Download

1 / 44
440 likes | 659 Views
La biologie change. Marie-Claude.Blatter@isb-sib.ch Institut Suisse de Bioinformatique Groupe Swiss-Prot novembre 2006. Un des changements important. Nouvelles technologies: -> arrivée de données biologiques en ‘masse’ -> utilisation de l’informatique

E N D
La biologie change... Marie-Claude.Blatter@isb-sib.ch Institut Suisse de Bioinformatique Groupe Swiss-Prot novembre 2006
Un des changements important Nouvelles technologies: -> arrivée de données biologiques en ‘masse’ -> utilisation de l’informatique pour le stockage et l’analyse de données biologiques. Rôle important joué par la ‘bioinformatique’
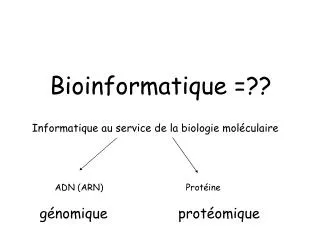
La bioinformatique, c’est quoi ? L’utilisation de l’informatique pour l’analyse de données biologiques.
Bioinformatique • Surtout: • Biologie + Informatique • Biochimie + Informatique • Mais aussi… • Médecine + Informatique • Pharmacie + Informatique • Chimie+ Informatique • Mathématique + Informatique • Statistique + Informatique • C’est un domaine pluridisciplinaire!
Bioinformatique • Surtout: • Biologie + Informatique • Biochimie + Informatique Pourquoi faire ?
Acquérir puis stocker les informations biologiques sous la forme d’encyclopédies appelées bases de données; Encyclopédies informatisées
Exemples de données ‘biologiques’ qui ne peuvent plus être gérées sans l’aide de l’informatique: • - Séquences: ADN (génomes), ARN, protéines • - Structures 3D: ADN, ARN, protéines, sucres… • Classification des espèces • Voies métaboliques • Expression des gènes (microarrays) • Spectrométrie de masse • - Publications scientifiques • … Beaucoup de ‘omics’, mais… !
Acquérir puis stocker les informations biologiques sous la forme d’encyclopédies appelées bases de données; Développer des programmesde prédiction et d’analyse en utilisant les informations contenues dans les bases de données; Analyser/Interpréter/Prédire: utiliser ces programmes pour analyser de ‘nouvelles’ données biologiques et prédire in silico par exemple la fonction potentielle d’une protéine;
Conclucion d’une analyse in silico d’une protéine inconnue Poids moléculaire: 126 kD; Fonction: ATPase potentielle; Localisation subcellulaire: Membrane plasmique. Transmembranaire (~10 hélices); N terminal: intracellulaire; C terminal: intracellulaire PTM: Phosphorylée Ça me semble bio-logique …mais reste à le prouver !
Acquérir puis stocker les informations biologiques sous la forme d’encyclopédies appelées bases de données; Développer des programmesde prédiction et d’analyse en utilisant les informations contenues dans les bases de données; Analyser/Interpréter/Prédire: utiliser ces programmes pour analyser de ‘nouvelles’ données biologiques et prédire in silico par exemple la fonction potentielle d’une protéine; Visualiser: développer des programmes pour visualiser la structure en trois dimensions des protéines et de l’ADN, pour shématiser des voies métaboliques ou des arbres phylogénétiques.
Dendogramme Le Mammouth et l’éléphant ont un ancêtre commun ! Exemple d’un dendrogramme obtenu à partir d’un résultat de CLUSTALW à l’aide du programme « phylodendron » Le Dodo et le poulet ont un ancêtre commun ! Arbre obtenu avec le cytochrome B (phylophilo) 9
HIV: exemple d’application de la bioinformatique • 1984: identification du virus;
HIV: exemple d’application de la bioinformatique • 1984: identification du virus; • 1985: séquençage du génome de HIV-1 ; (4 laboratoires dont Montagnier/France et Gallo (USA) (??))
HIV: exemple d’application de la bioinformatique • 1984: identification du virus; • 1985: séquençage du génome de HIV-1 ; (4 laboratoires dont Montagnier/France et Gallo (USA) (??)) • 1985-1989: caractérisation des protéines; • 1989: structure X-ray de la protéase;
HIV: exemple d’application de la bioinformatique • 1984: identification du virus; • 1985: séquençage du génome de HIV-1 ; (4 laboratoires dont Montagnier/France et Gallo (USA) (??)) • 1985-1989: caractérisation des protéines; • 1989: structure X-ray de la protéase; • 1990: premiers inhibiteurs modélisés à partir de la structure 3D de la protéase
HIV: exemple d’application de la bioinformatique • 1984: identification du virus; • 1985: séquençage du génome de HIV-1 ; (4 laboratoires dont Montagnier/France et Gallo (USA) (??)) • 1985-1989: caractérisation des protéines; • 1989: structure X-ray de la protéase; • 1990: premiers inhibiteurs modélisés à partir de la structure 3D de la protéase • Novembre 1995: premier médicament (Invirase) approuvé par la FDA (trithérapie).
Quelques remarques • Il n’existe pas une “banque centrale” qui contient toutes les infos: il est toujours nécessaire de grapiller les infos dans différentes banques.
Quelques remarques • Il n’existe pas une “banque centrale” qui contient toutes les infos: il est toujours nécessaire de grapiller les infos dans différentes banques. • Les données s'accroissent quotidiennement (il y a en moyenne un nouveau génome séquencé toutes les semaines) et sont continuellement remises à jour: le résultats de vos requêtes peut donc être différent d'un jour à l'autre (contenu, liens ou “look”) !
3. Beaucoup de chercheurs travaillent sur le même sujet -> un gène, plusieurs séquences ->redondance. Ces séquences peuvent être différentes (erreurs de séquençage ou mutations, longueurs variables).
3. Beaucoup de chercheurs travaillent sur le même sujet -> un gène, plusieurs séquences ->redondance. Ces séquences peuvent être différentes (erreurs de séquençage ou mutations, longueurs variables). 4. Importance du numéro d’accession: identificateur d’une information biologique (1 séquence, 1 spot sur un gel, 1 structure 3D…)
3. Beaucoup de chercheurs travaillent sur le même sujet -> un gène, plusieurs séquences ->redondance. Ces séquences peuvent être différentes (erreurs de séquençage ou mutations, longueurs variables). 4. Importance du numéro d’accession: identificateur d’une information biologique (1 séquence, 1 spot sur un gel, 1 structure 3D…) 5. Les banques de données sont liées entre elles (“links”, cross-références ->réseau). Ces liens ne sont pas toujours bidirectionnels !
3. Beaucoup de chercheurs travaillent sur le même sujet -> un gène, plusieurs séquences ->redondance. Ces séquences peuvent être différentes (erreurs de séquençage ou mutations, longueurs variables). 4. Importance du numéro d’accession: identificateur d’une information biologique (1 séquence, 1 spot sur un gel, 1 structure 3D…) 5. Les banques de données sont liées entre elles (“links”, cross-références ->réseau). Ces liens ne sont pas toujours bidirectionnels ! 6. Les banques de données contiennent des erreurs !
Conclusions Extraordinaire potentiel de la bioinformatique… mais ne elle ne remplace(ra) pas les expériences «wet lab» génomiques, protéomiques et autres, ni l’esprit critique humain (contexte bio-logique) ! La bioinfo fournit des outils performants aux biologistes… Les données expérimentales des biologistes permettent d’améliorer les programmes bioinformatiques (prédiction)…
Patrick Descombes • Biomedical Proteomics Research Group (BPRG) • Plateforme Génomique • Frontiers in Genetics • Centre Médical Universitaire (CMU) • ‘Génomique’ • Mise en place des techniques d’analyse de l’expression des gènes • Mise à la disposition des chercheurs d’une plateforme ‘génomique’
Jean-Charles Sanchez • Biomedical Proteomics Research Group (BPRG) • Department of Structural Biology and Bioinformatics • Centre Médical Universitaire (CMU) • Pionnier de la ‘protéomique’ (depuis 1989) • Mise en place des techniques d’analyse des protéines • Mise à la disposition des chercheurs d’une plateforme ‘protéomique’ • Recherche de biomarqueurs (AVC et diabète)
Amos Bairoch • Groupe Swiss-Prot • Centre Médical Universitaire (CMU) • Pionnier de la ‘bioinformatique’ • Programmes d’analyse in silico des protéines • Créateur de la banque de données Swiss-Prot • Intéressé par l’’exobiologie’
Bioinformatique - application 1:acquisition de données • Exemples: lecture d’images de gels 2D, spectrométrie de masse (MS), séquençage ADN... • Détection de signaux ou d’images • Absence de contexte biologique.
Séquençage d’ADN Informatique instrumentale Programme pour analyser les données d’un séquenceur ADN Exemple: pregap4 de Rodger Staden https://sourceforge.net/projects/staden.
Bioinformatique - application 2: Analyse de séquences ADN • Détection des régions codantes; • Recherche de similarité (BLAST) • Analyse des sites de restriction (enzymes); • Traduction ADN en protéine; • Détection de séquences « répétées » comme les microsatellites, minisatellites, Alu repeats, etc.; • Détection de régions ADN importantes non-codantes comme les signaux de transcription (promoteur), origines de la réplication, etc.; • Détection de séquences de tARN et autres types de ARN (exemples: rARN, uARN, tmARN).
1997 1003 1661 1406 1083 2 3 1 4 1452 1305 1914 Schéma récapitulatif Genebuilder prédiction 5 ’ 3 ’ exons 1 2 3 4 ADN génomique Splicing / Epissage « in silico » 1 2 3 4 mARN mature EST => cDNA
Des cas moins idéaux… Ex: Chromosome 21
Bioinformatique- application 3:analyse de la séquence primaire des protéines • Caractérisation physicochimique • Prédiction de la localisation subcellulaire (“signal séquences”, “transit peptides”); • Recherche de régions transmembranaires; • Recherche des régions fonctionnelles (domaines conservés) • Recherche de sites de modifications post-traductionelles (PTM). • Recherche de régions antigéniques; • Recherche de régions dont la composition est biaisée (“low complexity sequences”);
Bioinformatique - application 4:comparaison de séquences • Mettre en relation 2 séquences en comparant les acides aminés à chaque position et en tenant compte de leur probabilité de mutation au cours de l’évolution; MY-TAIL--ORIS-RICH- #x #### x#x# #### MONTAILLEURESTRICHE (algorithme pour comparer des chants d’oiseaux)
Bioinformatique - application 5:phylogénétique • Reconstruction de l’évolution des espèces; • Reconstruction de l’évolution moléculaire des familles de protéines; • Reconstruction de l’évolution des chemins métaboliques.
? Bioinformatique - application 6analyse de la structure secondaire & modélisation des protéines MSTNNYQTLSQNKADRMGPGGSRRPRNSQHATASTPSASSCKEQQKDVEH EFDIIAYKTTFWRTFFFYALSFGTCGIFRLFLHWFPKRLIQFRGKRCSVE NADLVLVVDNHNRYDICNVYYRNKSGTDHTVVANTDGNLAELDELRWFKY RKLQYTWIDGEWSTPSRAYSHVTPENLASSAPTTGLKADDVALRRTYFGP NVMPVKLSPFYELVYKEVLSPFYIFQAISVTVWYIDDYVWYAALIIVMSL YSVIMTLRQTRSQQRRLQSMVVEHDEVQVIRENGRVLTLDSSEIVPGDVL VIPPQGCMMYCDAVLLNGTCIVNESMLTGESIPITKSAISDDGHEKIFSI DKHGKNIIFNGTKVLQTKYYKGQNVKALVIRTAYSTTKGQLIRAIMYPKP ADFKFFRELMKFIGVLAIVAFFGFMYTSFILFYRGSSIGKIIIRALDLVT IVVPPALPAVMGIGIFYAQRRLRQKSIYCISPTTINTCGAIDVVCFDKTG TLTEDGLDFYALRVVNDAKIGDNIVQIAANDSCQNVVRAIATCHTLSKIN NELHGDPLDVIMFEQTGYSLEEDDSESHESIESIQPILIRPPKDSSLPDC Structure d’une protéine Séquence d’une protéine
Avant … Après …