Download

1 / 63
630 likes | 894 Views
Universidade Federal de Pernambuco Centro de Informática. GenBank. Introdução à Biologia Molecular Computacional (IF803). Roteiro. GenBank Introdução Entrada Submissão Atualização Acesso In the news NCBI (Site Map) DataBases Tools Education Metabolic Pathways

E N D
Universidade Federal de Pernambuco Centro de Informática GenBank Introdução à Biologia Molecular Computacional (IF803)
Roteiro • GenBank • Introdução • Entrada • Submissão • Atualização • Acesso • In the news • NCBI (Site Map) • DataBases • Tools • Education • Metabolic Pathways • Referências Bibliográficas
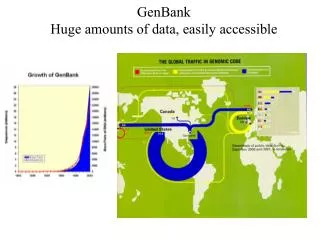
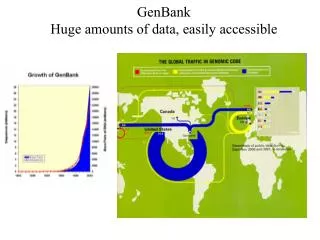
GenBank (Introdução) GenBank é uma base de dados de sequências genéticas do NationalInstituteofHealth (NIH). Cotem uma coleção de todas as sequências de DNA publicamente disponíveis. Em junho de 2009 possuia quase 86 bilhões de bases em quase 83 milhões de registros de sequências, o que corrobora o seu crescimento exponencial ao longo dos anos. • Faz parte da International Nucleotide Sequence DataBase Collaboration; • Troca dados com o DNA DataBank of Japan (DDBJ) e com o European Molecular Biology Laboratory (EMBL); • O GenBank é mantido através de submissões diretas de laboratórios independentes e centros de sequenciamento em larga-escala.
GenBank (Entrada) • Cada entrada contem: • Descrição da sequência em questão; • Nome científico e taxonomia do organismo fonte; • Tabela de características que identifica regiões codificantes e outros sítios de significância biológica (unidades de transcrição, sítios de mutação, etc) e também contem a tradução de proteínas para regiões codificantes ; • Referências bibliográficas
GenBank (Submissão) É possível submeter dados ao GenBank, visto que muitas revistas científicas requerem esse tipo de procedimento para que possam publicar algum número de acesso em determinado artigo. • Existem diferentes opções de submissão: • BankIt: Ferramenta de submissão pela internet; • Sequin: Software desenvolvido pelo NCBI. Os arquivos de saída devem ser enviados ao GenBank por email.
GenBank (Submissão) • tbl2asn: Programa em linha de comando que automatiza a criação de registros de sequências para submissão ao GenBank. (Genomas completos, sequências em lote); • Barcode Submission Tool: Ferramenta de submissão pela internet e rastreamento de dados para o Barcode of Life Projects.
GenBank (Atualização) Atualizações podem ser feitas a qualquer momento pelas pessoas que submeteram algum dado. Sendo necessário o número de acesso da sequência que se deseja atualizar. • Através da opção de atualização na página do BankIt; • Por email; • Como um arquivo do Sequin.
GenBank (Acesso) • Há diversas maneiras de buscar e recuperar dados do GenBank: • Busca por identificadores de sequências e comentários pode ser feita através do Entrez Nucleotide, que é dividido em três segmentos: CoreNucleotide (conjunto principal), dbEST (rótulos de sequências expressas) e dbGSS (sequências de pesquisas de genoma); • Busca e alinhamento utilizando BLAST; • Buscar, relacionar e fazer download de sequencias usando NCBI e-utilities.
GenBank (In thenews) • Na página principal do GenBank são disponibilizadas, também informações sobre sequências que estão sendo estudadas na atualidade, geralmente aquelas provenientes de organismos recém descobertos (vírus ou bactérias com mutações gênicas).
NCBI (Databases) Literature Databases PubMed PubMed é um serviço da U.S.NationalLibraryof Medicine(NLM) que inclui mais de 18 milhões de citações da MEDLINE* e outras revistas científicas relacionadas a artigos biomédicos, além disso, o PubMed inclui links para diversos artigos da área e outros recursos relacionados. * MEDLINE é a principal base de dados de bibliografias da NLM que contem referências para artigos relacionados à ciências biológicas com concentração em biomedicina.
NCBI (Databases) Literature Databases OMIM (Online MendelianInheritance in Man) OMIM é um catálogo de genes humanos e contem informação a respeito de todas as desordens Mendelianas conhecidas. Ele foca na relação entre genótipo e fenótipo. É atualizado diariamente e também contem links para outros recursos genéticos. • 1ª Versão (MIM): versão não online criada em 1960 por Dr. Victor A. McKusick como um catálogo de traços e desordens mendelianas; • 2ª Versão (OMIM): versão online desenvolvida em 1985 através de uma colaboração entre duas bibliotecas (NLM e William H. Welch Medical Library at Johns Hopkins); • 3ª Versão (OMIM): versão online desenvolvida em 1995 pelo National Center for Biotechnology Information (NCBI).
NCBI (Databases) Literature Databases Books (Bookshelf) Books é uma coleção de livros e outros materiais relacionados a biomedicina que podem ser localizados através de uma ferramenta online de busca no website do NCBI. Também inclui livros e bases de dados produzidos pela NLM e pelo NCBI.
NCBI (Databases) Literature Databases
NCBI (Databases) Molecular Databases NucleotideSequences RefSeq (ReferenceSequence) RefSeq é uma rica coleção de DNA, RNA e sequências de proteínas de diversas taxas. Contem sequências de plasmídeos, organelas, vírus, archaea, bactérias e eucariotos. Cada RefSeq representa uma simples molécula de um organismo. O principal objetivo desse projeto é prover uma base de dados que represente informação sobre sequências gênicas para as espécies.
NCBI (Databases) Molecular Databases NucleotideSequences • Principais características da RefSeq: • Não possui redundância; • Possui ligações explícitas entre nucleotídeos e sequências de proteínas; • Atualizações que refletem o atual conhecimento da sequência e a biologia; • Validação e consistência dos dados; • Séries distintas de acesso; • Revisão continua realizada pela equipe do NCBI.
NCBI (Databases) Molecular Databases NucleotideSequences RefSeqs RefSeqs (RefSeqBiologicalSequences) é derivado do GenBank e cada RefSeq contem síntese das informações ao contrário da RefSeq “pura”. Outra distinção entre RefSeq e RefSeqs, é que as RefSeqs podem ser acessadas sem restrições através do NCBI FTP, Entrez ou via BLAST , enquanto a RefSeq “pura” representa a consolidação de informação por um grupo particular.
NCBI (Databases) Molecular Databases NucleotideSequences dbEST (Expressed Sequence Tags Database) dbEST é uma divisão do GenBank que contem dados e outras informações sobre sequências de DNA complementar (cDNA) ou ”ExpressedSequenceTags” de alguns organismos. ExpressedSequenceTag é uma sub-sequência pequena do cDNA transcrito. Pode ser usado na identificação de transcrições gênicas é de singular importância para a descoberta de genes e determinação de sequências gênicas. • Obs.: • O dbEST é pequeno, visto que contem sequências de DNA produzidas a partir de RNA mensageiro, por isso geralmente as sequências são produzidas em lotes.
NCBI (Databases) Molecular Databases NucleotideSequences EST é produzido através de uma sequência de RNA mensageiro (clonado). A sequência resultante desse processo possui qualidade limitada pela tecnologia atual que consegue gerar cadeias com tamanho entre 500 e 800 nucleotídeos, segundo dados do Wikipedia em maio de 2009. Após a anotação, ESTs podem ser mapeados em cromossomos utilizando mapas físicos.
NCBI (Databases) Molecular Databases NucleotideSequences • ESTs podem ser acessados de diversas maneiras: • Através do NCBI FTP (em formato FASTA); • Através do sistema Entrez; • Através do BLAST;
NCBI (Databases) Molecular Databases NucleotideSequences dbSNP (Single Nucleotide Polymorphism Database dbSNP é uma base de dados pública que contem uma vasta coleção de polimorfismos genéticos simples. Esta coleção inclui substituições de nucleotídeos single-base (SNPs) e deleções e inserções multi-base em pequena escala (DIPs). Assim como todos os bancos do sistema Entrez, o dbSNP aceita submissões . Essas estão relacionadas a variações em qualquer espécie e de qualquer parte de um determinado genoma. E também permite acesso por qualquer um dos métodos já citados.
NCBI (Databases) Molecular Databases NucleotideSequences • Cada entrada da base de dados contem: • A sequência contexto do polimorfismo (os arredores da sequência); • A frequência de ocorrência do polimorfismo (populacional ou individual); • O método experimental utilizado; • Protocolos e condições usadas para analisar a variação;
NCBI (Databases) Molecular Databases ProteinSequences RefSeqs Possui as mesmas características do RefSeq para sequências de nucleotídeos, porém com foco em sequências protéicas.
NCBI (Databases) Molecular Databases ProteinSequences CDD (ConservedDomain Database) É uma base de dados de domínios conservados de proteínas. CDD tenta agrupar domínios relacionados a um descendente comum em hierarquias familiares. O processo de busca utiliza o algoritmo BLAST. A cadeia de entrada é comparada a uma matriz de scores de posições específicas construída com informações de alinhamentos de domínios conservados. Depois é executado por padrão busca paralela usando o BLAST para busca em proteínas. • Obs.: • O resultado da busca pode depois ser utilizado pela ferramenta CDART descrita mais adiante.
NCBI (Databases) Molecular Databases ProteinSequences Protein Clusters Protein Clusters DB é uma coleção de sequências referências de proteínas co-relacionadas (clusters) codificadas por genomas completos. A base de dados contem clusters revisados e não revisados e provê acesso fácil a informações relevantes, publicações, domínios, estruturas, links externos e ferramentas de análise que inclui alinhamentos múltiplos, árvores filogenéticas e vizinhança genômica. Protein Clusters pode ser acessada da mesma maneira que todas as bases de dados do sistema Entrez.
NCBI (Databases) Molecular Databases Structures 3D Domains São domínios de estruturas compactas que podem ser identificadas automaticamente no MMDB (base de dados de estruturas tridimensionais). 3D Domains são utilizados como unidades de comparação para cálculos de estruturas vizinhas utilizando o algoritmo VAST. É importante conhecer esses domínios, visto que muitas das funções da proteína estão intimamente ligadas a sua estrutura. O NCBI possui um visualizador de estruturas 3D conhecido como Cn3D.
NCBI (Databases) Molecular Databases Genes UniGene (An Organized View of the Transcriptome) É uma base de dados que contem coleções de sequências transcritas que tem alta probabilidade de terem surgido de um mesmo locus de transcrição (gene ou pseudogene expresso), além de conter informações sobre similaridades entre proteínas, expressões gênicas, reagentes para clonagem de cDNA e localização gênica. UniGene tem sido usado para seleção de reagentes para projetos de mapeamento genético e análise de expressões em larga escala.
NCBI (Databases) Molecular Databases Gene Expression GEO (Gene Expression Omnibus) O projeto GEO foi iniciado em 1999 devido ao aumento da demanda por repositórios públicos de dados gerados através de experimentos com microarrays. GEO tem um design flexível e aberto que permite submissões, armazenamento e recuperação de muitos tipos de coleções de dados, como por exemplo dados obtidos através de altas taxas de expressão gênica, de hibridização genômica e experimentos com anticorpos. GEO atua como um ponto central de distribuição de dados moleculares.
NCBI (Databases) Molecular Databases Gene Expression • Registros da base de dados primária: • Platform: Define a lista de elementos que podem ser detectados e quantificados em determinado experimento (cDNA, conjuntos de oligonucleotídeos investigados,etc). Pode referenciar samples submetidos por diversos usuários. • A cada registro de plataforma é atribuído um único número de acesso (GPLxxx). • Samples: Descreve a condição sobre a qual uma amostra individual foi manuseada, as manipulações realizadas e as medidas de cada elemento derivado da amostra. • A cada registro de sample é atribuído um único número de acesso (GSMxxx).
NCBI (Databases) Molecular Databases Gene Expression • Series: Registros de séries ligam grupos de samples relacionados e provê um ponto de foco e descrição do estudo como um todo. Também pode conter tabelas que descrevem os dados extraídos, conclusões levantadas ou análises. • A cada registro de série é atribuído um único número de acesso (GSExxx).
NCBI (Databases) Molecular Databases Gene Expression • Registros primários sofrem um processo de tradução para: • DataSet: Os curadores do GEO remontam o registro de séries em DataSets. Um DataSet representa uma coleção de GEO samples comparáveis biologicamente e estatisticamente. Samples pertencentes a um DataSet se referem a uma única Platform, isto é, eles dividem um conjunto comum de elementos. • Gene Profile: São derivados de DataSets. Um Profile consiste de medidas de expressão para um gene individual sobre todos Samples do DataSet.
NCBI (Databases) Molecular Databases Gene Expression • Acesso aos dados: • Dados GEO podem ser acessados utilizando palavras chave através do Entrez GEO DataSet ou Entrez GEO Profiles ou ainda através do código de acesso através da homepage do GEO. Dados também podem ser baixados através de FTP e também podem ser submetidos e atualizados.
NCBI (Databases) Molecular Databases Gene Expression A – Descrição da coleção B – Tabela modelo da coleção C – Descrição da amostra biológica D – Tabela de resultados do processo de hibridização E – Arquivo original de dados F – Descrição geral do experimento
NCBI (Databases) Molecular Databases Taxonomy Entrez Taxonomy É uma base de dados que contem os nomes de todos os organismos que são representados nos bancos de dados genéticos com pelo menos um nucleotídeo ou sequência de proteína. É possível buscar pela estrutura taxonômica ou ainda recuperar dados de um grupo particular de organismos.
NCBI (Databases) Genomes EntrezGenome Entrez Genome É uma base de dados que provê visualizações de uma variedade de genomas, cromossomos completos, mapas de sequências, genética integrada e mapas físicos. A base de dados é organizada em seis grupos de organismos: Archaea, Bacteria, Eukaryotae, Viruses, Viroids e Plasmids.
NCBI (Databases) Genomes EntrezGenome
NCBI (Databases) Genomes MapViewer Map Viewer Provê uma enorme variedade de mapeamento de genomas e seqüenciamento de dados. Permite a visualização dos dados de forma hierárquica dividida de acordo com a classificação biológica dos organismos. Dessa forma, é possível recuperar genomas inteiros de determinado organismo. Além disso, exibe mapas cromossômicos e permite aproximação progressiva da região de interesse a partir da sequência de dados. Caso, múltiplos mapas estejam disponíveis para um cromossomo, o MapViewer os exibe alinhados baseados nos nomes dos genes ou em marcadores.
NCBI (Databases) Genomes MapViewer
NCBI (Databases) Genomes CancerChromossomes Cancer Chromossomes Três bases de dados: NCI/NCBI SKY/M-FISH & CGH Database, a NCI Mitelman Database ofChromosomeAberrations in Cancer, e a NCI RecurrentAberrations in Cancer, são bases de dados integradas ao sistema Entrez do NCBI como bases de dados de CancerChromossomes. Nessas bases é possível buscar por informação citogenética, clínica e de referências. O acesso é realizado da mesma forma que em outras bases do sistema Entrez (através de FTP, BLAST ou da própria homepage).
NCBI (Databases) Genomes CancerChromossomes
NCBI (Databases) Genomes CancerChromossomes • Exemplos de busca: • Quais cromossomos tem um breakpoint no grupo de cromossomos 9q34? • -> Busca por 9q34 • 2. Quais casos tem um ganho de 8p23? • -> Busca por +8p23 • 3. Quais casos tem uma junção (fusão de breakpoints) entre 9q34 e 22q11? • -> Busca por 9q34J22q11 • 4. Quais casos com 9q34 tem mama associada? • -> Buscapor 9q34 AND breast[site]
NCBI (Tools) Entrez Entrez É uma poderosa ferramenta de busca que permite usuários buscarem por dados em diversas bases de dados relacionadas às ciências biológicas. O sistema é mantido pelo NCBI. Entrez permite acesso a todos os bancos de dados associados simultaneamente com uma simples string de entrada. Entrez pode recuperar sequências, estruturas e referências de maneira eficiente, além de prover visualizações de genes, proteínas e mapas de cromossomos. Livros e outros materiais literários também estão disponíveis online através do sistema Entrez.
NCBI (Tools) BLAST BLAST (Basic Local Alignment Search Tool) É uma ferramenta para comparação de genes e proteínas em bases de dados públicas. BLAST é utilizado pelo sistema Entrez para recuperar os dados buscados.
NCBI (Tools) BLAST • Funcionamento: • Fragmentação da query em mers; • Encontra mers similares até um certo limiar (utiliza matriz de substituição); • Procura por algumas dessas palavras na base de dados (hits); • Estende os hits. No BLAST original não permitia gaps e estendia para ambos os lados. No BLAST atual permite gaps e utiliza uma matriz de pontos;
NCBI (Tools) BLAST • Funcionamento (continuação): • Retém somente os pares com scores acima de um limiar (HighScorePairs); • Determina estatisticamente a relevância de cada resultado (se ocorre homologia ou casualidade).
NCBI (Tools) CDART CDART (Conserved Domain Architecture Retrieval Tool) É uma ferramenta utilizada para a busca de proteínas com domínios conservados, ou seja, com arquiteturas de domínios similares. CDART utiliza resultados de domínios conservados pré-computados obtidos a partir de buscas no CDD (descrito anteriormente) para identificar rapidamente proteínas com um conjunto de domínios similares ao da cadeia de entrada. O algoritmo encontra similaridades entre proteínas através de significantes distâncias evolucionárias usando domínios ao invés da pura similaridade entre sequências.