Download

1 / 20
200 likes | 344 Views
Analiza danych w biznesie: problemy i rozwiązania na przykładzie banku detalicznego. Kim jest facet obsługujący rzutnik?. Nazywam się Sebastian Ptasznik i pracuję w Alior Banku. Zajmuję się przeprowadzaniem analiz na potrzeby sprawozdawczości zarządczej. Plan prezentacji (45 minut).

E N D
Analiza danych w biznesie: problemy i rozwiązania na przykładzie banku detalicznego
Kim jest facet obsługujący rzutnik? Nazywam się Sebastian Ptasznik i pracuję w Alior Banku. Zajmuję się przeprowadzaniem analiz na potrzeby sprawozdawczości zarządczej.
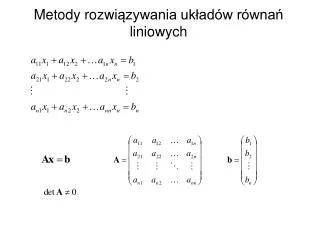
Plan prezentacji (45 minut) Wstęp (5 minut) • Czym jest model? Typowe problemy (20 minut) • Wnioskowanie • Overfitting • Przekleństwo wymiaru • Organizacja informacji/struktura organizacji/inne Jak zbudować dobry model? (15 minut) • Bootstraping • Stacking • Boosting Podsumowanie (5 minut) Pytania
Wstęp (1) Model jest to mechanizm, który pozwala wnioskować (generować prognozy) opierając się na danej informacji wejściowej. Może odpowiadać na różne pytania: ile wynosi wartość danego samochodu, z jakim prawdopodobieństwem Klient przestanie spłacać kredyt w następnym miesiącu, jaki będzie PKB w kolejnym kwartale, jaka jest zależność między inwestycjami bezpośrednimi a bezrobociem, czy klocek jest w kształcie serduszka, etc.
Wstęp (2): Przykłady modeli Fragment specyfikacji modelu (DSGE) używanego przez NBP do prognozowania zmian w gospodarce. Model zmiennej dla binarnej (drzewo decyzyjne) TAK NIE
Wnioskowanie (1) Widać wyraźną zależność między… Odkrywanie znanych zależności (Klient posiadający kartę debetową ma konto) (Klienci po 85 roku życia nie biorą kredytów hipotecznych) Wyciąganie nieistotnych statystycznie wniosków (Lewy słupek wyższy od prawego: „mężczyźni biorą wyższe pożyczki”) Wnioskowanie fałszu (Używanie nieodpowiednich narzędzi np. porównywanie jedynie średnich) (Jakiekolwiek wyniki lepsze niż brak wyników) Pojęcie „prawdy” w statystyce W świecie statystyki nie ma pojęcia „prawdy”, można jedynie z danym prawdopodobieństwem nie mieć podstaw do odrzucenia danej hipotezy. Nasza analiza daje fałszywe wnioski gdyż pominięte zostały ważne zmienne lub uchwycone zależności są przypadkowe.
Wnioskowanie (2) Wyciąganie nieistotnych biznesowo wniosków (dotyczące małej grupy, lub bez przełożenia na potencjalne zyski: „Najwięcej żonatych Stefanów jest w Gdyni”) Confidence/Support (Istotność wniosków a wielkość populacji, której dotyczą) (34 letni kawalerowie z Radomia o imieniu Tomek, których nr telefonu zaczyna się od „671” z prawdopodobieństwem 95% wezmą pożyczkę w ciągu następnego kwartału) Malutki fragment gdzie wiemy o co chodzi Badane Zjawisko
Overfitting (1)(przetrenowanie) Czym jest overfitting? Sytuacja gdy model opisuje dane, które posiadamy, nie zjawisko, które je wygenerowało. Wniosek: Każdy Stefan bierze kredyt na frytkownicę Wiązka zależności MODEL
Overfitting (2) Dlaczego się pojawia? Przyczyny techniczne: Używamy za dużo zmiennych, więc łatwiej jest znaleźć nieprawdziwe zależności, które przypadkowo dobrze pasują do tego co obserwujemy. Wybierane są modele najlepiej dopasowane do danych, które „dobrze wyglądają” w chwili analizy, nie koniecznie te dające dobre (stabilne) prognozy. Przyczyny pozatechniczne: Wybieranie wyników, które są zgodne z przekonaniami analityka lub oczekiwaniami przełożonych (szukajcie a znajdziecie). Bardzo łatwo usprawiedliwić złe własności prognostyczne opracowanego rozwiązania.
Przekleństwo Wymiaru (1) (curse of dimensionality) Wraz ze zwiększającą się ilością obserwowanych cech, drastycznie wydłuża się czas potrzebny na dokonanie obliczeń. Istnieje większa skłonność modeli do overfitting’u. Problemy z software’em i sprzętem (350x 16 500 000) Przykład: szukanie reguł asocjacyjnych (jeżeli A to B) dla 250 000 Klientów i 2 zmiennych trwa około 30-60 minut. Dla 5 zmiennych i reguł typu (jeżeli A i B to C) czas wydłuża się ~30 krotnie. Dla 10 zmiennych i reguł typu (jeżeli A i B i C to D) już 2520 krotnie. Dane transakcyjne potrafią zawierać setki zmiennych… Nie wiedząc gdzie szukać, zazwyczaj niczego się nie znajduje. Obliczenia trwające kilka dni nie są niczym niezwykłym (podobnie jak brak wyników). Trudniej jest wybrać cechy istotne w danym badaniu.
Przekleństwo Wymiaru (2) Od czego zależy wynagrodzenie ? Sytuacja nr 1 wersja szowinistyczna ;) Sytuacja nr 2
Organizacja informacji/struktura organizacji/inne • Brak odpowiedniego software’u. • Potrzebne dane są w 9 różnych martach, 2 plikach csv, 1 excelu, 2 systemach zewnętrznych, maja rożne formaty, różne struktury, są zgodne tylko w ujęciu kwartalnym. • Dane są tragicznej jakości (korekty, braki, obciążenia, błędy). • Brak danych. • Czas przeznaczony na analizę stanowi 10-20% czasu potrzebnego by ją przeprowadzić. • Wyniki 3 tygodniowej pracy należy zaprezentować na 2-3 slajdach, najlepiej graficznie. (swoją analizę należy „sprzedać”) Źródło: Dilbert.com
Bootstraping Metoda polegająca na wielokrotnym losowaniu ze zwracaniem z próby, a następnie wykonywania dla każdej z podprób przeliczeń i obserwacji zmienności otrzymywanych w ten sposób wyników. Przykład 1. Badamy czy nasz model jest wrażliwy na dane na jakich jest budowany. Przykład 2. Badamy czy wnioski/prognozy otrzymywane z naszego modelu są stabilne.
Boosting Metoda polegająca na łączeniu kilku słabych modeli w jeden mocny. Każdy słaby model staje się „ekspertem” w wąskim wycinku badanego zjawiska. Modele składowe drogą głosowania decydują jaki jest końcowy wniosek/predykcja ( „ekspert” ma największą wagę głosu gdy obserwacja jest jego „specjalizacją”) .
Meta-modele (1)(Stacked Generalization) Gdyby przeciętny meta-model byłby zwierzęciem, wyglądałby mniej więcej tak ;-) … W metodzie tej łączy się wnioski/predykcje pochodzące z różnych modeli, w taki sposób by zmaksymalizować korzyści płynące z wykorzystania różnych narzędzi (każde z nich może szukać innego typu zależności między danymi). Może być to proste uśrednianie, jak również zbudowanie modelu, który wnioskuje opierając się na predykcjach innych modeli. Meta-model jest hybrydą.
Podsumowanie Model jest mechanizmem wnioskowania Łatwo popełnić błąd podczas analizy Trudno bez wiedzy eksperckiej na temat danego zjawiska je badać Poza technicznymi przeciwnościami istnieje cała gama innych czynników utrudniających pracę Dobry model musi dawać stabilne wyniki, by to osiągnąć warto skorzystać z symulacji i kombinowania prognoz.
Kontakt Sebastian.Ptasznik@gmail.com Sebastian.Ptasznik@alior.pl