Download

1 / 31
310 likes | 479 Views
Processor-Swapping in Enterprise Computing. Otto Sievert Henri Casanova Fran Berman. Outline. Motivation and Scope Re-scheduling Processor-Swapping Simulations and Experiments Conclusion & Future Work. Motivation. “Enterprise computing” Reuse existing (desktop resources)

E N D
Processor-Swapping in Enterprise Computing Otto Sievert Henri Casanova Fran Berman
Outline • Motivation and Scope • Re-scheduling • Processor-Swapping • Simulations and Experiments • Conclusion & Future Work
Motivation • “Enterprise computing” • Reuse existing (desktop resources) • Cost-effective • Non-dedicated resources • Individually owned resources • GrADS “MacroGrid” testbed • Running a Parallel Application • A fraction of the resources are likely not loaded • Load evolves dynamically • How does one run long-running non-embarrasingly parallel applications?
Related Work • Enterprise Computing is not a new idea: • Use resources when they are available • Migrate when resources become unavailable • Many projects • Condor • Enterprise computing (Entropia, Avaki) • … • We focus on one specific re-scheduling issue for iterative // applications (more later…) • We have implemented a simple MPI-based run-time system, but the ideas can be re-used in other contexts…
Questions • How can we: • Enable parallel applications in the Enterprise computing scenario? • Require only minimal implementation effort from the application developer? • Reduce turn-around time?
Assumptions • One Iterative, long-running, parallel application • We know how to schedule the application (in static conditions) • There are more processors in the system than needed to run the application effectively • We currently ignore network heterogenity in our models
Scheduling Favorite Scheduler What do I do when the load of a machine I am using goes up?
Re-scheduling strategies • Do nothing • In the long-run performance degrades • Checkpoint/Restart of the whole app. • Rather simple to implement • Possible large overhead • Checkpoint, restart everything… • Schedule again • Vacate resources that were used? • Cool down of monitoring tools effect
Possible Strategies (2) • Dynamic load-balancing • Many theoretical results • Many practical implementations • Has been shown to give good results to deal with fluctuating workload • Implementation • Re-engineering of existing, complex, scientific applications is often difficult • Few programming environments • May be “stuck” with “bad” resources • Re-balance or migrate the whole app? • Run the application everywhere? • But still hard to engineer
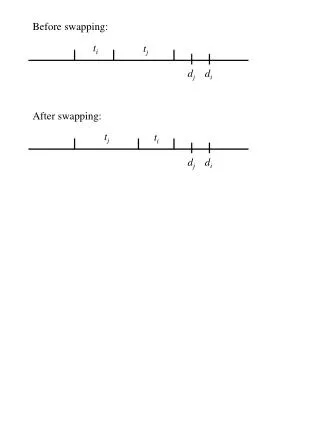
Processor Swapping • Simple idea • Swap processors in and out of the application without data re-partitioning • Limits re-scheduling options • Stuck with the original data partition • Intuitively seems sufficient in many scenarios (many hosts?) • Should be straigthforward to implement
Processor Swapping (2) Dynamic Load-Balancing Performance Pay-off Checkpoint Restart Processor Swapping HYPOTHESIS Unmodified Application Difficulty of Implementation
Our objectives • Implement Processor Swapping with minimal intrusion for the user • Make it easy to convert existing applications • Make Processor Swapping portable • We provide a library and a runtime environment
The GrADS Framework • Scheduling vs. Re-scheduling • The Cactus Worm [IJHPCA 2001]
Our Implementation (API) • Based on MPI • As little as 3 line code change original code #include <mpi.h> main() { int iteration; /* iteration variable */ MPI_Init(); MPI_Type_contiguous(); MPI_Type_commit(); MPI_Comm_size(); MPI_Comm_rank(); MPI_Bcast(); MPI_Barrier(); for (a lot of loops) { (MPI_Send() || MPI_Recv()); MPI_Bcast(); MPI_Allreduce(); } MPI_Barrier(); MPI_Finalize(); } Swap code #include <mpi_swap.h> main() { int iteration; /* iteration variable */ swap_register(iteration); MPI_Init(); MPI_Type_contiguous(); MPI_Type_commit(); MPI_Comm_size(); MPI_Comm_rank(); MPI_Bcast(); MPI_Barrier(); for (a lot of loops) { MPI_Swap(); (MPI_Send() || MPI_Recv()); MPI_Bcast(); MPI_Allreduce(); } MPI_Barrier(); MPI_Finalize(); }
Our implementation (Internals) • Principle • Overallocate the communicator (overhead) • At the mpi_swap() call, make a swapping decision • Interface with MPICH • Within MPICH (difficult, feasible?, not portable) • With Hijacking interface (easy, not portable) • At the user level (easy, portable)
Our implementation (Usage) • compile with swap headers, link against libswap.a library • then just use the standard MPI invocation(mpich shown here)mpirun –np 23 fish –ap 8 • only additional required flag is the “-ap” option, which specifies the number of active processors. • The “-np” option specifies the total number (active + inactive) of processors • Other options allow further customization
Runtime System application swap library “inactive” processor swap archive Monitoring swap manager swap vis “active” processor swap admin
Overhead of Overallocation MPICh/mpirun, on Linux .75 seconds/processor
Overhead of Overallocation (2) • Overallocation causes bigger barriers • Barrier cost • Increase with #procs is roughly linear • Absolute value is “small”
Overhead of Overallocation (3) • Summary • Overallocation by 1 processor: • +.75s for mpirun • +.125s for bigger barrier • Example • 1000 iterations • Overallocate by 4 procs • Overhead = 4x.75 + 1000x.125x4 = 503s • .5s / iteration • Swapping costs more • Cost-benefit model…
Experimental Validation • Simulation • Built a simulator with Simgrid [CCGrid’01] • Running experiments right now with values plugged-in from experiments (overheads) • Experiments • Implemented applications • Fish code (N-body simulation) • Iterative Stencil Applications (Holly Dail’s GrADS work) • Our own lab • The HP enterprise computing environment
Very Preliminary Simulations • Simulate 16 processors, N-body simulations • Homogeneous system • Loaded with a simple ON-OFF process source with a parameter p • P = 0 Stable • P = 1 Unstable • Compare with unmodified and DLB • Assume no overhead for DLB (best case)
Simulations? • What is the right simulation model for a dynamic platform? • On-Off sources • Just a way to see what happens for now • NWS-like traces • We’ve done it before • We’ll do it here also • General question for research on scheduling in dynamic environments • That’s why we’ll do experiments at HP
Future Work • More simulations • Real experiments • Experiment with swapping policies • Better comparison with DLB (what if one over-allocate with DLB) • Release the MPI-swap library • Integrate into GrADSoft
Overhead of Overallocation (3) • Overallocation may cause bigger broadcasts • No multicast • Increase with #procs is roughly linear • Absolute value is “small”