Download

1 / 13
130 likes | 259 Views
Entropia H(w) = - P(w)*logP(w) w W H(w 1 w 2 …w k ) = - P(w 1 w 2 …w k )*logP(w 1 w 2 …w k ) w 1 w 2 …w k. Mesaj Probabilitate Codificare Nimeni 0,5 00

E N D
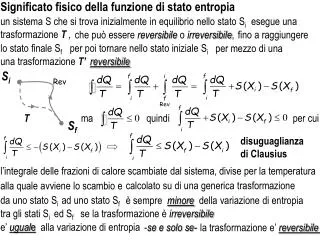
Entropia H(w) = - P(w)*logP(w) wW H(w1 w2…wk) = - P(w1 w2…wk)*logP(w1 w2…wk) w1 w2…wk
Mesaj Probabilitate Codificare Nimeni 0,5 00 Doar soţul 0,125 01 Doar soţia 0,125 10 Amândoi 0,25 11 H(M) = - (1/2 * log21/2 + 1/8 * log2 1/8 + 1/8 * log2 1/8 + 1/4 * log21/4) H(M)= - (1/2 * (-1) + 1/8 *(-3) + 1/8 *(-3) + 1/4 *(-2))=1/2+3/8+3/8+1/2 = 1,75 Entropia nr mediu de biţi nec. pentru codif. neambiguă a unui mesaj Mesaj Probabilitate Codificare Nimeni 0,5 00 Doar soţul 0,5 01 Doar soţia 0,5 10 Amândoi 0,5 11 H(M) = - (1/2 * log21/2 + 1/2* log2 1/2 + 1/2 * log2 1/2 + 1/2 * log21/2) H(M)= - (1/2 * (-1) + 1/2 *(-1) + 1/2 *(-1) + 1/2 *(-1))=1/2+1/2+1/2+1/2 = 2
M H(M)=2 1 0 1 0 0 1 Nimeni Doar soţia Doar soţul Amândoi M H(M)=1,75 1 0 0 Nimeni 1 Amândoi 1 0 Doar soţia Doar soţul
Codificare/codare de lungime variabilă Entropia limbii române 2,055 biţi/literă (Mitrea, 2000) Entropia limbii engleze 1,92 biţi/literă (Shannon, 1951) O literă este reprezentă în calculator (ASCII) printr-un byte (8 biţi). Deci, folosind o codificare entropică, lungimea de stocare a unui text s-ar putea reduce de circa 4ori. Acesta este principiul celor mai multe programe de compresie (de ex. uuencode)
Legile lui George Kingsley Zipf (1902-1950) a) Legea rang/frecvenţă rang*frecvenţă constantă R * F constantă logF - logR F R F R
b) Legea număr/frecvenţă N1/2tokens-of-frecv* frecv constantă N1/2 * F constantă logF - 1/2 * logN F N F N
c) Legea lungime/frevcenţă cele mai frecvente cuvinte au numărul cel mai mic de silabe d) Legea numărului de sensuri: Fie N numărul de cuvinte ce au M sensuri, atunci, N * M2 = constantă e) Frecvenţa cuvintelor reprezintă o constantă specifică limbii etc...
Colocaţii O expresie constând din 2 sau mai multe cuvinte ce corespund unui mod convenţional de a spune ceva. O secvenţă de 2 sau mai multe cuvinte adiacente, ce corespund unei unităţi sintactico-semantice bine definite, al cărei sens exact şi neambiguu nu poate fi derivat direct din sensurile sau conotaţiile componenţilor săi Idiomul reprezintă un caz particular de colocaţie (cel mai non-comp.) Colocaţiile pot fi reprezentate de grupuri frazale cele mai diverse: NP = ceai/cafea tare (nu puternică) vs. drog puternic (nu tare) VP = a bate la uşă, a da cu bâta-n baltă, a-şi aduce aminte, etc. alte grupuri: mare şi tare, proşti dar mulţi, sărac dar cinstit, etc.
Caracteristici ale colocaţiilor • Ne-compoziţionalitate (sau compoziţionalitate limitată) idiomurile sunt (în general) ne-compoziţionale:a da cu bâta-n baltă (a da cu oiştea-n gard), a da ortul popii, etc. compoziţionalitate limitată: practica internaţională(referă de obicei eficienţa administrativă, legislativă, juridică şi nu de pildă prepararea sniţelelor, deşi nimic nu previne această interpretare) Ex: colocaţiile lui alb au sensuri ce nu pot fi neambiguu deduse din alb şi elementul colocaţional vin alb, păr alb/argintiu, bărbat alb
Ne-substitutivitatea da cu bâta-n iaza da 25 de bani popii vin galben, păr gri, bărbat • Alte clase de colocaţii: • verbe difuze semantic (light verbs):a lua, a da, a face, etca lua o decizie (deşi poate mai logic ar fi a face o decizie)a face un duş (deşi poate mai logic ar fi a lua/efectua un duş)a da bună-ziua (a spune bună-ziua) • Nume proprii • Termeni, expresii terminologice hydraulic oil filter = filtru hidraulic de ulei filtru de ulei hidraulic ((filtru hidraulic) de ulei) OK;(filtru (hidraulic de ulei)) not OK ((filtru de ulei) hidraulic) OK; (filtru de (ulei hidraulic)) OK
Termeni ce nu trebuie confundaţi: • colocaţie • co-ocurenţă: apariţie a două sau mai multe cuvinte, formând unităţi sintactice/semantice distincte • coligaţie (J.Sinclair, 1997): o secvenţă formată dintr-un cuvânt şi una sau mai multe categorii sintactico-semantice ce definesc contexte sau sensuri posibile ale cuvântului respectiv. a da <NP_dat> <NP_acc> <Subj_anim> a naşte • concordanţă(-e): o listă de co-ocurenţe ale unui cuvânt de interesProgramele ce extrag concordanţe pot extrage şi coligaţiiStructurile de (sub-)categorizare reprezintăcoligaţii interesanteColocaţiile reprezintă co-ocurenţe interesanteInteresant înseamnă Neîntâmplător
Pentru ca o secvenţă să devină interesantă, ea trebuie să apară mai multdecât întâmplător. Informaţia mutuală o măsură a acestui criteriu: I(w1:w2) = P(w1,w2)/P(w1)*P(w2) Dacă w1 şi w2 apar independent unul de altul (adică apariţia unui cuvânt nu condiţionează apariţia celuilalt), atunci: P(w1,w2) = P(w1)*P(w2) şi deci: I(w1:w2) = 1 Altminteri, P(w1,w2) P(w1)*P(w2) şi deci: I(w1:w2) 1 Cu cât I(w1:w2) cu atât mai mare este probabilitatea de a avea o colocaţie.
Alte măsuri n1* n2* • MI(W1,W2) = • DICE(W1,W2) = • LL(W1,W2) = • 2 (W1,W2) = n*1 n*2 n**