Download

1 / 30
300 likes | 489 Views
Modelos Alternativos (1) M. Andrea Rodríguez Tastets DIIC - Universidad de Concepción http://www.inf.udec.cl/~andrea. Algebraic. Set Theoretic. Generalized Vector Lat. Semantic Index Neural Networks. Structured Models. Fuzzy Extended Boolean. Non-Overlapping Lists Proximal Nodes.

E N D
Modelos Alternativos (1)M.Andrea Rodríguez TastetsDIIC - Universidad de Concepciónhttp://www.inf.udec.cl/~andrea
Algebraic Set Theoretic Generalized Vector Lat. Semantic Index Neural Networks Structured Models Fuzzy Extended Boolean Non-Overlapping Lists Proximal Nodes Classic Models Probabilistic boolean vector probabilistic Inference Network Belief Network Browsing Flat Structure Guided Hypertext Modelos U s e r T a s k Retrieval: Adhoc Filtering Browsing
Ejemplo: Boolean q = k1 (k2 k3) Qdnf = (1,1,1) (1,1,0) (1,0,0)
Ejemplo: Vector (1) q = ka (kb kc) Qdnf = (1,1,1) (1,1,0) (1,0,0)
Ejemplo: Vector (2) q = k1 (k2 k3) Qdnf = (1,1,1) (1,1,0) (1,0,0)
Ejemplo: Vector (3) q = k1 (k2 k3) Qdnf = (1,1,1) (1,1,0) (1,0,0)
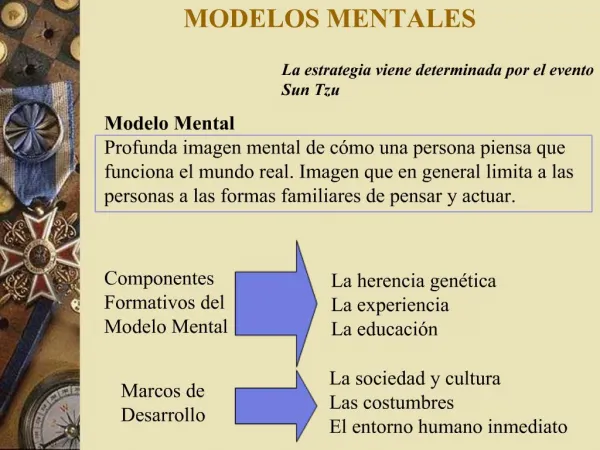
Modelos Basados en Teoría de Conjuntos • El modelo Booelan impone un criterio binario para determinar relevancia. • La pregunta es entonces cómo extender el modelo Boolean para acomodar la correspondencia parcial. • Dos estrategias son: • Modelo de conjuntos difusos (fuzzy set) • Modelo Boolean extendido
Conjuntos Difusos • Consultas y documentos representados por conjuntos de téminos índices. • La vaguedad es modelada como un conjunto difuso: • cada término es asociado con un conjunto difuso • cada documento tiene un grado de membresía en este conjunto difuso • Esta interpretación da el fundamento para muchos modelos de IR basados en teoría difusa. • Aquí se presenta el modelo de Ogawa, Morita, and Kobayashi (1991)
Conjuntos Difusos • La teoría difusa modela clases cuyos límites no están bien definidos. • La idea clave es introducir la noción de grado de membresía asociado con los elementos de un conjunto. • Este grado de membresía varía entre 0 y 1 y permite modelar la noción de membresía marginal. • Así, membresía es ahora una noción gradual, contraria a la noción binaria del modelo Boolean clásico.
Teoría de Conjuntos Difusos • Definición • Un conjunto difuso A de U es caracterizado por una función de membresía (A,u) : U [0,1], la cual asocia a cada elemento u de U un número (u) en el intervalo [0,1] • Definición • Sean A y B dos conjuntos difusos de U. También, sea ¬A el complemento A. Entonces, • (¬A,u) = 1 - (A,u) • (AB,u) = max((A,u), (B,u)) • (AB,u) = min((A,u), (B,u))
Recuperación de Información Difusa • Conjuntos difusos son modelados basados en un tesaurus • Este tesaurus es construido como sigue: • Sea vec(c) una matriz de correlación term-term • Sea c(i,l) un factor normalizado de correlación para (ki,kl): c(i,l) = n(i,l) ni + nl - n(i,l) • ni: número de docs que contienen a ki • nl: número de docs que contienen a kl • n(i,l): número de docs que contienen a ki y kl • Nosotros ahora tenemos la noción de proximity entre términos índices.
Recuperación de Información Difusa • El factor de correlación c(i,l) puede ser usado para definir membresía de conjuntos difusos para un documento dj como sigue: (i,j) = 1 - (1 - c(i,l)) kl dj • (i,j) : membresía de dj en el conjunto difuso asociado a ki • La expresión anterior computa una suma algebraica sobre todos los términos en el documento dj • Un documento dj pertenece al conjunto difuso para ki, si sus términos están asociados con ki
Recuperación de Información Difusa • (i,j) = 1 - (1 - c(i,l)) kl dj • (i,j) : membresía de documento dj en subconjunto difuso asociado con ki • Si documento dj contiene un término kl que está estrechamente relacionado con ki, entonces • c(i,l) ~ 1 • (i,j) ~ 1 • índice ki es un buen índice difuso para el documento doc
Ka Kb cc2 cc3 cc1 Kc Ejemplo • q = ka (kb kc) • vec(qdnf) = (1,1,1) + (1,1,0) + (1,0,0) = vec(cc1) + vec(cc2) + vec(cc3) • (q,dj) = (cc1+cc2+cc3,j) = 1 - (1 - (a,j) (b,j) (c,j)) * (1 - (a,j) (b,j) (1-(c,j))) * (1 - (a,j) (1-(b,j)) (1-(c,j)))
Ejemplo: q = k1 (k2 k3) Qdnf = (1,1,1) (1,1,0) (1,0,0)
Ejemplo: q = k1 (k2 k3) Qdnf = (1,1,1) (1,1,0) (1,0,0) (q,dj) = (cc1+cc2+cc3,j)= 1 - (1 - (k1,j) (k2,j) (k3,j)) (1 - (k1,j) (k2,j) (1-(k3,j))) *(1 - (k1,j) (1-(k2,j)) (1-(k3,j)))
Ejemplo: q = k1 (k2 k3) Qdnf = (1,1,1) (1,1,0) (1,0,0) (q,dj) = (cc1+cc2+cc3,j)= 1 - (1 - (k1,j) (k2,j) (k3,j)) (1 - (k1,j) (k2,j) (1-(k3,j))) *(1 - (k1,j) (1-(k2,j)) (1-(k3,j))) (k1,dj) = 1, (k2,dj) = 1-(1-c(k2,k1))*(1-c(k2,k3))=0.57, (k3,dj) =1
Recuperación de Información Difusa • Modelos difusos IR han sido discutidos en la literatura de teoría difusa • Experimentos con datos de colecciones de pruebas no son disponibles • Entonces,no es posible compararlos.
Modelo Boolean Extendido • Recuperación Booelan es simple y elegante • Pero, no tiene ranking • Cómo extender el modelo? • interpretar conjunciones y disyunciones en términos de distancias Euclidiana
Modelo Boolean Extendido • Como con el modelo difuso, un ranking puede obtenerse al relajar la condición de membresía de conjunto. • Se extiende el modelo Boolean con nociones de correspondencia parcial (partial matching) y peso de términos • Combina características del modelo Vector con propiedades de algebra Boolean
Idea • El modelo Boolean extendido (Salton, Fox, and Wu, 1983) está basado en una crítica de la premisa básica en algebra Boolean • Sea, • q = kx ky • wxj = fxj * idf(x) asociado con [kx,dj] maxi(idf(i))
2 2 sim(qand,dj) = 1 - sqrt( (1-x) + (1-y) ) 2 qand = kx ky; wxj = x and wyj = y (1,1) ky dj+1 AND y = wyj dj (0,0) x = wxj kx
2 2 sim(qor,dj) = sqrt( x + y ) 2 qor = kx ky; wxj = x and wyj = y (1,1) ky dj+1 OR dj y = wyj (0,0) x = wxj kx
p p p p p p Generalizando la idea • Podemos extender la idea anterior para un espacio Euclideano t-dimensional • Esto puede ser hecho usando p-norms ,la cual extiende la noción de distancia a p-distancia, donde 1 p es un nuevo parámetro • Una consulta conjuntiva generalizada está dada por qor = k1 k2 . . . kt • Una consulta disyuntiva generaliza está dada por qand = k1 k2 . . . kt
1 1 p p Idea Generalizada p p p • sim(qor,dj) = (x1 + x2 + . . . + xm ) m p p p • sim(qand,dj) = 1 - ((1-x1) + (1-x2) + . . . + (1-xm) ) m
1 p Propiedades p p p • sim(qor,dj) = (x1 + x2 + . . . + xm ) m • Si p = 1 entonces (como Vector) • sim(qor,dj) = sim(qand,dj) = x1 + . . . + xm m • Si p = entonces (como Fuzzy) • sim(qor,dj) = max (wxj) • sim(qand,dj) = min (wxj)
2 Propiedades • Variando p, podemos hacer que el modelo se comporte como un vector, como difuso o como un modelo intermedio. • Esto es bastante poderoso • (k1 k2) k3 • k1 y k2 pueden ser usados como en una recuperación vectorial mientras que la presencia de k3 es requerida.
2 1 1 p p Propiedades • q = (k1 k2) k3 • sim(q,dj) = ( (1 - ( (1-x1) + (1-x2) ) ) + x3 ) 2 2 p p p p
Conclusiones • Modelo poderoso • Propiedades interesantes y útiles • Computación compleja • Operación distributiva no se cumple para computación de ranking: • q1 = (k1 k2) k3 • q2 = (k1 k3) (k2 k3) • sim(q1,dj) sim(q2,dj)