Download
1 / 30
360 likes | 649 Views
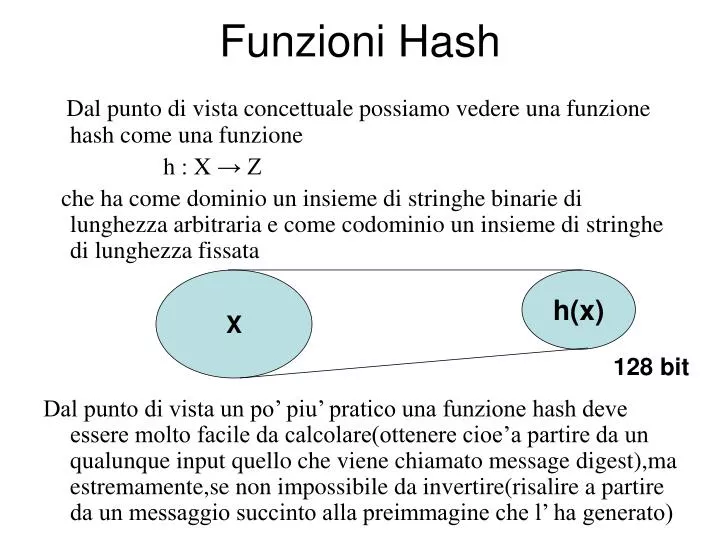
Funzioni Hash. Dal punto di vista concettuale possiamo vedere una funzione hash come una funzione h : X → Z che ha come dominio un insieme di stringhe binarie di lunghezza arbitraria e come codominio un insieme di stringhe di lunghezza fissata

E N D
Funzioni Hash Dal punto di vista concettuale possiamo vedere una funzione hash come una funzione h : X → Z che ha come dominio un insieme di stringhe binarie di lunghezza arbitraria e come codominio un insieme di stringhe di lunghezza fissata Dal punto di vista un po’ piu’ pratico una funzione hash deve essere molto facile da calcolare(ottenere cioe’a partire da un qualunque input quello che viene chiamato message digest),ma estremamente,se non impossibile da invertire(risalire a partire da un messaggio succinto alla preimmagine che l’ ha generato) X h(x) X 128 bit
Questo tipo di funzioni sono utilizzate ad esempio nei meccanismi di firma digitale: le funzioni hash permettono infatti • di ridurre la dimensione della firma • di produrre una firma praticamente unica per ogni documento a cui viene applicata Cifr. Firma Doc Impronta Hash K.pr.
Impronta Cifr. Firma Doc • Al tempo stesso si ha l’opportunita’di controllare l’integrita’/validita’ di un documento firmato Hash Firma K.pr. Doc ? Impronta1 Applico hash a doc = Decifr. Impronta2 Firma K.pubbl.
Caratteristiche di una buona funzione hash La scelta di una funzione hash che permetta di realizzare lo schema di firma visto e’ un’operazione “delicata” in quanto occorre individuare una funzione che abbia caratteristiche tali da non indebolire la sicurezza dello schema di firma,fenomeno che si verifica quando la funzione genera facilmente collisioni. Def. Dati due valori x e x’ e una funzione h si dice che (x,x’)genera una collisione per h se x x’e h(x)=h(x’) Un primo parametro da considerare nell’ utilizzazione di una funzione hash e’ la cardinalita’ del codominio : e’ ovvio infatti che se la cardinalita’fosse troppo piccola sarebbe piuttosto facile trovare collisioni ,mentre un insieme di cardinalita’troppo elevata renderebbe del tutto vana la possibilita’ di riduzione della dimensione delle chiavi che offrono funzioni di questo tipo.
Attraverso il cosiddetto attacco del compleanno e’possibile studiare rigorosamente l’incidenza di questo parametro sulla sicurezza della funzione e individuare valori opportuni da utilizzare nelle funzioni usate nelle applicazioni pratiche. La denominazione di tale attacco deriva dal paradosso del compleanno secondo il quale in un gruppo di 23 persone, scelte a caso,almeno 2 festeggiano il compleanno lo stesso giorno con probabilita’ almeno ½. Questo paradosso puo’ essere sfruttato per valutare il numero di scelte casuali t da fare su un insieme di cardinalita’ n, fissata,per trovare due elementi uguali con probabilita’ anch’essa fissata. Il risultato a cui si e’ giunti e’ che t varia rimanendo pero’ sempre proporzionale a , in particolare il valore calcolato per t e’ . Questo attacco impone un limite inferiore sulla dimensione di Z al fine di avere bassa probabilita’di trovare collisioni.
Se per esempio considerassi una funzione h:X→Z in cui |Z|= e fissassi 0.5 si avrebbe che =1.17 E quindi si potrebbe avere una collisione con probabilita’ ½ scegliendo valori diversi ,un numero non proibitivo da calcolare.Un messaggio di 40 bit e’ dunque molto insicuro e per evitare questo tipo di attacchi si scelgono funzioni che lavorano su un codominio >120 bit.
Altre proprieta’ Da un attenta analisi degli attacchi che possono essere portati alla strategia di firma vista e’ possibile individuare quelle proprieta’ che h deve soddisfare per evitare possibili contraffazioni. • Attacco1: Il nemico conosce il messaggio(x,y)in cui inviato da un certo utente. Allora si calcola z=h(x),e cerca di trovare un x’ x tale che h(x’)=h(x),se ci riesce puo’ costruire la coppia (x’,y)che e’ una contraffazione. Per prevenire questo attacco la funzione deve essere debolmente priva di collisioni. Def. Una funzione h si dicedebolmente priva di collisioni se dato un messaggio x, e’computazionalmente inammissibile trovare un messaggio x’t.c.x x’ e h(x)=h(x’). X y
X X’ • Attacco2: il nemico cerca due messaggi x,x’,diversi, tali che h(x)=h(x’): Successivamente persuade l’utente a firmare h(x)=sigk(h(x)).In tal caso la coppia (x’,y)e’ una contraffazione.Per evitare cio’ la funzione hash deve soddisfare una seconda proprieta’ di sicurezza. Def.Unafunzione h si dice fortemente priva di collisioni se e’computazionalmente inammissibile trovare due massaggi x,x’ t.c. x x’ e h(x)=h(x’). = h(x) h(x’)
Attacco3:il nemico conosce la firma di un messaggio ridotto z e cerca di trovare una x t.c. h(x)=z. Se ci riesce la coppia (x,y) e’ una falsificazione. Per prevenire questo attacco h deve essere one-way: Def. h si dice one-way se,dato un message digest z, e’ computazionalmente inammissibile trovare x t.c. h(x)=z. Riassumendo: • Debolmente priva di collisioni se:dato x e’ computazionalmente difficile trovare un x’ t.c. h(x)=h(x’) • Fortementepriva di collisioni se: e’ computazionalmente difficile trovare 2 messaggi diversi con stesso valore hash • One –way se dato un mess. digest z e’ computazionalmente difficile trovare un messaggio x t.c.h(x)=z E’possibile dimostrare che la proprieta’ di sicurezza forte implica sia la proprieta’di sicurezza debole che quella di one-way.
Funzioni usate in pratica Dal punto di vista teorico esistono moltissime funzioni hash che usano come riferimenti noti problemi teorici le cui soluzioni sono ritenute computazionalmente inamissibili :ad esempio Chaum,Von Heijst e Pfitzmann hanno proposto una funzione la cui sicurezza si basa sulla difficolta’ di calcolo del logaritmo discreto,una funzione di questo tipo pur essendo sicura non e’ abbastanza veloce da essere usata nella pratica.
MD4 E’stata progettata da Ron Rivest nel 1990 ,prende come input un messaggio di lunghezza qualunque e restituisce in output una stringa di 128 bit. gli obbiettivi che Rivest si era proposto nel progetto di MD4 sono: • Sicurezza:la funzione doveva essere fortemente libera da collisioni • Sicurezza diretta:non si doveva basare su problemi teorici difficili compuazionalmente • Velocita’:MD4 doveva essere adatta ad implementazioni software molto veloci • Semplicita’ e compattezza:non doveva usare grandi strutture dati o programmi complicati
Data una stringa di bit x,di lunghezza arbitraria,nel primo passo dell’ algoritmo viene creato a partire da x un array M=M[0] M[1]….. M[N-1] con N multiplo di 16 e tale che |M[i]|=32 bit,in questo modo si ha che |M| e’ un multiplo di 512. L’ array e’ costruito concatenando x con un uno ,e d zeri in cui d e’ un valore tale che |x100……0|=448 mod 512,a questi valori vengono aggiunti 64 bit ,L,che sono la rappresentazione binaria della lunghezza di x.Se |x|> 2^64 allora vengono presi in considerazione solo i primi 64 bit di x.Quindi alla fine di queste operazioni M e’ del tipo: M=x||1||0……0||L E si ha che |M| e’ multiplo di 512. Siccome |M|e’ divisibile per 512 ,scomponendo M in pacchetti da 32 bit abbiamo esattamene k*512/32 =k*16 parole. D zeri
Nella seconda parte dell’ algoritmo vengono costruiti i 128 bit finali • A=67452301 B=efcdab89 Al passo1 vengono inizializzati delle parole di C=98badcfe 32 bit ciascuna che si chiamano registri e sono D=10325476 indicate con le lettere A,B,C,D. 2. for i=0 to N/16-1 do { L’array M viene elaborato a gruppi di 16 parole 3. for j=0 to 15 do alla volta X[j]=M[16i+j] Ad ogni passo del secondo for le successive • AA=A 16 parole di M vengono memorizzate in un • BB=B array X. • CC=C • DD=D • Round1 • Round2 • Round3 • A=A+AA • B=B+BB • C=C+CC • D=D+DD }
Vengono in seguito eseguiti 3 diversi Round nei quali vegono adoperati i seguanti operatori : • Operatori logici AND,OR,XOR e NOT • Operazione di somma su 32 bit • Operazione di shift circolare << • 3 funzioni ausiliarie ,una per round,definite come segue: f(X,Y,Z)=(X Y) (( X) Z) g(X,Y,Z)=(X Y) (X Z) (Y Z) h(X,Y,Z)=X Y Z
Round2 • A=(A+g(B,C,D)+X[0]+5A827999)<<3 • D=(D+g(A,B,C)+X[4]+5A827999)<<5 • C=(C+g(D,A,B)+X[8]+5A827999)<<9 • B=(B+g(C,D,A)+X[12]+5A827999)<<13 • A=(A+g(B,C,D)+X[1]+5A827999)<<3 • D=(D+g(A,B,C)+X[5]+5A827999)<<5 • C=(C+g(D,A,B)+X[9]+5A827999)<<9 • B=(B+g(C,D,A)+X[13]+5A827999)<<13 • A=(A+g(B,C,D)+X[2]+5A827999)<<3 • D=(D+g(A,B,C)+X[6]+5A827999)<<5 • C=(C+g(D,A,B)+X[10]+5A827999)<<9 • B=(B+g(C,D,A)+X[14]+5A827999)<<13 • A=(A+g(B,C,D)+X[3]+5A827999)<<3 • D=(D+g(A,B,C)+X[7]+5A827999)<<5 • C=(C+g(D,A,B)+X[11]+5A827999)<<9 • B=(B+g(C,D,A)+X[15]+5A827999)<<13
Una volta eseguiti i tre Round rimangono gli ultimi 4 passi nei quali vengono introdotte nei registri A,B,C,D le rispettive somme senza riporto tra i valori dei registri e i valori delle variabili temporanee. 1. A=A+AA 2. B=B+BB 3. C=C+CC 4. D=D+DD L’output e’ rappresentato dalla concatenazione dei valori finali assunti dai 4 registri A,B,C,D di 32 bit ciascuno che compongono appunto il Message Digest di 128 bit. Affinche’ tutte le operazioni siano eseguite in modo corretto,il computer su cui viene implementato l’algoritmo MD4 deve avere un’architettura di tipo little-endian(come nei processori Intel80xxx),in cui il bit meno significativo compare all,inizio dell’unita’ di dati.
MD4 e’ stata intensamente studiata e attaccata,fino a che nel 1995 e’ stata trovata una collisione .Gia’dal 1991 pero’ Rivest intravedendo le debolezze di MD4 modifico’il vecchio algoritmo(che pero’venne ancora utilizzato) ,creando una funzione hash piu’ sicura che prese il nome di MD5. MD5 MD5 ha una prima parte in cui espande il messaggio originario costruendo un’array M di dimensione multipla di 512 bit esattamente allo stesso modo di MD4. Anche la seconda parte dell’ algoritmo e’ simile alla versione precedente :vengono inizializzate 4 parole da 32 bit e vengono utilizzati una serie di round (4 per la precisione)in ognuno dei quali e’ usata una funzione diversa che prende in input tre parole di 32 bit e producono un’ unica parola da 32 bit.Nei quattro Round sono anche addizionate delle costanti che sono conservate in una tavola a 64 elementi T[1…64].
L’ i-esimo elemento della tavola e’ : T[i]= 4294967296*|sin(i)| in cui i e’ espresso in radianti e 4294967296 corrisponde al valore decimale di 2^32. In particolare se indichiamo con i il numero di iterazione che stiamo eseguendo,con s uno shift ciclico e con x[k] il pezzo di messaggio che stiamo computando,l’ operazione generica che viene calcolata nei quattro round e’: A=(B+((A+W(B,C,D)+x[k]+T[i]))<<s) Differenze con MD4: • E’ stato aggiunto un quarto round che funziona esattamente come gli altri . • Si usa una costante in ogni round T[i]= 4294967296*|sin(i)| mentre in MD4 si usa solo nei round 2,3 ed e’ fissata in modo indipendente dal passo che si sta eseguendo.
MD5 e’ un algoritmo facile da implementare e rispetto all’ MD4 e’piu’ lento circa del 30%.Per quanto riguarda la sicurezza Rivest ha congetturato che per trovare una collisione sono necessarie 2^64 operazioni mentre per trovare una preimmagine di un dato message digest si ha una difficolta’ dell’ ordine di 2^128 operazioni ,pertanto MD5 puo’ essere ritenuta sicura ed e’ largamente utilizzata.Fino ad ora(dato aggiornato ‘99)sono stati attaccati i singoli round mentre l’algoritmo per intero non e’ ancora stato attaccato. SHS(Secure hash standard) Fu pubblicato sul federal register il 31/1/91 e dal dall’ 11/5/93 e’ stato adottato come standard dallo Stato americano anche se ha subito modifiche nel Luglio ‘94.L’SHS e’ piu’ lento sia di MD4 che di MD5 ma e’ considerato piu’ sicuro. Questo standard fornisce le specifiche di un algoritmo detto SHA(Secure hash algoritm)che computa una rappresentazione ridotta di un messaggio.
In particolare quando riceve un input di dimensione qualsiasi ma minore di 2^64 SHA produce un output di 160 bit. SHS ricalca il funzionamento di MD4 con alcune lampanti differenze:in primo luogo l’output e’ su 160 bit invece che su 128 ,questo perche’ viene utilizzato un quinto registro a 32 bit (a differenza dei quattro di MD4 eMD5).Inoltre lo standard SHS e’ stato progettato per essere implementato su architetture di tipo big-endian. Lo SHA processa blocchi di 512 bit quindi come nel caso di MD4 eMD5 il messaggio viene inizialmente espanso in modo da ottenere blocchi da 16* n parole da 32 bit,che possiamo vedere come una sequenza di blocchi M(1) M(2)… M(n)in cui ogni blocco contiene 16 parole,l’algoritmo lavora infatti su 16 parole ad ogni passo.
Nello SHA intervengono alcune funzioni logiche Ogni funzione ,opera su 3 parole da 32 bit B,C,D e restituisce un’unica parola da 32 bit.In particolare e’ definita come segue : Viene anche utilizzata una sequenza di costanti se 0≤t≤19 se 20≤t≤39 se 40≤t≤59 se 60≤t≤79
Un secondo passo dell’algoritmo consiste nell’ espandere le 16 parole di turno in 80 parole .L’ espansione avviene considerando le 16 parole del messaggio originario x,che chiameremo X[0] X[1]…. X[15] e aggiungendo ad esse le 64 parole computate da una relazione di ricorrenza nel seguente modo : con 16≤y≤79.Il risultato di questa relazione e’ che ognuna delle parole X[16],….X[79] rappresenta lo xor di un predeterminato sottoinsieme delle parole X[0],..X[15]. Durante la computazione ci serviamo di 2 buffer ulteriori che vengono inizializzati con 5 parole da 32 bit ,in particolare il secondo buffer sara’ quello che fornira’ i 160 bit del messaggio ridotto come combinazione delle 80 parole dicui sopra.
Funzione Tiger E’una funzione progettata nel 96’ da Ross Andersson dell’universita’ di Cambridge e da Eli Biham dell’isti- tuto tecnico di Haifa ,i suoi creatori la pubblicizzano sostenendo che le recenti collisioni trovate per funzioni appartenenti a determinate famiglie hash(come per MD4 nel ’95 o ancora prima per Snefru nel ’90)mettono in dubbio la sicurezza degli altri componenti di queste famiglie. Inoltre dal punto di vista delle prestazioni quasi tutte le funzioni “vecchie ”erano progettate per processori che lavoravano a 32 bit,quindi le suddette funzioni non possono funzionare efficientemente sui piu’ moderni processori a 64 bit.
A partire da queste considerazioni i progettisti hanno voluto creare una funzione: • Che fosse piu’ sicura • Che potesse girare in modo ottimale su macchine a 64 bit e non troppo lentamente su quelle a 32 bit.
Le computazioni effettuate da Tiger sono su parole da 64bit in architetture little-endian. Vengono usati 3 registri a 64 bit che chiamiamo A,B,C inizializzati con i seguenti valori A=0x0123456789abcdef B=0xfedcba9876543210 C=0xf096a5b4c3b2e187 Ogni blocco di 512 bit e’ suddiviso in 8 parole da 64 bit x0,x1….x7 e le varie computazioni si preoccuperanno di calcolare i nuovi valori assunti dai registri a partire da quelli vecchi, queste computazioni si possono riassumere nel seguente frammento: save_ABC pass(A,B,C,5) key_schedule pass(C,A,B,7) key_schedule pass(B,C,A,9) feedforward
In cui : • save_ABC salva il valore corrente dei registri AA=A BB=B CC=C • Pass(A,B,C,mul) equivale a round(A,B,C,x0, mul) round(B,C,A,x1, mul) round(C,A,B,x2, mul) round(A,B,C,x3, mul) round(B,C,A,x4, mul) round(C,A,B,x5, mul) round(A,B,C,x6, mul) round(B,C,A,x7,mul)
Dove round(A,B,C,x,mul) Dove c_i e’ l’i-esimo bit di c,T1….T4 sono valori di 8 bytes pre-calcolati in modo abbastanza complicato
Key_schedule e: X0=X0-X7 xor 0xA5A5A5A5A5A5A5A5 X1=X1 xor X0 X2=X2+X1 X3=X3-X2 xor (X1<<19) X4=X4 xor X3 X5=X5 + X4 X6=X6 – X5 xor (X4>>23) X7=X7 xor X6 X0=X0 + X7 X1=X1 – X0 xor (X7<<19) X2=X2 xor X1 X3=X3 + X2 X4=X4 – X3 xor(X2>>23) X5=X5 xor X4 X6=X6 + X5 X7=X7 – X6 xor 0x0123456789abcdef
Feedforward A=A xor AA B=B - BB C=C + CC L’output e’ dato dai valori finali dei registri A,B,C.Se implementata in modo corretto questa funzione raggiunge velocita’ molto elevate (pari a quella dello SHA su macchine a 32 bit mentre e’ circa 3 volte piu’ veloce su quelle a 64 bit). Siccome l’ output e’ ottenuto come concatenazione di 3 registri a 64 bit e’ su 192 bit ma e’ reso compatibile con le funzioni hash gia’ esistenti semplicemente troncando a 128 o a 160 bit.
Riferimenti • FIPS PUB 180-1 Secure Hash Standard ,Aprile ’95 • Rivest,R.,The MD4 Message Digest Algorithm,RFC 1320 Aprile ‘92 • Rivest,R.,The MD5 Message Digest Algorithm,RFC 1321 Aprile ‘92 Per ulteriori informazioni sulla funzione Tiger consultare le pagine ai seguenti URL • http://www.cs.technion.ac.il/~biham/ • http://www.cl.cam.ac.uk/users/rja14/.