter data into MySQL database Remove labels, add unique identifier Replace labels, return to collection Take digital image, name and save file Geographic referencing Aggregate data in online cache Temporospatial analyses Error checking Handling & Imaging Data Capture Data Manipulation
Why Image Specimens/Labels? • Data capture can be done remotely • Magnify difficult to read labels • Potential for OCR • Verbatim digital archive of label data
Higher resolution Labels flat & unobstructed Scale bar, controlled light Important to add species name to image or file name EMEC218958 Paracotalpaursina.jpg ~150,000 images waiting to database
Data capture Optical Character Recognition (OCR) & Automated data parsing Using our own MySQL database (EssigDB) Built-in error checking Data carry-over one record to next Taxonomy automatically added “Notes from Nature” Collaboration with Zooniverse Citizen Scientist transcription of labels Collaboration with UC San Diego Improved word spotting& OCR Online crowd-sourcing of manual data entry Manually enter data into MySQL database
Notes from Nature Citizen Science data transcription
Integrating OCR with crowd sourcing Spotting words within images Copy-paste, highlight-drag fields Auto-detecting repeated “words” eg. species, states, counties Providing an additional “vote” for transcription consensus
The OCR challenge for specimen labels DETECTION: Finding text in a complex matrix Machine-typed vs. hand-written labels Sliding window classifier creating text bounding boxes >95% detection and localization using pixel-overlap measures
Current Progress in OCR recognition RECOGNITION: Using TesseractOCR engine Machine Type 74% accuracy for word-level 82% accuracy for character-level Hand Writing 5.4% accuracy for word-level 9.2% accuracy for character-level
Where do we go from here? Improved recognition of hand-writing Incorporate OCR into crowd sourcing Develop (semi-) automated data parsing
Thank you http://calbug.berkeley.edu