Download

1 / 40
400 likes | 611 Views
Interconnect-Centric Approach to System on a Chip (iSoC) for Low-Power Signal Processing. 성균관대 조준동 . 차례 . 재구성 플랫폼 Software Defined Radio SW/HW 통합 설계 사례 SW/HW 통합 설계 도구 Network on Chip 연구실 소개 연구 제안 . SoC and Customizable Platform Based-Design. DSP . Reconfigurable Hardware

E N D
Interconnect-Centric Approach to System on a Chip (iSoC) for Low-Power Signal Processing 성균관대 조준동
차례 • 재구성 플랫폼 • Software Defined Radio • SW/HW 통합 설계 사례 • SW/HW 통합 설계 도구 • Network on Chip • 연구실 소개 • 연구 제안
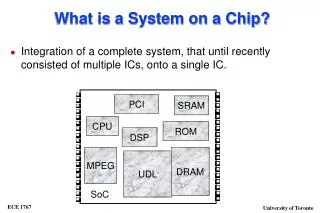
SoC and Customizable Platform Based-Design DSP Reconfigurable Hardware (Fine Grain) ASIC 2 Reconfigurable Hardware (Coarse Grain) ASIC 1
hardware people new breed needed CS people µproc., memory LSI, MSI ASICs, accel’s Semiconductor Revolutions- Makimoto’s wave TTL FPGAs soft CPUs 2007 1967 1987 1957 1977 1997 coarse grain
Abstract • iSoC는 SoC design 의 scalability, flexibility를 향상시키기 위한 on-chip communication architecture • Dynamic Configuration • iSoC 의 규칙적이고 유연한 구조는 global communication을 위한 traffic, power, speed, area requirement 모델링을 위해 예측 가능한 framework를 제공
IBM’s Coreconnect 초기의 32 비트에서 시작하여 128비트까지 대역폭을 확장
SMART (Sonics Methodology and Architecture for Rapid Time-to-Market) • plug-and-play on-chip communications network • Packet-based • 50 employees in a year • IP 및 설계환경 제공, SoC 설계 지원 • Cadence와 연합 • SiliconBackplne III는 통신+미디어
Nexperia Digital Video Platform • Designing the initial platform, along with the pnx8500, wasn't quick and easy. • It involved about 300 hardware, software and systems people working between 1999 and 2001, of which 60 were involved with hardware.
발전 방향 • 멀티미디어 응용 제품의 확대와 이에 필요한 대용량의 burst 데이터 전송요구를 만족하기 위한통신 대역폭을 확장 • Dual-Core Architecture (ARM+DSP)
온칩 네트워크 아키텍처 ● Router/Scheduler 알고리즘 개발 ● SystemC를 이용한 네트워크 모델 설계 및 검증 ● Star형/Mesh형 온칩 네트워크 핵심 IP 설계 ● Master/Slave 네트워크 인터페이스, 고성능 메모리 관리 인터페이스 설계
온칩 네트워크 기반 SoC설계 플랫폼 구축 및 설계 환경 ● 분산형 Crossbar Switch Topology 생성 및 IP 맵핑 툴 개발 ● IP to Mesh Tile 맵핑 툴 개발 ● IP간 데이터 플로우 분석 기반 네트워크 Topology 생성 툴 개발, SoC 플랫폼 구축
활용 분야 - QoS를 보장하는 프로토콜을 지원하여 Real Time Application 및 대용량 데이터 대역폭이 요구되는 응용 분야에 적합 - 멀티미디어 SoC, 휴대 및 통신용 단말기, 인터넷 셋톱 박스, 게임기, 네트워크 단말의 제품 구현에 필요한 시스템 레벨 칩 등 - high frame rate video 및 3D 그래픽 관련 등과 같은 멀티미디어 대용량 응용분야 SoC 설계 - 온칩 네트워크 핵심 IP 및 설계 지원 툴을 하나의 플랫폼화한 플랫폼 기반 설계 환경을 구축하여 이를 다양한 SoC 설계에 활용함
최근 연구동향 • Intel’s Reconfigurable Radio Architecture. (mesh + nearest neighbor) • Reconfigurable Baseband Processing, Picochip • Portable Components using Containers for Heterogeneous Platforms, Mercury Computer Systems, Inc. • A configurable Platform, Altera, Excalibur, Xilinx Virtex FPGA • Adaptive Computing Machine, Quicksilver Tech. • Mercury, Sky, Galileo, Tundra (crossbars, bridges) • Virginia Tech’s reconfigurable hardware
66% chips are not OK on first silicon (2004) Mid-90s – 6 months late = > 31% earnings loss Today 3 month late = $500M loss
Full Application Platform • users design full applications on top of hardware and software architectures • Nexperia • Texas Instrument's OMAP multimedia platform • Infineon's M-Gold 3G wireless platform, • Parthus' Bluetooth platforms • ARM's PrimeXsys wireless platform
processor-centric platform • focus on access to a configurable processor but doesn't model complete applications • Improv Systems • ARC • Tensilica • Triscend
communication- centric platform • interconnect architecture but doesn't typically provide a processor or a full application • Sonics' SiliconBackplane • PalmChip's CoreFrame architectures.
fully programmable platform • consisting of FPGA logic and a processor core • Altera's Excalibur, Xilinx' Virtex-II Pro and Quicklogic's QuickMIPS • Xilinx-IBM XBlue architecture
Introduction • Wireless processing system은 높은 throughput과 함께 많은 계산을 필요로 하지만 엄격한 power 제약이 있음 • 재구성 SoC 구현은 parallelism 에 의해 성능향상을 시도하고, IP reuse를 사용 • Hot spot bottleneck(or traffic)에 의한 성능 예측을 통한 Algorithm partitioning
Introduction • Scheduled interconnect • Link utilizations are substantially smaller than the bus since communication is distributed and pipelined throughout the system. • Eliminate the congestion caused by the bus and header overhead presen in dynamic routing. • Reconfigurable Architecture Workstation (RAW) project has re-examined static communication as a mechanism for general-purpose computing. • 규칙적인 연결구조와 정적인 스케줄링은 불필요한 interconnect switching 을 제거 • 전체 core 에서 Computational load 의 균형을 맞추어 성능향상 • Overhead of the configuration streams • Configuration streams must be scheduled periodically along with the data • 4% 의 bandwidth를 configuration stream 이 사용 • Data content variation 과 system operating 환경에 따라 core interface 와 core 자체가 low power 모드로 동적 재설정
Scheduled Communication • A tiled architecture • 각 tile은 computational core 이며 각 interface가 네트웍을 구성 • Core interface는 하나 이상의 tile 에서 발생하는heterogeneous processing의 사용을 제공함 • The system connect using statically scheduled mesh of interconnect • Data 는 이웃하는tile 과 communication pipeline 에 의해 이동하므로 fast clock rate 와 interconnection resource의 시 분할이 가능 • Core 와 runtime interconnect 의 재설정 능력에 의해 dynamic power management 를 가능케 한다.
Communication Interface • Stream data that passes through a communication • interface is scheduled for a specific communication • - clock cycle based on data link availability. • the result of scheduling for each interface is a set of • instructions for its associated interconnect memory.
Dynamic Power Management • Dynamic Power Management 는 data content 의 run-time variation에 따른 서로 다른 clock domain을 이용한 frequency 의 감소로 인한 power saving • DCT 구현에서 계산 결과 값이 변하지 않는 high order bit는 bypass 하여 switching을 제거 • Valid data stream data일 경우만 연결시켜 불필요한 switching 을 제거 • Prefetch many frames in a optimal-sized buffer [npettis@purdue.edu]
Dynamic Power Management • Reconfigurable clock based system balancing creates an environment of just in time computing which can reduce overall power usage. • Taking advantage of interconnect flexibility allows a system to dynamically change functionality and avoid unused computational units. • Interconnect power consumption is low and the overhead due to configuration streams is under 10% for both bandwidth and power.
Power Metric • Based on network activity and HSPICE circuit simulation of interconnect, the network power consumption(Pint) is: T : represents the number of tiles PIF/D: overhead of the instruction memory fetch and decode s: the number of stream Nvsand Nivs: the number of valid and invalid transfer for stream s while Ps is the power consumed in transferring 1 bit through stream s
iSOC Compiler • divides applications into parts, each of which fit into a specific core. • determines data communications between the cores in a space-time fashion • generate interconnect memory contents for each individual interface.
References • aSOC: A Scalable, Single-Chip Communications Architecture Jian Liang, Sriram Swaminathan, and Russell Tessier Department of Electrical and Computer Engineering University of Massachusetts, Amherst, MA. 01003. {jliang, tessier}@ecs.umass.edu • Configurable Platforms With Dynamic Platform Management: An Efficient Alternative to Application-Specific System-on-Chips • Krishna Sekar Kanishka Lahiri Sujit Dey • ksekar@ece.ucsd.edu klahiri@nec-labs.com dey@ece.ucsd.edu • Dept. of ECE, UC San Diego, La Jolla, CA • NEC Laboratories America, Princeton, NJ
OMAPTM(open multimedia application platform) • OMAP architecture는 platform의 전체 clocking과 idle mode의 전체 control을 할 수 있는 SW/OS가 있다. • Dual core architecture는 task에 대해 가정 적당한 process에게 task를 할당하는 것이 가능
ED2 • SMT (Simultaneous Multi-Threading) 20% speed-up and 24% power overhead [yingmin@cs.virginia.edu] using PowerTimer, PowerPC simulator Slow-down using DVS: 10% energy gain, scheduling:15% every saving increase
Time-Space Exploration • Enumerate all Trade-off’s and select the one with the most benefit. • Branch and Bound method for estimating every SoC metric.
Jiang Xu and Wayne WolfPrinceton University First decide an architecture, and assign estimated requirements to unavailable modules. Adjust the requirements using performance analysis in a trial-and-error fashion. Based upon the requirements purchase IP cores and design customized modules. May need several iterations to reach a final design. It is very helpful, if designers can get performance models of IP cores before buy them. Cadence Virtual Component Co-design(VCC)