Download
1 / 31
320 likes | 877 Views
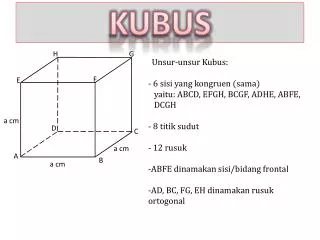
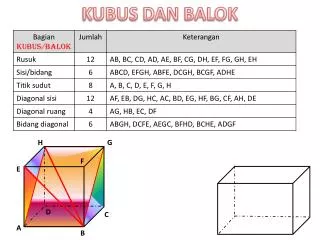
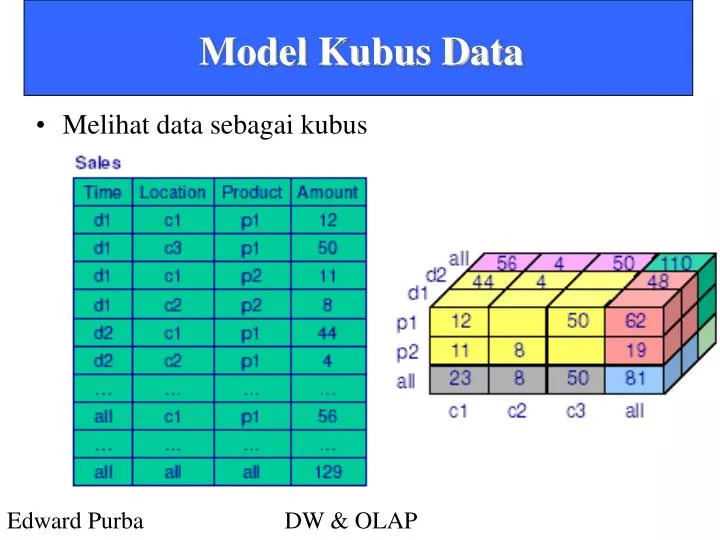
Model Kubus Data. Melihat data sebagai kubus. Skema Star (Dalam RDBMS). Ukuran. Contoh Skema Star. Ukuran. Skema Star Dengan Data Sampel. Skema Star Dengan Data Sampel. Fakta product nomor 110 selama periode 002:

E N D
Model Kubus Data • Melihat data sebagai kubus
Skema Star (Dalam RDBMS) Ukuran
Contoh Skema Star Ukuran
Skema Star Dengan Data Sampel
Skema Star Dengan Data Sampel • Fakta product nomor 110 selama periode 002: • 30 unit terjual di toko S1. Total penjualan dalam dollar 1500, dan total cost dalam dollar 1200 • 40 unit terjual di toko S3. Total penjualan dalam dollar 2000, dan total cost dalam dollar 1200 • Ukuran tabel fakta: • Misal jumlah total toko 1000, jumlah total product 10000, jumlah total periode 24 (data berharga 2 tahun) • Misal rata-rata 50% (atau 5000) record penjualan selama suatu bulan tertentu.
Skema Star Dengan Data Sampel • Ukuran tabel fakta: • Taksiran jumlah baris dalam tabel fakta dihitung sebagai berikut: • total baris= 1000 toko x 5000 produk aktif x • 24 bulan • = 120,000,000 baris • Tebal fakta memiliki 6 field, dimana rata-rata field panjangnya 4 byte. • Total size=120,000,000 baris x 6 field x 4 byte/field = 2,880,000,000 bytes
Skema Star “Klasik” • Suatu tabel fakta tunggal dengan data detail dan ringkasan • Primary key tabel fakta hanya memiliki satu kolom key per dimensi • Masing-masing key dibangun • Masing-masing dimensi adalah suatu tabel tunggal, yang didenormalisasi Keuntungan: Mudah dipahami, mudah didefinisikan secara hierarki, mengurangi jumlah join fisik, low maintenance, metadata sangat sederhana Kekurangan: Ringkasan data dalam tabel fakta menghasilkan kinerja yang buruk untuk level ringkasan dan juga untuk tabel dimensi yang besar
Skema Star “Klasik” Kekurangan terbesar: tabel dimensi harus membawa suatu indikator level sehingga setiap record dan setiap query harus menggunakannya. Dalam contoh dibawah, tanpa level kendali, key untuk seluruh store dalam region NORTH, termasuk agregasi pada region dan distrik akan dikeluarkan dari tabel fakta, mengeluarkan error. Contoh: Select A.STORE_KEY, A.PERIOD_KEY, A.dollars from Fact_Table A where A.STORE_KEY in (select STORE_KEY from Store_Dimension B where region = “North” and Level = 2) dan seterusnya….. Level diperlukan bila agregasi disimpan dengan fakta detail.
Problem “Level” • Level adalah suatu problem sebab level potensial menyebabkan error. Jika pembuat query, manusia atau program, melupakan ini, jawaban yang salah dipastikan bisa terjadi. • Salah satu alternatif: model konstelasi fakta...
Skema Konstelasi Fakta District Fact Table Region Fact Table District_ID PRODUCT_KEY PERIOD_KEY Region_ID PRODUCT_KEY PERIOD_KEY Dollars Units Price Dollars Units Price
Skema Konstelasi Fakta Dalam konstelasi fakta, tabel agregasi dibuat terpisah dari detail, karenanya adalah tak mungkin mengambil, misalnya, detail Store ketika meng-query tabel fakta District. Keuntungan Utama: Indikator “Level” tidak diperlukan lagi didalam tabel dimensi, karena tidak ada data agregasi yang disimpan dengan level detail lebih rendah. Kerugian:Tabel dimensi masih tetap sangat besar dalam beberapa kasus, yang akan memperlambat kinerja; front-end harus mampu mendeteksi keberadaan fakta agregasi, yang memerlukan metadata yang lebih ekstensif
Alternatif Lain Untuk “Level” • Konstelasi fakta adalah suatu alternatif yang baik untuk skema star, tetapi ketika dimensi memiliki kardinalitas yang sangat tinggi, sub-selects dalam tabel dimensi bisa menjadi suatu sumber kelambatan. • Suatu alternatif adalah menormalisasikan tabel dimensi melalui level atribut, dimana setiap tabel dimensi yang lebih kecil menunjuk ke suatu tabel agregasi fakta yang sesuai, “Skema Snowflake” ...
Store Dimension STORE KEY District_ID Region_ID Store Description City State District ID District Desc. Region_ID Region Desc. Regional Mgr. District Desc. Region_ID Region Desc. Regional Mgr. Store Fact Table District Fact Table RegionFact Table Region_ID PRODUCT_KEY PERIOD_KEY District_ID PRODUCT_KEY PERIOD_KEY STORE KEY PRODUCT KEY Dollars Units Price PERIOD KEY Dollars Units Price Dollars Units Price Skema Snowflake
Skema Snowflake • Tidak ada LEVEL dalam tabel dimensi • Tabel dimensi dinormalisasikan dengan menguraikan pada level atribut • Masing-masing tabel dimensi memiliki satu key untuk setiap level dari hierarki dimensi • Key level terendah mengabungkan tabel dimensi ke tabel fakta dan tabel level atribut lebih rendah Bagaimana ini bekerja? Cara terbaik query dibangun adalah dengan memahami level ringkasan apa yang ada, dan mencari tabel atribut snowflake normal, membatasinya untuk kunci, lalu memilih dari tabel fakta
Skema Snowflake • Fitur tambahan: tabel dimensi Store asli, yang didenormalisasi sepenuhnya, dipertahankan utuh, karena query tertentu bisa mengambil keuntungan melalui seluruh isi yang dikandungnya. • Dalam praktek, mulai dengan skema start dan buat “snowflakes” dengan query. Ini mengurangi kebutuhan untuk membuat ekstraksi terpisah untuk setiap tabel, dan integritas referensial diwarisi dari tabel dimensi Keuntungan: Kinerja terbaik saat query melibatkan agregasi Kerugian: maintenance dan metadata yang rumit, ledakan jumlah tabel didalam database
Suatu Konsep Hierarki: Dimensi (location) all all Europe ... North_America region Germany ... Spain Canada ... Mexico country Vancouver ... city Frankfurt ... Toronto L. Chan ... M. Wind office
Data Multidimensi • Volume Sales sebagai suatu fungsi dari product, month, dan region Dimensi: Product, Location, Time Path intisari hierarkikal Region Industry Region Year Category Country Quarter Product City Month Week Office Day Product Month
Contoh Kubus Data Volume Sales sebagai suatu fungsi time, city, dan product NY LA SF Juice Cola Milk Cream 10 47 30 12 3/1 3/2 3/3 3/4 Date
Contoh Kubus Data Total penjualan TV Setahun di U.S.A. Date 2Qtr 1Qtr sum 3Qtr 4Qtr TV Product U.S.A PC VCR sum Canada Country Mexico sum Semua, Semua, Semua
Bentuk Kubus Yang Terkait Dengan Kubus Data 0-D(apex) cuboid all country product date 1-D cuboids product,country date, country product,date 2-D cuboids product, date, country 3-D(base) cuboid
Browsing Suatu Kubus Data • Visualisasi • Kapabilitas OLAP • Manipulasi Interaktif
Operasi Kubus Data OLAP • Roll up (drill-up): merujuk ke peningkatan hierarki atau pengurangan dimensi (diberikan total sales by “city”, di roll-up untuk mendapatkan total sales by “state”) • Drill down (roll down, kebalikan roll-up): merujuk ke penurunan hierarki atau penambahan dimensi (diberikan total sales by “state”, di roll-down untuk mendapatkan total sales by “city”) • Slice: merujuk ke pemilihan dimensi yang digunakan untuk melihat kubus (“customer” by “product” by “date”)
Operasi Kubus Data OLAP • Dice: merujuk ke pemilihan posisi sesungguhnya sepanjang dimensi (bagian dari kubus slice dimana product = “Mr. Snowman”) • Pivot (rotasi): reorientasi kubus, visualisasi, 3D ke sebarisan bidang 2D • Operasi lain: • drill across:melibatkan lebih dari satu tabel fakta • drill through:melalui level terbawah dari kubus tersebut ke tabel back-end relasionalnya (menggunakan SQL)
Rancangan Suatu Data Warehouse: Suatu Kerangka Analisa Bisnis • Tinjauan perihal rancangan dari suatu data warehouse • Top-down • Memungkinkan seleksi informasi yang relevan, yang perlu untuk data warehouse (perspektif user) • Sumber data • Membuka informasi yang akan ditangkap, disimpan, dan ditangani oleh sistem operasi (perspektif sumber data)
Rancangan Suatu Data Warehouse: Suatu Kerangka Analisa Bisnis • Data warehouse • Terdiri dari tabel-tabel fakta dan dimensi tabel (tinjauan dari dalam data warehouse) • Query bisnis • Melihat perspektif data dalam warehouse dari sisi tinjauan end-user