Download
1 / 32
320 likes | 627 Views
Separating hyperplane. Optimal separating hyperplane - support vector classifier. Find the hyperplane that creates the biggest margin between the training points for class 1 and -1. margin. Formulation of the optimization problem. Signed distance to decision border.

E N D
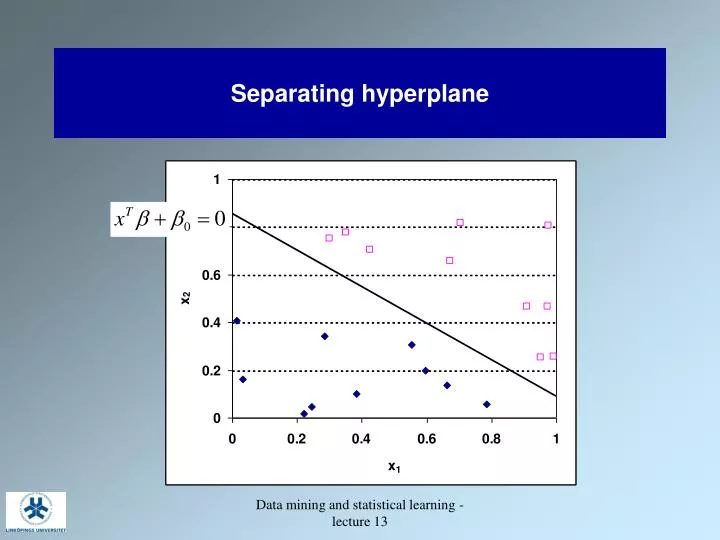
Separating hyperplane Data mining and statistical learning - lecture 13
Optimal separating hyperplane- support vector classifier Find the hyperplane that creates the biggest margin between the training points for class 1 and -1 margin Data mining and statistical learning - lecture 13
Formulation of the optimization problem Signed distance to decision border y=1 for one of the groups and y=-1 for the other one Data mining and statistical learning - lecture 13
Two equivalent formulations of the optimization problem Data mining and statistical learning - lecture 13
Optimal separating hyperplane– overlapping classes Find the hyperplane that creates the biggest margin subject to 1 2 3 Data mining and statistical learning - lecture 13
Characteristics of the support vector classifier Points well inside their class boundary do not play a big role in the shaping of the decision border Cf. linear discriminant analysis (LDA) for which the decision boundary is determined by the covariance matrix of the class distributions and their centroids Data mining and statistical learning - lecture 13
Support vector machinesusing basis expansions (polynomials, splines) Data mining and statistical learning - lecture 13
Characteristics of support vector machines The dimension of the enlarged feature space can be very large Overfitting is prevented by a built-in shrinkage of beta coefficients Irrelevant inputs can create serious problems Data mining and statistical learning - lecture 13
The SVM as a penalization method Misclassification: f(x) < 0 when y=1 or f(x)>0 when y=-1 Loss function: Loss function + penalty: Data mining and statistical learning - lecture 13
The SVM as a penalization method Minimizing the loss function + penalty is equivalent to fitting a support vector machine to data The penalty factor is a function of the constant providing an upper bound of Data mining and statistical learning - lecture 13
Some characteristics of different learning methods Data mining and statistical learning - lecture 13
-insensitive error function - Data mining and statistical learning - lecture 13
SVMs for linear regression Estimate the regression coefficients by minimizing (i) The fitting is less sensitive than OLS to outliers (ii) Errors of size less than are ignored (iii) Typically, the parameter estimates are functions of only a minor subset of the observations Data mining and statistical learning - lecture 13
Ensemble methods • Bootstrapping (Chapter 8) • Bagging (Chapter 8) • Boosting (Chapter 10) • Bagging and boosting in SAS EM Data mining and statistical learning - lecture 13
Major types of ensemble methods • Manipulation of the model • Manipulation of the data set Data mining and statistical learning - lecture 13
Terminology • Bagging=Manipulation of the data set • Boosting = Manipulation of the model Data mining and statistical learning - lecture 13
The bootstrap We would like to determine a functional F(P) of an unknown probability distribution P The bootstrap: Compute F(P*) where P* is an approximation of P Data mining and statistical learning - lecture 13
Resampling techniques- the bootstrap method Resampled data Observed data 60 22 88 41 Sampling with replacement 34 58 67 88 79 88 79 90 62 39 41 41 73 22 34 44 90 58 44 70 60 70 60 85 85 Data mining and statistical learning - lecture 13
The bootstrap for assessing the accuracy of an estimate or prediction Compute Bootstrap samples are generated by sampling with replacement from the observed data • Generate N bootstrap samples and compute • Compute the sample variance of Tk Data mining and statistical learning - lecture 13
Bagging- using the bootstrap to improve a prediction Question: Given the model Y=f(X)+ε and a set of observed values Z={Yi, Xi, i=1,…,N}, what is where P denotes the distribution of (X,Y)? Solution: Replace P with P*: • Produce B bootstrap samples and, for each sample, compute • Compute the sample mean by averaging over the bootstrap functions. Data mining and statistical learning - lecture 13
Bagging Formula: Construct graphs, compute average Data mining and statistical learning - lecture 13
Properties of bagging • Bagging of fitted functions reduces the variance • Bagging makes good predictions better, bad predictions worse • If the fitted function is linear, it will asymptotically coincide with the bagged estimate (B -> Infinity) Data mining and statistical learning - lecture 13
Bagging for classification Given a K-class classification problem with Z={Yi, Xi, i=1, …, N} and a computed indicator function (or class probabilities) we produce a bagging estimate and predict class variables Data mining and statistical learning - lecture 13
Boosting- basic idea Consider a 2-class problem with and a classifier . Produce a sequence of classifiers and combine them. The weights for misclassified observations are increased to force the algorithm to classify them correctly at next step. Data mining and statistical learning - lecture 13
Boosting Data mining and statistical learning - lecture 13
Boosting Data mining and statistical learning - lecture 13
Boosting- comments • Boosting can be modified for regression • AdaBoost.M1 can be modified to handle categorical output Data mining and statistical learning - lecture 13
Bagging and boosting in EM • Create a diagram (Input node (define target!) – Partition node – Group processing node – Your model – Ensemble node) • Comment: boosting works only for classification (categorical output) Data mining and statistical learning - lecture 13
Group processing: General Modes: • Unweighted resampling for bagging • Weighted resampling for boosting Data mining and statistical learning - lecture 13
Group processing- Unweighted resampling for bagging • Specify sample size Data mining and statistical learning - lecture 13
Group processing: weighted resampling for boosting • Specify target Data mining and statistical learning - lecture 13
Ensemble results Data mining and statistical learning - lecture 13






















