Download
1 / 29
290 likes | 534 Views
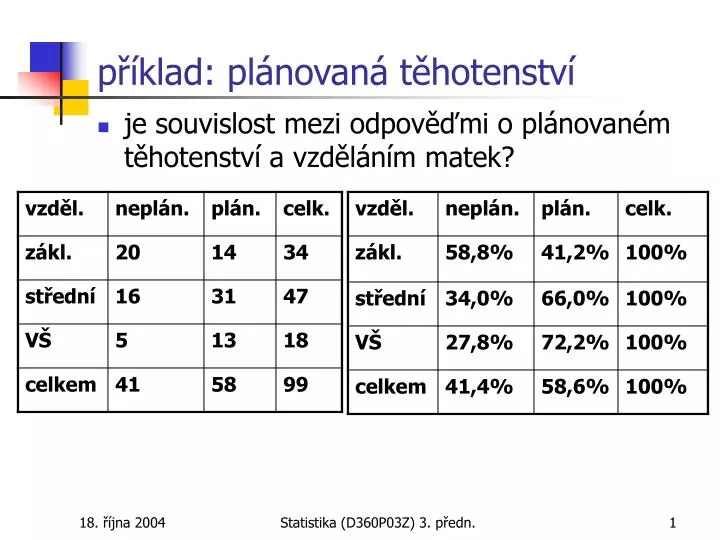
příklad: plánovaná těhotenství. je souvislost mezi odpověďmi o plánovaném těhotenství a vzděláním matek?. příklad: očekávané četnosti. závislost prokázána. příklad – předvolební průzkum. 30 voličů bylo dotázáno, které ze dvou stran dají přednost; souvisí odpovědi s pohlavím?.

E N D
příklad: plánovaná těhotenství • je souvislost mezi odpověďmi o plánovaném těhotenství a vzděláním matek? Statistika (D360P03Z) 3. předn.
příklad: očekávané četnosti závislost prokázána Statistika (D360P03Z) 3. předn.
příklad – předvolební průzkum 30 voličů bylo dotázáno, které ze dvou stran dají přednost; souvisí odpovědi s pohlavím? Statistika (D360P03Z) 3. předn.
čtyřpolní tabulka - závislost • označení četností • ve čtyřpolní tabulce lze sílu závislosti měřit čtyřpolním korelačním koeficientem • je mezi –1 a 1 • příklad: Statistika (D360P03Z) 3. předn.
příklad • r2,2> 0 znamená, že stejným indexem označené možnosti se vyskytují častěji, než bychom očekávali při nezávislosti (muž&A, žena&B) 11· 9 > 6 * 4 Statistika (D360P03Z) 3. předn.
čtyřpolní tabulka • závislost se prokazuje pomocí statistiky chí-kvadrát, kterou lze upravit na tvar • příklad: • závislost jsme tedy na 5% hladině neprokázali Statistika (D360P03Z) 3. předn.
příklad (Simpsonův paradox) r2,2=0,03 r2,2=0,02 r2,2= - 0,02 kdyby stejný poměr muži:ženy na obou místech – bez problému Statistika (D360P03Z) 3. předn.
kvalitativní - kvantitativní • podle kvalitativní proměnné rozdělit hodnoty kvantitativní proměnné do dílčích souborů • porovnat charakteristiky dílčích souborů mezi sebou; pokud se hodně liší – je závislost • celkový průměr = vážený průměr dílčích průměrů • celkový rozptyl = vážený průměr rozptylů + rozptyl průměrů (přesně pro populační rozptyly s n ve jmenovateli) Statistika (D360P03Z) 3. předn.
příklad: věk matek – plán. těhot. (1) 35 30 věk matky 25 20 ne ano zda těhotenství plánováno Statistika (D360P03Z) 3. předn.
závislost • pro nula-jedničkové x sílu závislosti x, y vyjadřuje bodověbiseriální korelační koeficient • kde je průměr těch yi , u nichž je x = 1 • kde je průměr těch yi , u nichž je x = 0 • kde s je směrodatná odchylka všechy (n- 1) ve jmenovateli • kde n0 je počet nul a n1 počet jedniček mezi x Statistika (D360P03Z) 3. předn.
příklad: věk matek – plán. těhot. (2) Statistika (D360P03Z) 3. předn.
příklad: výška otce ~ vzdělání matky Statistika (D360P03Z) 3. předn.
příklad: výška otce ~ vzdělání matky Statistika (D360P03Z) 3. předn.
rozklad rozptylu do skupin • celkový rozptyl = vážený průměr rozptylů + rozptyl průměrů (populační rozptyly) • xij - j-té pozorování z i-té skupiny • - průměr v i-té skupině, celkový prům. variabilita se rozkládá: celková = uvnitř skupin + mezi skupinami Statistika (D360P03Z) 3. předn.
rozklad rozptylu - příklad • budeme-li chtít prokázat rozdíl mezi skupinami, vyjdeme z uvedeného rozkladu • čím je součet čtverců mezi skupinami větší, tím spíš bychom měli prokázat rozdíl mezi skupinami • měřítkem bude součet čtverců uvnitř skupin vydělený (n – k), kde k je počet skupin Statistika (D360P03Z) 3. předn.
příklad: výška otce ~ vzdělání matky (183-177,1)2+…+(180-177,1)2=1188,7 (180-179,5)2+…+(172-179,5)2=1909,8 (187-182,8)2+…+(180-182,3)2=1027,1 variabilita mezi: 4511,2 - 4125,6 = 385,6 Statistika (D360P03Z) 3. předn.
tabulka analýzy rozptylu F = 4,49 > F2,96(0,05)=1,62 průměrný čtverec mezi skupinami (nestejnost průměrů) je v porovnání s průměrným čtvercem uvnitř skupin příliš veliký závislost jsme prokázali Statistika (D360P03Z) 3. předn.
dvojice kvantitativních veličin 10000 + + + + + + + + + + + + + + + + + 130 + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + 8000 + + + + + + + + 110 hmotnost + + + + + + + + + + + + + + + + + + + + + + + + + IQ + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + + 90 + + + + + + + + + + + + + + + + + + 6000 + + + + + 70 65 70 75 1.0 1.5 2.0 2.5 3.0 délka průměr 7. ročník r =0,45 r = -0,69 Statistika (D360P03Z) 3. předn.
závislost spojitých veličin • kovariance • (Pearsonův) korelační koef. (z-skóry) Statistika (D360P03Z) 3. předn.
příklad: hmotnost a délka (24. týden) • délka [cm]: • hmotnost [g]: • kovariance [cm g]: • korelační koeficient: • hmotnost [kg]: • kovariance [cm kg]: • korelační koeficient: Statistika (D360P03Z) 3. předn.
(Pearsonův) korelační koeficient • vypovídá o směru závislosti • při r < 0 s rostoucím x v průměru klesá y • platí -1 r 1 • když body [x ; y ] leží na přímce, pak |r | = 1 • vzájemné nezávislosti odpovídají r blízké 0 • hranice statistické průkaznosti závisí na n, čím větší n , tím menší |r | stačí (tabulky) • takto hodnotit průkaznost lze jen někdy (normální rozdělení) • špatně zachytí křivočarou závislost Statistika (D360P03Z) 3. předn.
Spearmanův korelační koeficient • Spearmanův korel. koef. místo původních hodnot xi, yipoužije jejich pořadí Ri , Qi • vhodné pro nelineární monotónní závislost, nevadí odlehlé hodnoty • při testování nemusí být normální rozdělení Statistika (D360P03Z) 3. předn.
příklad: alkohol – úmrtnost na cirhózu Statistika (D360P03Z) 3. předn.
příklad: alkohol – úmrtnost na cirhózu Statistika (D360P03Z) 3. předn.
příklad: výšky rodičů (1) Výšky rodičů Výšky rodičů 200 185 150 180 175 otec 100 otec 170 50 165 0 155 160 165 170 175 155 160 165 170 175 matka matka Statistika (D360P03Z) 3. předn.
příklad: výšky rodičů (2) Statistika (D360P03Z) 3. předn.
příklad: výšky rodičů • pozor na nevhodnou volbu měřítka! • přímka pro zdůraznění možné závislosti • r = 0,21 • s rostoucí výškou matky v průměru roste výška otce • nezáleží na měřítku (mohli jsme měřit v metrech, matky v jiném měřítku než otce) • nezáleží na posunutí (mohli jsme každému ubrat metr) Statistika (D360P03Z) 3. předn.
příklad: počet letišť a velikost země Evropa Evropa 6 6 5 5 4 4 log(airports) log(airports) 3 3 2 2 1 1 8 9 10 11 12 13 8 9 10 11 12 13 log(area) log(area) Statistika (D360P03Z) 3. předn.
příklad: počet letišť a rozloha státu • někdy je závislost lineární až po vhodné transformaci • výsledek může záviset na jediném pozorování • všech devět zemí => r = 0,93 • bez Lucemburska => r = 0,69 • bez logaritmování • všech devět zemí => r = 0,72 • bez Lucemburska => r = 0,63 • Spearmanův korelační koeficient logaritmování neovlivní: rS = 0,8 (bez Lucemburska rS = 0,71) Statistika (D360P03Z) 3. předn.