Download

1 / 19
190 likes | 335 Views
A DSP with Caches: A Study of the GSM-EFR Codec on the TI C6211. Tor Jeremiassen Bell Labs, Lucent Technologies tor@research.bell-labs.com. Outline. DSPs TI C6211 DSP GSM-EFR Speech Transcoder Methodology Results Conclusion. Digital Signal Processors. Low price

E N D
A DSP with Caches:A Study of the GSM-EFR Codec on the TI C6211 Tor Jeremiassen Bell Labs, Lucent Technologies tor@research.bell-labs.com
Outline • DSPs • TI C6211 DSP • GSM-EFR Speech Transcoder • Methodology • Results • Conclusion
Digital Signal Processors • Low price • embedded in cheap devices, cell phones, disk drives, ABS brakes, modems, etc. • Low power • must be able to run off batteries • High (Enough) Performance • on the right applications • special hardware support to accelerate particular functions • saturating arithmetic, viterbi decode, manhatten distance • Deterministic running time, must satisfy hard real-time constraints • Strong bias against caches
TI C62xx Series DSP Features • 8 wide VLIW-like architecture • two clusters • Statically scheduled • “dependence” bit in instruction word controls parallel issue • Fixed size 32 bit instruction set - small number of inst. formats • Predicated execution - 5 predicate registers • 5 cycle branch delay, 4 cycle load delay • Compiler is not just an afterthought • Aimed at communication infrastructure • High performance, higher power, higher price (relatively speaking)
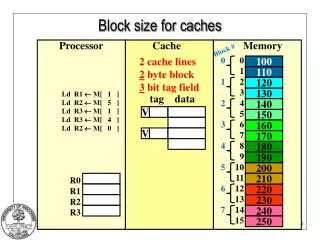
TI C6211 • Economy model of C62xx series • $25 vs. $80-$150 • Less memory on chip (cache vs. memory) 72 KB vs. 128 KB to 896 KB • Slower clock, 150 MHz vs. 200 MHz to 300 MHz • Cache organization: • I: 4 KB, 64 B, direct mapped • D: 4 KB, 32 B, 2-way, no write-allocate • 4 entry write-buffer • stall if full • empty before servicing read miss • L2: 0-64 KB, 128 B, 0-4 way Instruction Data 256 bits 128 bits Level 2 32 bits
GSM-EFR Speech Transcoder • Global System for Mobile Communications - Enhanced Full Rate • European Telecommunications Standards Institute • Used in digital cellular telephony • Encodes 64Kb/s input speech and 12.2 Kb/s parameter stream • Size: encoder 13,000 lines of C, decoder 9,500 lines of C • Encoder roughly 10x complexity of decoder Coded speech (12.2Kb/s) Speech (64 Kb/s)
Methodology • GSM-EFR Codec (encoder/decoder) • based on reference code supplied by ETSI • some loop optimizations applied by hand, simplified low level i/o • compiled using v2.10 of TI C6x compiler (-o3 + whole program opt.) • input: 1080 frames = 21.6 seconds of speech • Concatenation of GSM-EFR test vectors test10, test7 and test13. • Simulator • cycle accurate, instruction level simulator • cycles (excluding cache effects): encoder ~300M, decoder ~35M • Architecture • All second level memory used as cache except where noted • EMIF has priority over level one cache misses
Changing Level 2 Memory Organization • There is 64 KB of second level memory divided into 4, 16 KB blocks • 0 to 4 of the blocks can be configured as cache • set associativity is equal to the number of blocks configured as cache • cache block size is 128 B • Memory not configured as cache is local memory in a unique part of the address space • Experiments: • vary total second level memory available to application • vary the amount allocated as cache • use level 1 cache miss profiles to decide which blocks are put in local memory
Performance Effect of Cache Pollution • The TI C6x series DSPs are aimed at multi-channel applications • e.g., cellular base stations • Switching between multiple applications pollutes the cache w.r.t. any single application • interrupt handlers also contribute • Need to understand the performance implications of periodic cache pollution on the performance of single applications • Pessimistic experiments: • Invalidate both level one caches at periodic intervals • Invalidate entire cache hierarchy at periodic intervals
Conclusions • Caches work for DSPs! (at least for the GSM-EFR) • miss rates are low, similar number of cycles lost due to nops on C6211 • Worst case assumption about cache miss impact on running time is unwarranted. • performance degrades gracefully with frequency of invalidations • But, don’t DSPs work on streaming data (locality breakdown)? • yes, but the ratio of computation to the bandwidth of the data stream is low in most applications, and the locality is captured well in small caches • Trend is towards bigger and more complex applications on DSPs